GPT-5.5 (the one available right now to everyone) can also disprove the sum-product conjecture: https://t.co/gdHwLY3o20 . I didn't reveal it before because I think it is good to give some space to the community to absorb these new capabilities. In particular the humans involved in the discovery should get all the credit for this amazing breakthrough. We all have some work to do to align on cultural norms in this new world.
How do we automate business analytics with Claude?
New blog post covering our best practices for skills, data foundations, and evaluations when building agents to perform data analysis:
https://t.co/mfEJMAQFBU
The future of EA is AI-augmented 🤖 See how top leaders are leveraging AI to accelerate delivery, improve outcomes, and stay relevant to stakeholders—inside and outside the business.
Watch our on-demand webinar to learn more: https://t.co/N8hhkvTvwT
A new and possibly controversial perspective:
In this video, I explain the sense in which generative AI trained by supervised learning is incapable of making novel discoveries.
https://t.co/zin5QbbT9N
The text of the speech:
AI Creativity and Discovery
Good day ladies and gentlemen. I regret that I am unable to be with you all today to engage in a back-and-forth discussion, but I am nevertheless pleased to be able to share with you, via this recording, some high-level thoughts about the current and future state of artificial intelligence, and in particular about AI’s relationship to science and mathematics, which is, as I understand it, the central focus of this meeting and of the SAIR Foundation.
I would like to start with an old joke; I am sure you have heard it before. It is the one about the researcher whose work is being evaluated, and the review comes back, and says “This work is both novel and good. Unfortunately, the parts that are good are not novel, and the parts that are novel are not good.”
My first point about AI is that this assessment applies exactly to large parts of AI as we know it today. Not all of today’s AI, but a large part of it. Pretty much all of what we mean by “Generative AI”---which includes large language models, and the images and video models, and even the new methods for learning world models. All of these AIs take large numbers of examples and produce a “model” which behaves similar to the examples, that is, which generates text like people, or images like artists or nature, and videos like we find on the internet. Don’t get me wrong, Generative AI can be extremely useful. No doubt about that. But the assessment of the joke still applies. These systems can produce output that is both novel and good, but not at the same time.
In many ways this is just absolutely not a problem. When we ask an AI for an answer from the internet, or to summarize a document, we don’t want it to be novel. We are happy if the quality of the answer, the goodness, comes from the source material—from the people who wrote the document or the articles on the internet. If the AI’s answer is novel it means it is going beyond the source material, adding something beyond it. This is what we call “hallucinations”. In most cases, we don’t like it when the AI makes something up, when it adds something novel.
One exception, of course, is when we are looking not for facts or reality, but for fiction and entertainment. We might ask for a bedtime story for a child, or an image based on existing images on the internet but which is nevertheless different and distinct from them. In these cases, it is never easy for us to know how creative the AI is actually being, as we do not know how close the AI’s story, poem, or image is to the source material. In a real practical sense we can not know this because the internet is too big, the possible sources that the AI may draw upon are too numerous.
When we ask for a fiction or novelty, the AI can give it to us because its processing is in part stochastic. Every decision can go multiple ways and will go different ways and produce a different trajectory every time. The trajectory can be random—and thus novel—or it can be based on the training data—and thus “good” because the training data is good, sourced from people or reality. Thus, the trajectory is either novel or good—based on randomness or based on data—but never both at the same time.
Really, I think it is okay if the output of Generative AI is never good and novel at the same time. For the researcher in the joke this is a devastating criticism, but for most things it is not, and for Generative AI it is not. Generative AI is meant to be a mimic. This is what supervised learning is for. Generative AI can be extremely useful, even when it just mimics, if it is faster, or cheaper, or smaller, or more customizable, or more copy-able, than the thing being mimicked. It is okay if Generative AI cannot be both novel and good at the same time. It is still a transformative technology.
But it is a limitation. And remember we are here to use AI for science and mathematics, and for these areas the assessment of the reviewer in the joke is devastating. For these areas we need true creativity and discovery. Generative AI—or Mimicking AI—will never get where us there. For these we need something more, and indeed we have something more in other parts of AI. We have many AI systems which can give us more. We have AlphaGo with its world-changing move 37, or AlphaZero with its brilliant original chess-playing style. We have GT-Sophy that drives simulated racecars better than any human. We have AlphaFold and AlphaProof and Claude-Code, which have brought true advances in science, mathematics, and programming. We have RL-Lyft which optimizes the assignment of cars to passengers in the ride-hailing business. All these systems have found things that are both novel and good. And, truth be told, some language models have been augmented in ways that make them more than Generative AI based on supervised learning.
All these systems have some additional features that make them capable of true creativity and true discovery. It is important for us to recognize what this is—and that it is not present in ordinary, garden-variety Generative AI. It is something that can not come from just supervised learning, from learning from examples. What is it? Well, it is a simple thing, a commonsense thing. It is not new. We have many names for it, but unfortunately none of them are very good names. I will call it Discovery. Basically, Discovery is just the idea of trying many things and seeing which of them work, then keeping those that worked the best. Evolution by natural selection works this way. The scientific method works this way. And just ordinary life and learning works this way. We try things and remember what works. What could be more obvious? In this behavioral case, psychology has two names for it— “instrumental learning” and “operant conditioning”—and in machine learning it is what we mean by “reinforcement learning”. We also see the idea of Discovery in planning and combinatorial search—anything that involves the idea of “generate and test”.
The essence of Discovery is to combine three steps:
1. Variation,
2. Evaluation, and
3. Selective retention.
Of course, I am not the first to say this. I am not the first to point out that this combination of steps is key to science, to evolution by natural selection, and to animal behavior. I think particularly of papers by Donald Campbell, by Daniel Dennett, and by Gary Cziko. What is new in my remarks is to directly relate the idea of Discovery to modern AI to help us see that it is not present in supervised learning or Generative AI—in particular, that Discovery is not present in backpropagation or gradient descent.
Let me say explicitly what is missing from Generative AI. As we have remarked, these systems do have a stochastic aspect, so they do generate a variety of trajectories and behavior. What is missing is the Evaluation step. The generator was pre-trained by supervised learning, leaving no way at runtime to Evaluate what it generates. And of course without Evaluation there can be no Selective retention, and thus no Discovery. The variation can bring novelty, but without evaluation there is no Discovery, and arguably, no creativity. That is, I would say that creativity requires that the new things generated be Evaluated. Without evaluation, and retention of the best, there is nothing created. The novelty flickers into existence but, if its value is unrecognized, it flickers away and is lost.
In many cases, Evaluation is done by people to make a discovery. As when we have Generative AI make many pictures for us, and then we pick the one that we like the best. The human+AI system completes the discovery.
In many other cases, the Evaluation comes from a clear objective. Some moves lead to checkmate, some steps lead to a proof, some actions result in high reward, some genotypes make more copies, some theories explain the data better.
Some prefer the Variation step to be called Blind variation, where “blind” here means that it is uninformed, a shot in the dark. It does not need to be completely uninformed; a good scientist does not select theories to test at random. But neither can it be completely informed and determined. There must be some uncertainty about where the answer lies in order for there to be a discovery. In practice, the variation is partly informed and partly blind, but it is the blind part that corresponds to the discovery.
Now let us briefly go all the way to modern deep learning, to the backpropagation algorithm. At first it might seem that backpropagation is incapable of discovery because it is deterministic and thus incapable of variation. But this is not correct. The weight updates of backprop are deterministic, but the weights are initialized to small random values. The random initialization is often downplayed, but in fact it is a necessary form of variation; it must be done properly to get good performance. In backprop this Variation is done once, at network initialization, so its effect is temporary, and later the network may lose its ability to learn. This is the weakness of deep learning that is alleviated with a new algorithm that my group presented in Nature a couple of years ago. Our “continual backpropagation” made one small change: every so often a less-used neuron would be re-initialized to small random weights. This allows the variation to continue and plasticity to be retained.
Although there is much more to be said about Creativity and Discovery, this is the key point: they are more than supervised learning, more than pattern recognition, more than prediction, and more than world modeling. Those things are important, but they alone will not bring us to discovery. Discovery requires Evaluation from a person or from an explicit goal, and only in the latter case will we attain full autonomy.
So that is my call to arms. If we want the full power of AI scientists, then we should share the goals with them so they can create, evaluate, discover, and in these ways fully participate in achieving the goals. Let’s be bold! Let’s fully automate Creativity and Discovery!
TopologicPy is a spatial-semantic graph framework
A computational environment where geometric entities, topological relationships, building semantics, graph analytics, databases, GQL, GraphRAG, RDF, and AI workflows can speak the same ontology.
With the help of LLMs, a formal, comprehensive, consistent and persistent semantic layer has now been added that defines and connects concepts such as:
* Vertex, Edge, Wire, Face, Shell, Cell, CellComplex, Cluster, Graph
* Space, Room, Wall, Door, Window, Storey, Building
* Relationships, metrics, provenance, and analysis results
* IFC-derived entities and their semantic classifications
* RDF/OWL classes and properties for linked-data workflows
This starts to connect several worlds that are often treated separately:
* IFC and BIM geometry
* Topological spatial models
* Graph databases such as Neo4j
* GQL-style graph querying
* RDF and OWL semantic web models
* Linked Building Data
* BOT, Brick, and related building ontologies
* Graph machine learning
* GraphRAG and AI-based spatial reasoning
TopologicPy has morphed into a spatial-semantic computing framework: one that can move between geometry, topology, BIM, graphs, RDF, OWL, Linked Building Data, graph databases, machine learning, and AI reasoning.
By Wassim Jabi
https://t.co/cDEKqi31DA
#TopologicPy #SpatialComputing #BIM #LinkedBuildingData #GraphML #OpenSource
--
The Year of the Graph's Summer 2026 newsletter issue on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech is coming soon.
Subscribe and follow to be in the know. Reach out if you'd like to be featured 👇
https://t.co/7pg6gqWYvw
Graph Engines: Introducing Neo4j Virtual Graph - Graph reasoning on the data you already have
Unlocking the power of graph intelligence on all your enterprise data - no ETL needed.
Most graph conversations start with "move your data into a graph database." But what if you can't, or won't?
This is what Graph Engines address: they project a graph model onto warehouses, streams, application platforms and relational databases, and let you traverse and compute there, data in place.
This isn't a crowded space. It's an emerging precision category with a handful of serious offerings doing something genuinely hard. And that's exactly why it needs a map.
The notion of "query your graph-shaped data where it lives" is getting lots of attention lately, and for good reason.
The State of the Graph mapped Graph Engines. Now @neo4j is releasing a product in this category too.
Over the past few quarters, we’ve seen tremendous growth in enterprise adoption of agentic workflows. Large enterprises are realizing that GraphRAG delivers more accurate results than traditional RAG, multi-hop reasoning is essential for many high-value use cases, and memory and context graphs are critical for accurate decision-making.
However, enterprises want a zero-copy architecture; they do not want to move or duplicate data from their data warehouses, lakehouses, and operational databases into a Graph Datbase just to unlock the benefits of graph intelligence.
Neo4j is announcing Virtual Graph, available now in private preview.
Virtual Graph lets you run Cypher queries and graph algorithms directly against the data you already have in Snowflake, Databricks, and other databases and lakehouses.
The zero-copy architecture means your data stays where it is, governed by your existing controls, while you still get the power of Neo4j’s AI-powered Graph Tools. No new system of record to manage.
Virtual Graph surfaces the relationships your tables have always implied but never exposed, ready for graph queries, graph algorithms, and the AI agents that need to reason over them.
The promise: pointing a graph database at your existing warehouse and getting started in minutes, with no data movement, no schema rewrites, and no new pipelines to maintain.
To learn more about Graph Engines and Neo4j Virtual Graph:
Navigate the Graph Engines category: https://t.co/ispNC4O324
Introducing Neo4j Virtual Graph: Graph reasoning on the data you already have https://t.co/zrT19uQMIS
This is an emerging category, and more offerings will be generally available and production ready soon.
If you are exploring graph workloads but can't justify a new database yet, or simply prefer to keep your data where it lives, this map is meant to help you see where Graph Engines fit in your stack.
#GraphEngines #ProductRelease #EmergingTech
--
The Year of the Graph's Summer 2026 newsletter issue on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech is coming soon.
Subscribe and follow to be in the know. Reach out if you'd like to be featured 👇
https://t.co/7pg6gqWYvw
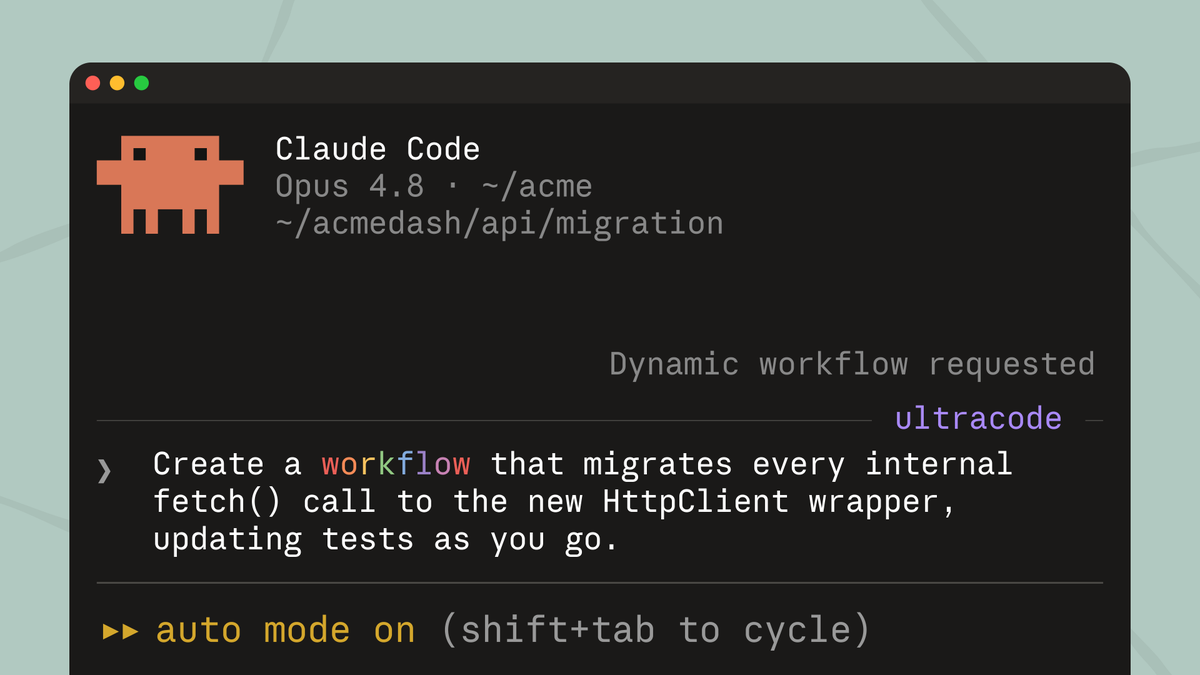
New in Claude Code (research preview): dynamic workflows.
Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
Use the word "workflow" in a prompt to get started.
autoreview is the most impactful skill I've added to my stack (next to https://t.co/SEj2XRpaD1). It automatically reviews your code before landing a PR.
Finds so many edge cases.
Sometimes it runs for hours.
https://t.co/zbUjIS2e1i
This is a new episode with Yusen Dai, Managing Partner at ZhenFund, the second episode in Yusen’s Entrepreneurship & Investment Insights series. https://t.co/YNGWumfBOh
New on the Engineering Blog: The access and permissions we grant agents should evolve with their capabilities. In our own products, we set these parameters through sandboxing, which limits the scope of any potentially destructive actions.
Read more: https://t.co/KfBKW8O9kP