This paper makes long-context attention cheaper and faster by letting each token use only the query heads it needs.
Reached about 1.7 to 1.8 times faster prefill when context length became large.
Standard attention makes every token run through every attention head, even when some heads are not useful for that token.
The paper’s idea, called Grouped Query Experts, keeps the normal key and value cache from grouped-query attention but routes each token to only a few query-head experts.
Grouped Query Experts sits on top of grouped-query attention, the trick many long-context models already use to reduce key-value cache cost.
This is like giving the model many possible attention patterns, while making each token pay for only the small set that seems useful.
The authors trained 250M-parameter models on 30B tokens and compared the method with a normal grouped-query attention baseline.
The best version matched the baseline’s average accuracy, 56.04 versus 55.86, while using 9 of 16 query-attention computations.
shows that attention can be made sparse inside grouped-query attention without hurting quality, but only when the router gets a strong learning signal and one shared head stays always on.
----
Link – arxiv. org/abs/2606.20945
Title: "Grouped Query Experts: Mixture-of-Experts on GQA Self-Attention"
This paper makes long-context attention cheaper and faster by letting each token use only the query heads it needs.
Reached about 1.7 to 1.8 times faster prefill when context length became large.
Standard attention makes every token run through every attention head, even when some heads are not useful for that token.
The paper’s idea, called Grouped Query Experts, keeps the normal key and value cache from grouped-query attention but routes each token to only a few query-head experts.
Grouped Query Experts sits on top of grouped-query attention, the trick many long-context models already use to reduce key-value cache cost.
This is like giving the model many possible attention patterns, while making each token pay for only the small set that seems useful.
The authors trained 250M-parameter models on 30B tokens and compared the method with a normal grouped-query attention baseline.
The best version matched the baseline’s average accuracy, 56.04 versus 55.86, while using 9 of 16 query-attention computations.
shows that attention can be made sparse inside grouped-query attention without hurting quality, but only when the router gets a strong learning signal and one shared head stays always on.
----
Link – arxiv. org/abs/2606.20945
Title: "Grouped Query Experts: Mixture-of-Experts on GQA Self-Attention"
What if Transformers didn't have to compute every attention head for every token?
Our team presents Grouped Query Experts (GQE): Mixture-of-Experts on GQA Self-Attention: https://t.co/7MNzwXL8Wo
Excited to share our latest work from @FrontiersMind 🚀
We published Grouped Query Experts (GQE)- Mixture-of-Experts applied directly to GQA self-attention heads.
MoE in MLP blocks saves compute by activating only k experts per token. We applied a similar idea to self-attention - built on top of GQA, each token now activates only k heads out of all heads, making attention sparse.
→ 1.7–1.8× faster prefill at long contexts
→ No accuracy loss
→ 25–75% fewer active heads per token depending on sparsity chosen
Paper: https://t.co/czf3Fpjr1h
HF: https://t.co/cWwcQyvMkK
#LLM #MoE #Transformer #SelfAttention
Had an amazing session in collaboration with @lossfunk last week where our co-founder @akanyaani shared insights on how we pre-train efficient models like Nandi from scratch !
A big thanks to everyone who showed up for the event
The internet decentralized information. We're building @FrontiersMind to decentralize access to frontier AI.
This week was a reminder: just days after launch, access to Fable 5 was suspended for users outside the US.
#DecentralizedAI#SovereignAI#FrontiersAI
Today, we're releasing Nandi-Mini-V1.1-600M-Intermediate-Checkpoint-400GT
Try it now: https://t.co/4iAhbk4AxV
This is an intermediate checkpoint of the upcoming Nandi-Mini-V1.1-600M model family, trained on 400B+ tokens
We’ll be releasing the final model & checkpoint next week
Join us as Harshvardhan Pratap & Abhay Kumar dive into the future of AI & Core Concepts !!
Building beyond just APIs !!
Register here: https://t.co/p5qymRQsKv
Excited to collaborate with @mlopscommunity for a tech meetup in Bangalore on 6th June at HustleHub, HSR Layout
We’ll present how Nandi Models achieved 50% lower KV cache memory usage and improved transformer efficiency
Register here: https://t.co/p5qymRQsKv
Nandi-Mini-150M-GuardRails: https://t.co/pqjWKMkvaA
Nandi-Mini-600M-GuardRails: https://t.co/mneXcyLuGs
We have just open-sourced the GuardRails models from the Nandi-Mini series.
They are small yet quite capable of classifying the safety of user prompts and model responses.
Nandi-mini-150M achieves the lowest average fertility score across 10 Indic languages + English, while being 10X–1000X smaller than competing models
At FrontiersMind, we are building highly efficient small and medium language models, optimizing every part of the transformer stack
50K+ downloads across our Nandi-Mini-150M series🚀
What started as an effort to build efficient, capable small language models is now being used, downloaded, and supported.
Thank you for every download, contribution, benchmark, feedback message, and conversation along the way❤️
🚀 Introducing Nandi-Mini-150M-Tool-Calling : https://t.co/pFUnJuU3j4
A lightweight, fast, and efficient model built specifically for single-turn tool calling.
🔹 Designed for precision in structured tool usage
🔹 Optimized for low latency and minimal compute
Nandi-Mini-150M-Instruct is here: https://t.co/64X5AlF9HF
We’ve released the instruct version of Nandi-Mini-150M, a small model optimized for better instruction-following.
Huge thanks to the community for the support on the base model, it really helped us move fast 💛
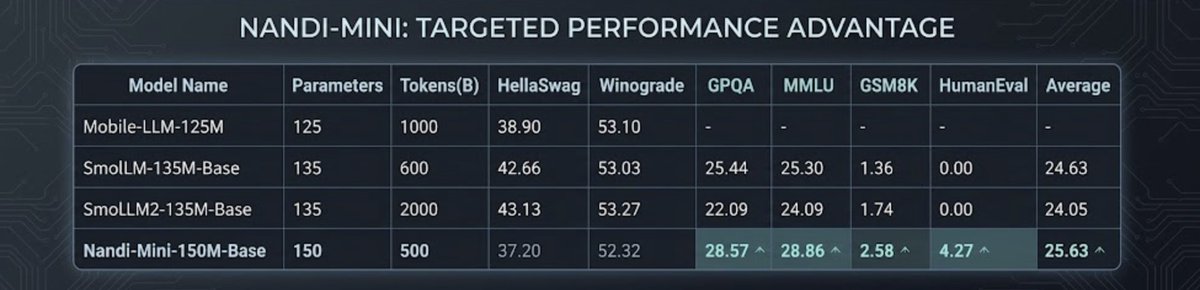
Introducing Nandi-Mini-150M 🔥
A compact multilingual LLM trained on 525B tokens across 11 languages (English + Indic).
Built for real-world use, not just benchmarks.
150M params, edge-optimized, memory-efficient, strong for fine-tuning.
Try it: https://t.co/RLnCEsHL9S