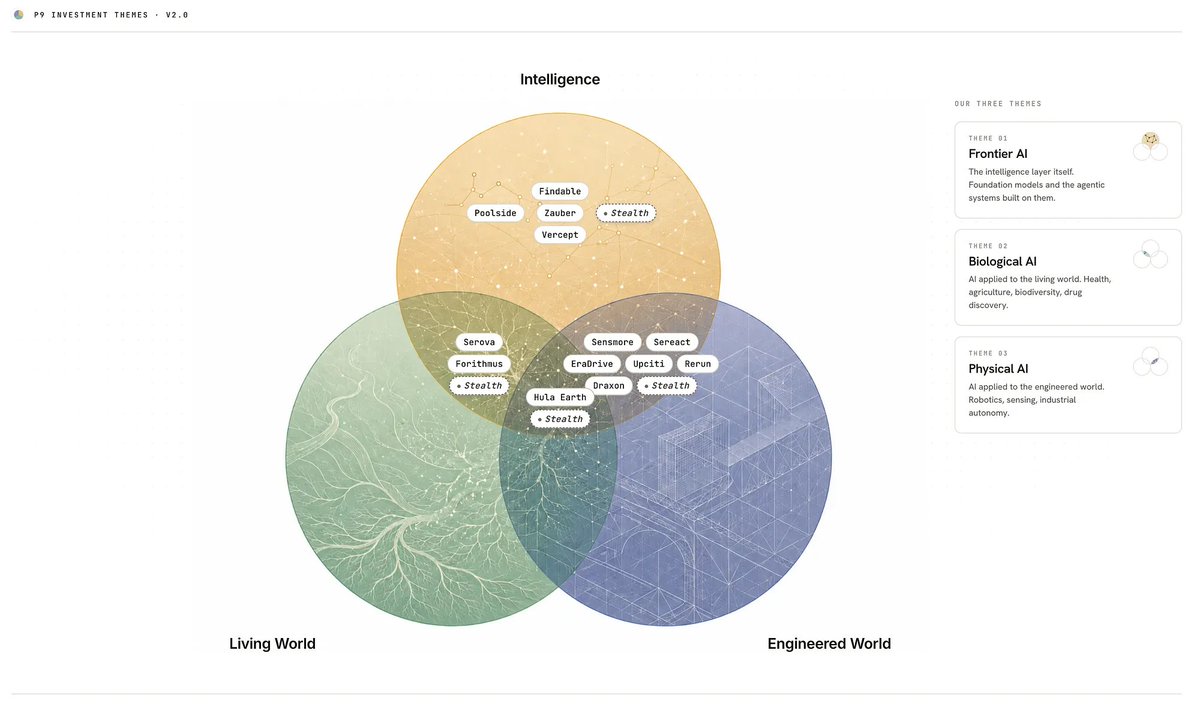
Fin CEO @eoghan explains why perfect customer experience is now possible, and how we believe a single, seamless customer agent is the only way to deliver it
This is what you should have built @Pitch. No API, CLI or MCP in the age of Agents is failure mode. You had the best possible opportunity, but built a lot of fluff instead. Don’t know if your still involved @christianreber ?
I can't fathom why using OpenClaw with claude-cli on a MAX plan with 4% plan usage weekly limit should not be allowed --why should you care what I use my tokens for? @bcherny@steipete@AnthropicAI
📈 Brad Gerstner on the insane revenue numbers coming out of Anthropic:
"We had a $6 billion month out of Anthropic in February...It was only a 28-day month.
That's more revenue than the annual revenue of Databricks and Snowflake – that are two of the greatest software companies of all time after 12 years, right?
They could do, in the first four or five months of this year, the total revenue of SpaceX this year."
–@altcap on @theallinpod
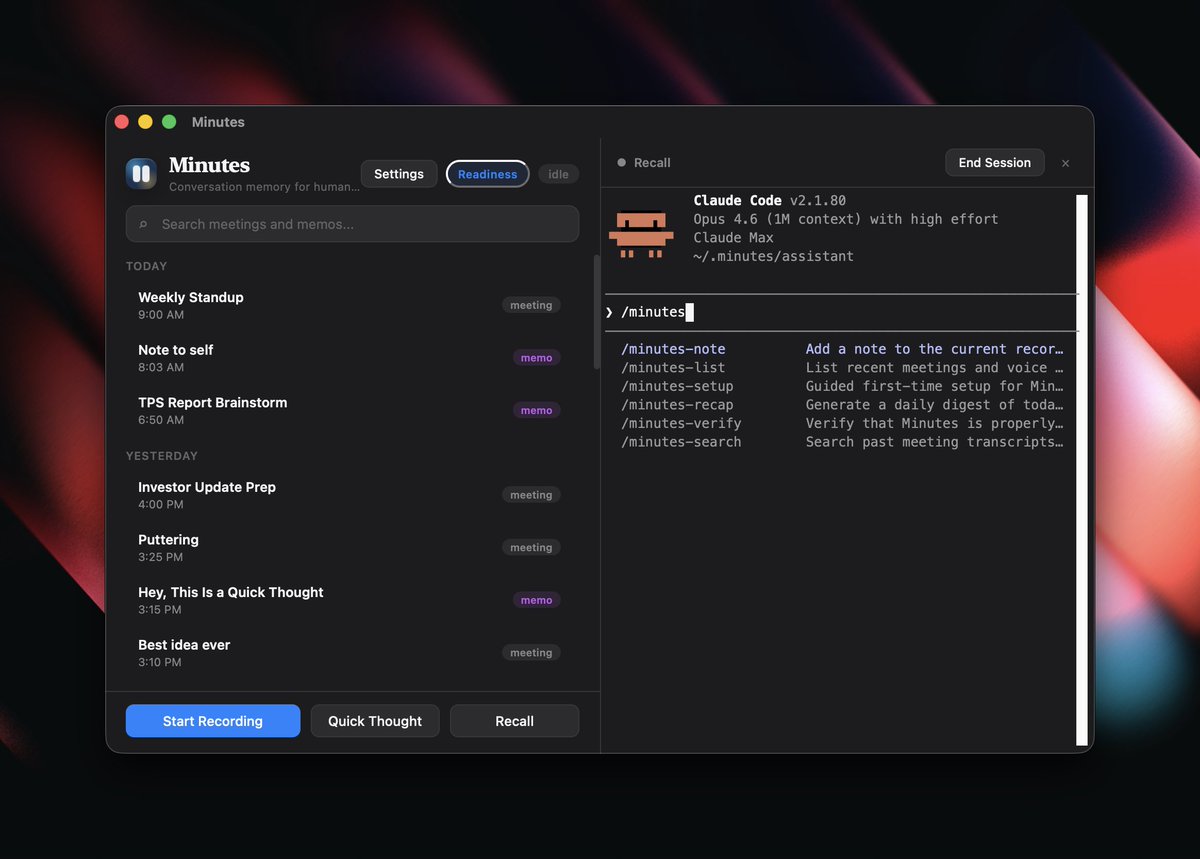
Now paying Granola $18/mo to upload my meeting audio to their servers. So I built my own thing. It's 7 MB. Everything runs locally.
Works with @tobi's QMD for super fast search, PARA method second brain setup for organized people, projects, entities, @obisidan, CLI, claude code, codex, Claude Desktop.
Before a call with Biff it pulls your last 12 conversations, shows you pricing came up 5 times in 2 weeks, and reminds you that you owe Biff a doc from Friday. After the call it asks if you got what you came for.
You just ask "what did Biff say about pricing last week" and it pulls from your transcripts. No API key needed, use your existing subs.
The meeting prep feature came from messing around with @garrytan's gstack skills. His /office-hours pattern forces you to be specific instead of accepting vague answers. I stole that idea and applied it to meeting prep and post-meeting debrief.
It's called Minutes. Rust, whisper.cpp, Tauri. MIT licensed. First real release on github.
@jainarvind Thanks for sharing! Very much agree:
1. Context access (basic problem for most verticals)
2. Context quality
We’re building this for real estate.
Doing this well requires more than just querying a database. Historically we relied on the expertise of the data owner to know which metric to pull. Now it requires an agent understanding which metrics actually matter and selecting the right ones as they evolve over time. At Glean, when we analyze structured data from systems like Salesforce or Databricks, we look at usage patterns, who produced the metric, and how it’s already being used to infer the likely canonical metric. After all, this is fundamentally a search problem.
That said, I think one thing missing from the discussion is that the "data agent" is usually just one component of a larger workflow.
Take a prompt like: “Analyze my sales pipeline to understand what’s at risk.” Yes, some of that analysis comes from structured data in systems like Databricks or Snowflake. But a large part of understanding “risk” actually lives in unstructured data. Things like team conversations, comments on documents or spreadsheets, and notes from forecasting review meetings. That's why the context layer can’t just operate on structured data.
Context graphs are rising in importance because they recognize that agents need a new kind of data structure to understand how work actually happens and how decisions get made. That's what we're working on here at Glean too.
Excited for the OpenClaw Meet & Build event that we're hosting in Berlin on Friday!
If you've signed up and haven't heard back yet: We're sorry. We have capacity for 250 people and we're at 500+ signups and counting. We’re doing our best to put together a diverse group of builders and will confirm spots as soon as possible.
https://t.co/Y06Zew5QiI