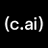Welcome to Gemini 3.5 Flash, our most powerful model to date. It pushes the frontier of intelligence, speed, and cost putting 3.5 Flash in a class of its own.
We spent the last 6 months making sure Flash is great for real world use cases. It's available everywhere now!
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video.
It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
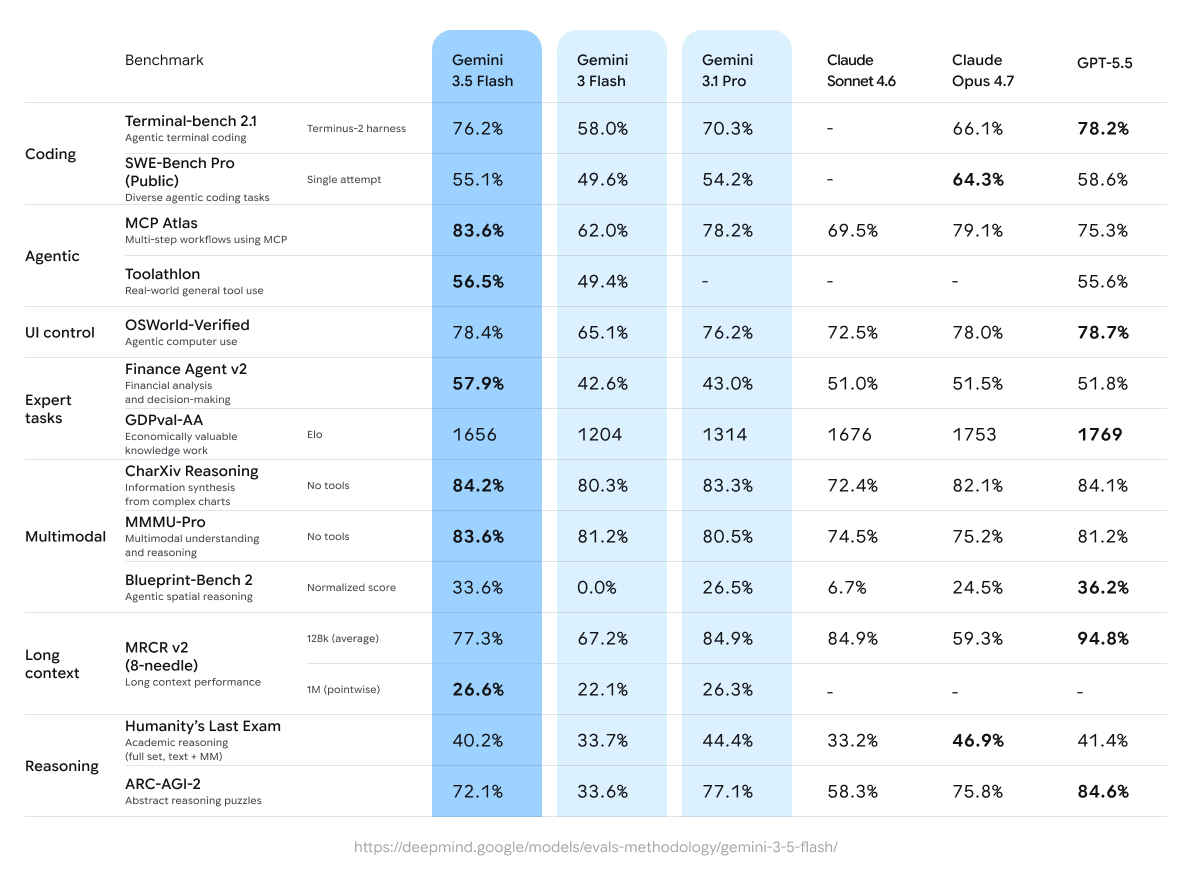
Last week we upgraded Gemini 3 Deep Think. Today, we’re shipping the core intelligence that makes those breakthroughs possible: Gemini 3.1 Pro.
A noticeably smarter, more capable baseline for your hardest challenges.
Available now: https://t.co/Srm2Ec7OWJ
An updated Gemini 3 Deep Think is out today:
📈 Achieves SOTA on ARC-AGI-2, MMMU-Pro, and HLE.
🥇Gold-medal level on Physics & Chemistry Olympiads.
It turns out the best way to solve hard problems is still to think about them. Read more: https://t.co/PMmuyRq90B
Introducing Gemini 3 ✨
It’s the best model in the world for multimodal understanding, and our most powerful agentic + vibe coding model yet. Gemini 3 can bring any idea to life, quickly grasping context and intent so you can get what you need with less prompting.
Find Gemini 3 Pro rolling out today in the @Geminiapp and AI Mode in Search. For developers, build with it now in @GoogleAIStudio and Vertex AI.
Excited for you to try it!
Gemini Live’s new model updates are now available on the @GeminiApp on Android and iOS. Conversations are more adaptive and expressive, opening up new ways to learn and practice skills. Here are five ways you can try out these new updates:
-Tailor your learning. Ask Gemini to explain a topic in your lesson plan and then say, "Okay, speed up," to get a crash course on the way to your next class.
-You can now get tailored practice when learning a new language. Ask Gemini to quiz you on multiples of 10 in Korean, or practice casual greetings in Spanish. This allows you to gain real-world speaking experience in a low-risk setting.
-Practice for your next big moment, like job interviews, or prepare for tough conversations with Gemini's ability to respond to your situation.
-Hear stories come to life. Try asking Gemini to tell you about the Roman empire from the perspective of Julius Caesar himself.
-Liven things up by asking Gemini to speak in a fun accent, like a cowboy accent when brainstorming ideas for a rodeo-themed birthday party.
AI Chat just got real.
Introducing Character Calls, the latest addition to our suite of Voice features. Talk with AI Characters, just like you would talk on the phone. Whether it's polishing your language skills, acing interviews, adding zest to RPGs, or crafting epic storylines, Characters are ready to answer your call.
Try it now on our mobile app: https://t.co/Mw8n4y8WCJ #CharacterCalls
Give your Characters a Voice! Choose from thousands of Voices or create your own. Now available to everyone today for free.
Get the app: https://t.co/wKqSpHyUWN
I'm excited to share that our paper has been accepted at #ICASSP2024:
Improving ASR Contextual Biasing with Guided Attention
Jiyang Tang, Kwangyoun Kim, Suwon Shon, Felix Wu @fw4cs, Prashant Sridhar, Shinji Watanabe @shinjiw_at_cmu
(Will add an Arxiv link soon :)
(1/3)
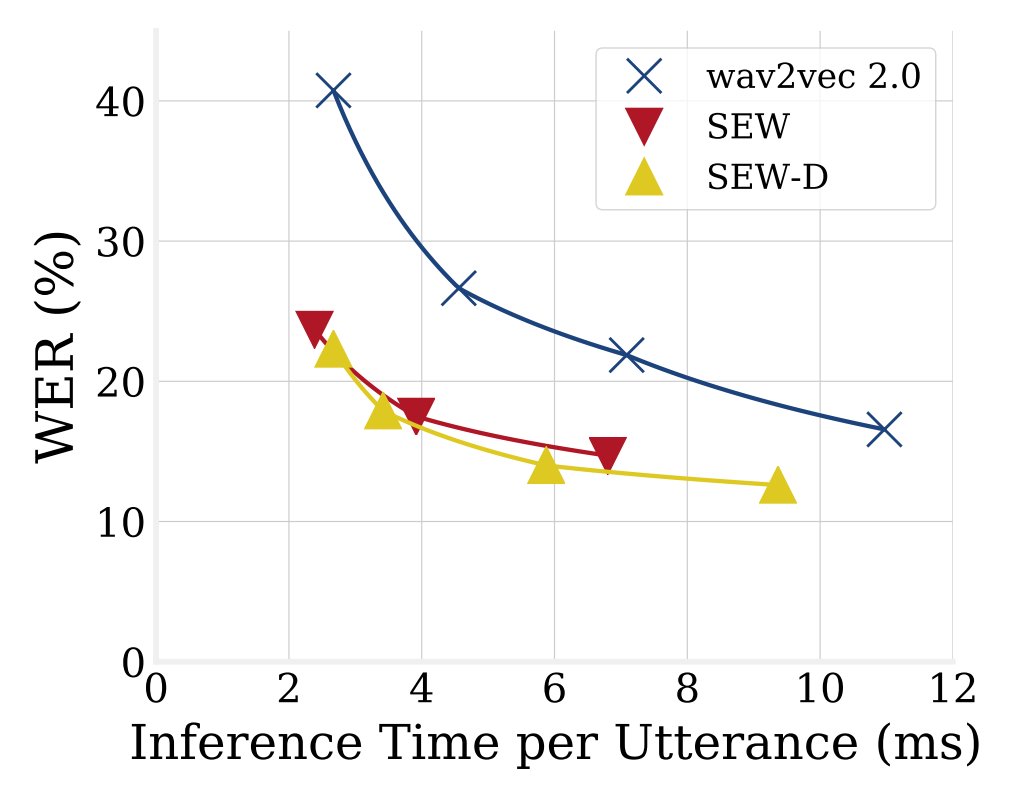
🚀 Squeezed and Efficient Wav2Vec is here!⌛️
These speech models by @asapp are faster and require less memory without sacrificing recognition quality 🔥
Try them out in 🤗transformers 4.12!
SEW: https://t.co/QcmN3cwmKy
SEW-D: https://t.co/JIzX3dSSsp
Our Squeezed and Efficient Wav2vec (SEW and SEW-D) models are now in @huggingface's transformers 4.12! Many thanks to @anton_lozhkov and the huggingface team for their help!
Please check out our paper for more details of the models: https://t.co/pfzeNeefXP
Are Pre-trained Convolutions Better than Pre-trained Transformers?
pdf: https://t.co/8L06XiPM1C
abs: https://t.co/gIAq2Od5GA
experimental results show that convolutions can outperform Transformers in both pretrain and non-pre-trained setups
Fine-tuning BERT has become popular for #NLProc tasks, but it often remains unstable when using large variants on small datasets. Latest research from @fw4cs accepted at #ICLR2021 increases this stability to reduce deployment costs and energy footprint:
https://t.co/Cmh7HrBlL5