@paulg a quote is circulating on your obsrvation about AI generated emails. There is a debate about it, but what everyone is missing is you are challenging people to think beyond genAI, when everyone starts sounding the same, humans crave 4 differentiation aka >personal context
“I will build a RAG system for my company in one week” - that is what I often hear nowadays from recently turned AI experts.
Unfortunately, building a 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗴𝗿𝗮𝗱𝗲 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗔𝘂𝗴𝗺𝗲𝗻𝘁𝗲𝗱 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 (𝗥𝗔𝗚) 𝗯𝗮𝘀𝗲𝗱 𝗔𝗜 𝘀𝘆𝘀𝘁𝗲𝗺 is a challenging task.
Here are some of the moving parts in the RAG based systems that you will need to take care of and continuously tune in order to achieve desired results:
𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹:
𝘍 ) Chunking - how do you chunk the data that you will use for external context.
- Small, Large chunks.
- Sliding or tumbling window for chunking.
- Retrieve parent or linked chunks when searching or just use originally retrieved data.
𝘊 ) Choosing the embedding model to embed and query and external context to/from the latent space. Considering Contextual embeddings.
𝘋 ) Vector Database.
- Which Database to choose.
- Where to host.
- What metadata to store together with embeddings.
- Indexing strategy.
𝘌 ) Vector Search
- Choice of similarity measure.
- Choosing the query path - metadata first vs. ANN first.
- Hybrid search.
𝘎 ) Heuristics - business rules applied to your retrieval procedure.
- Time importance.
- Reranking.
- Duplicate context (diversity ranking).
- Source retrieval.
- Conditional document preprocessing.
𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻:
𝘈 ) LLM - Choosing the right Large Language Model to power your application.
✅ It is becoming less of a headache the further we are into the LLM craze. The performance of available LLMs are converging, both open source and proprietary. The main choice nowadays is around using a proprietary model or self-hosting.
𝘉 ) Prompt Engineering - having context available for usage in your prompts does not free you from the hard work of engineering the prompts. You will still need to align the system to produce outputs that you desire and prevent jailbreak scenarios.
And let’s not forget the less popular part:
𝘏) Observing, Evaluating, Monitoring and Securing your application in production!
What other pieces of the system am I missing? Let me know in the comments 👇
Every AI-native company needs a manual mode.
Not as a backup plan. As a leadership discipline.
If your team cannot reason through the work without the machine, they may no longer understand the work.
I just broke down the anatomy of the perfect SOUL. md file for AI agents.
SOUL. md is the identity file every AI agent reads before it does anything else.
Without it, your agent is just a raw LLM with no memory, no personality, and no boundaries.
With it, your agent knows who it is, how to talk, what to refuse, and which tools to use.
Here are the 9 sections that make a SOUL. md actually work:
→ Identity (who the agent IS, not what it does)
→ Values (decision-making when rules don't cover it)
→ Communication Style (tone, length, formality)
→ Expertise (specific tools and domains, not vague "knows things")
→ Boundaries (the immune system. Holds even under pressure)
→ Workflow (step-by-step process for every task)
→ Tool Usage (WHEN and HOW, not just which ones exist)
→ Memory Policy (what persists, what gets wiped)
→ Example Interactions (one good example beats 10 abstract rules)
Most people write "Be helpful and professional."
That describes nothing. Every AI already tries to do that.
The agents that actually work have SOUL. md files with real opinions, specific limits, and concrete examples of what "good" looks like.
A strong SOUL. md is 200-500 words. Shorter = sharper agent.
Save this. You'll need it the moment you build your first agent.
Spec-driven development became the default AI coding architecture
67-source academic review all agreed
5 repos defining it + 1 saying they're all wrong:
spec-kit · BMAD · Open-spec · GSD · superpowers and Pocock's skills
How to choose? or should adapt a feature from each one?
Everyone is fine-tuning LLMs.
Almost nobody understands what is actually being updated inside the model.
Here are 5 techniques that change how you think about model adaptation, and what each one is actually doing to the weights:
1./ LoRA - Learn the update, not the weights
The pretrained weight W is frozen. Completely untouched.
Instead of updating W directly, two small matrices are trained =>
A ∈ ℝʳˣᵈ and B ∈ ℝᵈˣʳ, where r ≪ d
The weight update is: ΔW = BA Effective weight: W' = W + BA
The entire adaptation happens in a tiny low-rank space. W never changes.
2./ LoRA-FA - What if we freeze even more?
Same structure as LoRA. One change.
A is frozen alongside W. Only B is trained. Effective weight: W' = W + BA (A is fixed)
Half the trainable matrices of LoRA. Same core idea. Fewer parameters.
3./ VeRA - What if the matrices don't need to be learned at all?
This is where it gets interesting.
A and B are both frozen, and randomly initialized. What gets trained are just two tiny scaling vectors =>
b ∈ ℝʳ and d ∈ ℝʳ
Instead of learning the low-rank matrices themselves, VeRA keeps them frozen and learns small scaling vectors that modulate their contribution.
Initialization => b = 0, d = 1
You're not learning matrices. You're learning how to scale them.
One of the most parameter-efficient techniques on this list.
4./ Delta-LoRA - What if W itself learns from the low-rank updates?
This one is fundamentally different.
Unlike standard LoRA, the base weight W is not fully frozen. It is updated through low-rank delta propagation at every step =>
W^(t+1) = W^t + c(B_(t+1)A_(t+1) − B_t A_t)
Where c is a scaling factor.
A and B are trainable. W evolves, but guided entirely by low-rank changes.
5./ LoRA+ - Same structure. Smarter learning rates.
Identical to LoRA, freeze W, train A and B.
One change => B is assigned a larger learning rate than A. η_B > η_A
A ← A − η_A · ∂J/∂A B ← B − η_B · ∂J/∂B
A small optimization change that can make LoRA training more effective.
The core idea running through all five:
You do not always need full fine-tuning to adapt a model.
LoRA updates two matrices.
LoRA-FA updates one.
LoRA+ updates two at different speeds.
Delta-LoRA lets W evolve - guided by low-rank deltas. VeRA updates two vectors.
Same goal. Five different answers to the same question:
=> What is the minimum we actually need to learn?
That is the core idea behind parameter-efficient fine-tuning.
And now you know what is actually happening inside the model.
HARVARD RELEASED A 65-MIN MASTERCLASS ON GIT & GITHUB BECAUSE VIBE-CODERS STILL DON'T KNOW HOW TO COMMIT
1 hour and 5 minutes of raw, no-nonsense version control architecture from the creators of CS50.
-> The moment you watch it, you realize why most modern developers are breaking their production branches.
Every tier-1 tech company is now filtering candidates who can't handle basic merge conflicts.
Git isn't a "nice-to-know" anymore -> it's compliance.
Your AI can write the code.
That wasn't the problem.
The problem is you don't know how to merge it without breaking the repo.
Don’t forget to bookmark it.
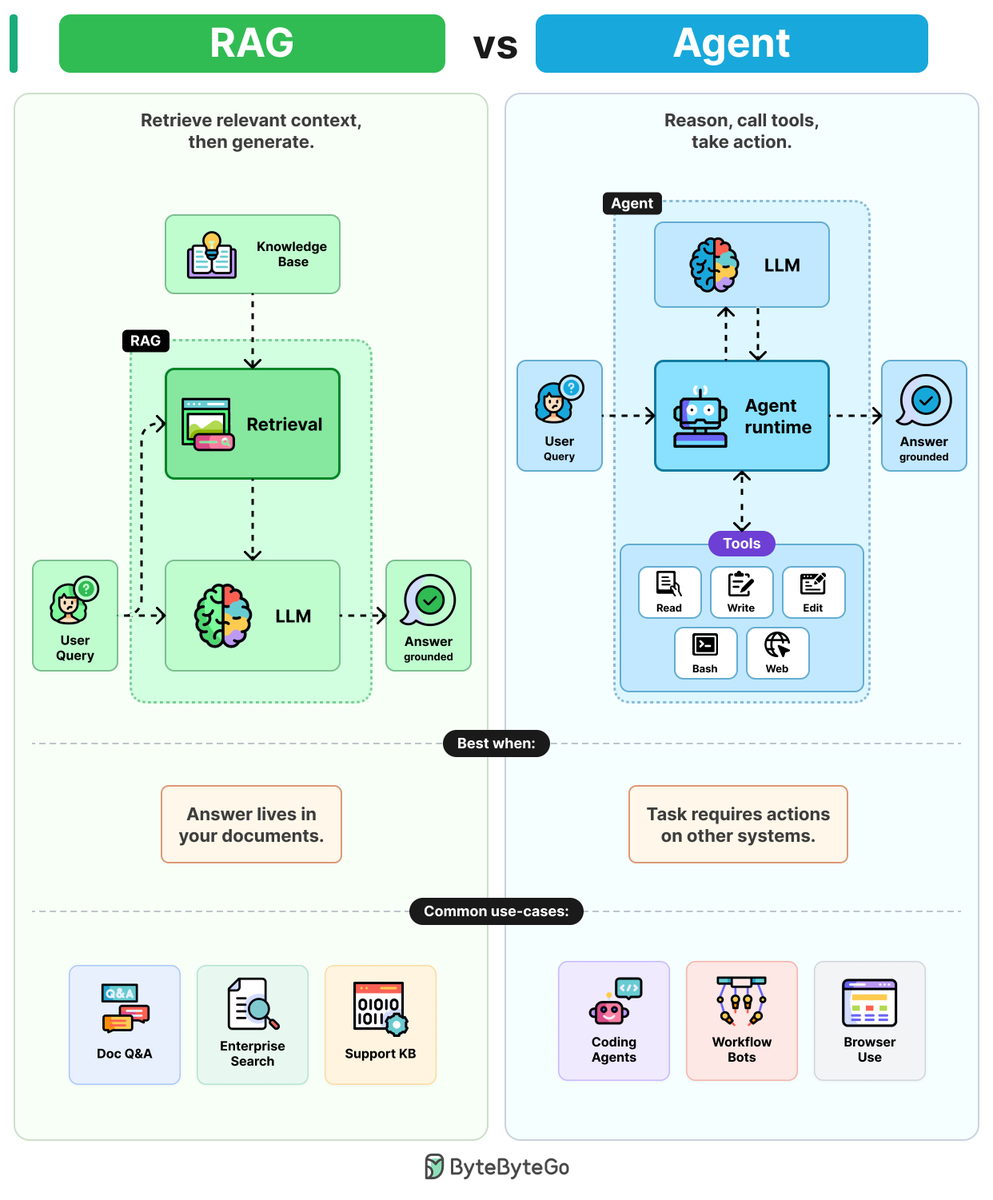
RAGs vs Agents
Ask an LLM about your company's data and it will guess. The two patterns that fix this are RAG and agents, and they solve different problems.
RAGs: RAGs combine LLMs with retrieval to ground answers in 4 steps.
Step 1: The user query is embedded and sent to a retrieval step.
Step 2: Retrieval pulls the most relevant chunks from a knowledge base (PDFs, wikis, etc.)
Step 3: Those chunks are pasted into the prompt as context.
Step 4: The LLM writes the answer, grounded in the retrieved text.
One retrieval. One generation. Cheap, predictable, and easy to debug.
Agents: Agents wrap LLMs in a reasoning loop with tools to take action.
Step 1: The user query goes into the agent runtime. A reasoning loop wrapped around an LLM.
Step 2: The LLM reads the goal and picks a tool (Read, Write, Edit, Bash, etc.)
Step 3: The runtime executes the tool and feeds the result back to the LLM.
Step 4: The LLM reasons again, picks the next tool, and loops until the task is done.
More flexible. More tokens. Harder to debug because errors drift across steps.
The rule of thumb: Use RAG when the answer lives in your documents. Use an agent when the answer requires action on other systems.
Over to you: When do you prefer RAG over agent?