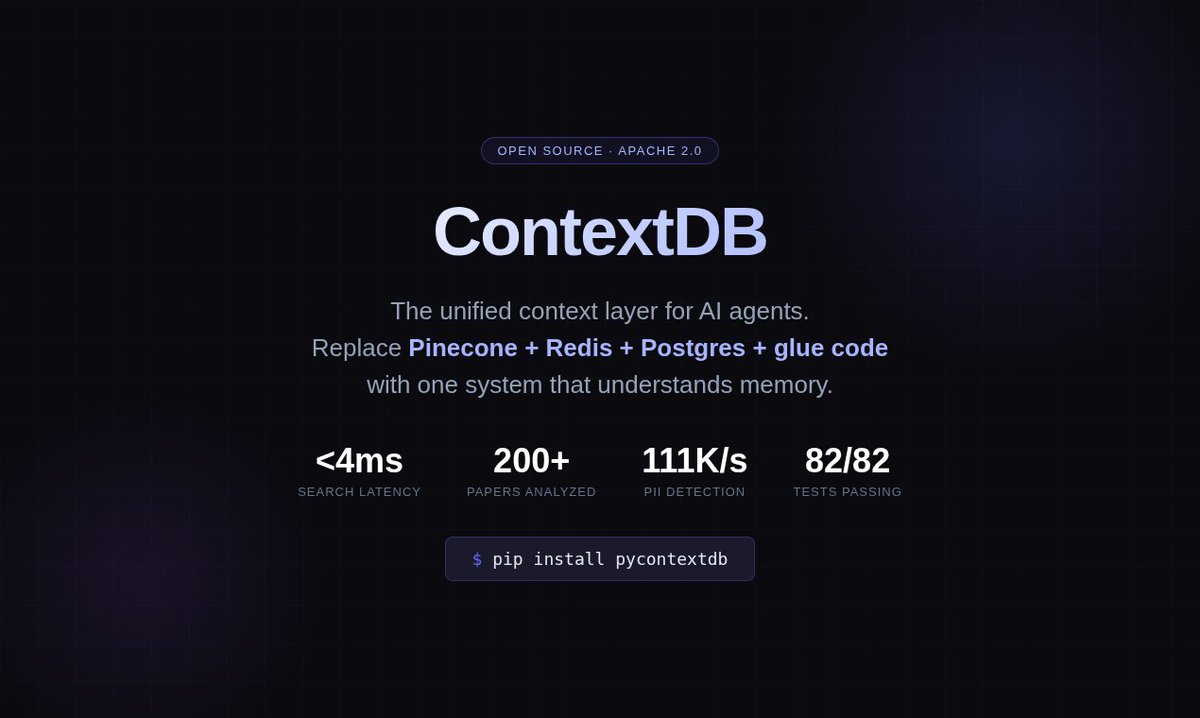
I just open-sourced ContextDB - a unified context layer for AI agents.
It replaces the patchwork of Pinecone + Redis + Postgres + glue code that every agent team builds with one system that actually understands memory.
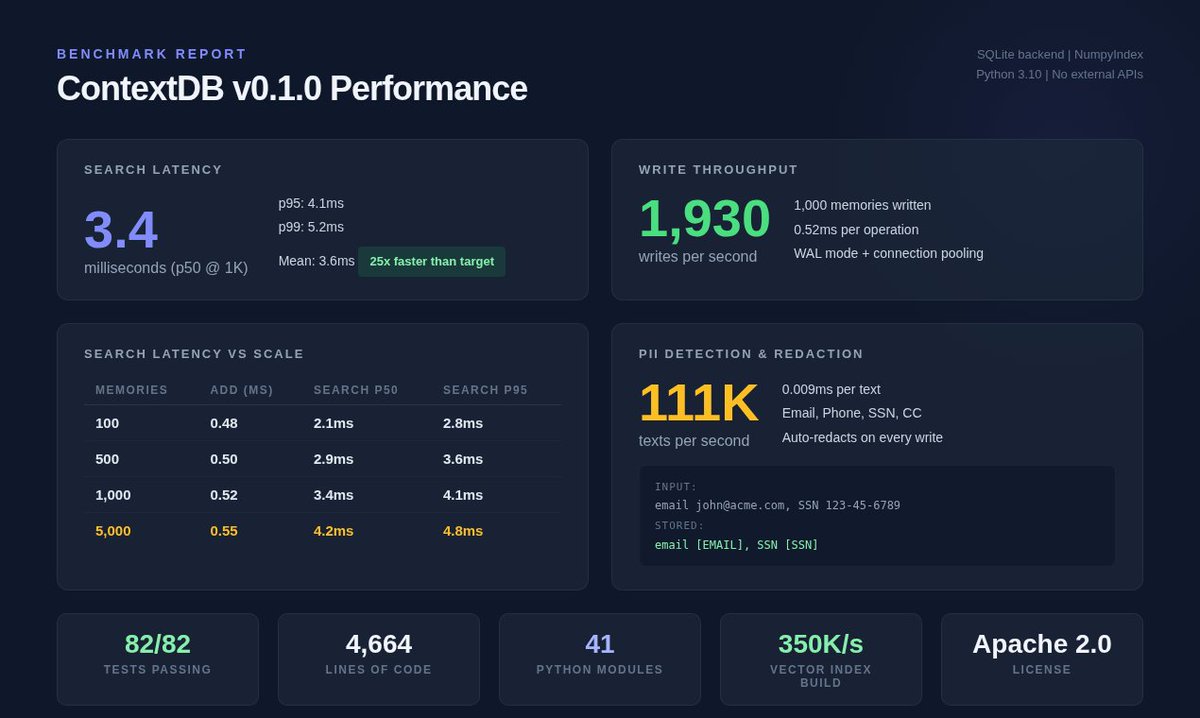
82 tests passing.
<5ms search latency.
Apache 2.0.
Thread on why this matters:
We're hiring for two important roles at @ai_atoms , our newest bet at @saas_labs.
We help mid-market and enterprise teams with deploying AI solutions, powered by our own proprietary AI operations platform.
Open Roles:
Applied AI Consultant - sits across the table from a CFO or VP of Ops and walks out with a scoped problem, a credible architecture, and a path to measurable value. Then stays accountable until that value is real. It's a mix of Solution Engineer + Solution Selling role.
Applied AI Engineer - takes that scoped problem and ships a production-grade AI system end-to-end. RAG, agents, evals, the works. Then keeps it alive when real users and real edge cases show up. If you love playing around with HF datasets, trying new models, have built some crazy setup using OpenClaw - you're going to absolutely love this.
AtomsAI sits inside SaaS Labs, the team behind @justcallhq , @callpage_io and @serviceagentai. 6,000+ customers globally. Over a billion conversations powered.
Raised over $55mil in venture capital, doing tens of millions in real ARR & profitable.
Now we're building the team that pushes it further.
5 days in office (preferrably Noida or Bangalore). High ownership. High Intensity. Fast cycles. No Large Team Office BS like bureaucracy or politics.
Just high value problem solving work.
If you've been waiting to build AI that actually works in production - not decks, not demos - let's talk.
Roles in the comments. Tag someone who'd be a fit. 👇
Being a founder is so freaking hard man.. chewing glass every day. If you fail, no one cares. If you succeed, you are given way more problems. Sometimes I really wonder how many founders wake up in the morning and ask themselves "is it really worth it".
Starting a company is so glorified - but building, scaling and maintaining one is a different story. This is why it's so important to do this for the right reasons - solve problems you are deeply passionate about and one you'll do even if the world is against you. At least there will be light at the end of the tunnel that's constantly drawing you in on those days when you are questioning your motivation.
I have never had the courage to personally start a company for this reason. Just wanted to say to the ones going through this - I see you, I salute you and I admire you 🫡
GitHub: https://t.co/WK9ccyQH4f
Paper: https://t.co/LJyS7qXeAO
License: Apache 2.0
Star it, try it, break it. Issues and PRs welcome.
If you're building AI agents and tired of the patchwork, this is for you.
I just open-sourced ContextDB - a unified context layer for AI agents.
It replaces the patchwork of Pinecone + Redis + Postgres + glue code that every agent team builds with one system that actually understands memory.
82 tests passing.
<5ms search latency.
Apache 2.0.
Thread on why this matters:
One of the hardest things I realise that every founder has to go through in their journey of building a venture is seeing - everyone else move on.
Move on for opportunities, move on from situations, move on for their reasons, move on from conflicts, move on because they can move on. Everyone has that choice, not the founder.
For founders to move on, they have to give-up. That's not how they are built, so they do all that is possible to win.
Even if they win, or lose, either ways - they end up being lonely in their own journey.
Spot on: the sync tax between a separate vector store and your primary DB is the real hidden killer.
pgvector + Postgres is a massive simplification for 80% of apps.
The paper actually agrees with you on the "just vector search with extra steps" critique, but it argues the bigger missing piece is the memory operating system on top: RL-trained decisions on what to keep/forget (48% better than heuristics), compression-as-denoising and unified episodic + semantic + procedural memory.
bit curious, have you found pgvector sufficient for those higher-level agent memory behaviors or do you still end up layering some in-memory heuristics on top?
Databricks gives agents a hard drive. What if we gave them a brain?
After analyzing 200+ papers on AI agent memory, I wrote a 20-page research paper on why the current patchwork (Pinecone + Redis + Postgres + glue code) is broken and what a unified memory OS for agents should look like.
Key findings:
- RL-trained memory decisions beat heuristics by 48%.
- Compression-as-denoising boosts retrieval 12-18%.
-Most "memory" systems are just vector search with extra steps.
Trying to get this on @arxiv_org but I'm a first-time submitter and need an endorsement.
If you've published 3+ papers in any cs.* category and want to take a look, DM me - happy to share the full paper. 🙏