Introducing Solaris: the first multiplayer world model exploration effort in Minecraft. We’ve built a scalable data collection engine, a multiplayer video diffusion model architecture, and a multi-view consistency evaluation benchmark. [1/9]
I am super happy to announce that I have recently joined @runwayml as a Member of Technical Staff, Research. Runway is paving the way towards multimodal world models that will fuel applications like film, robotics, and gaming.
Join us: https://t.co/w3KcQourk0
Current video world models operate in the partially observable image space. Solaris, being a multiplayer world model that simulates multi-view scenes consistently, is the first step towards the original world model definition of predicting the true world state. We hope that our work, specifically SolarisEngine, will lay the groundwork for future world model research. We open source everything: https://t.co/wn38cPJIgT.
Big thanks to my amazing collaborators: @ojmichel4, @fred_lu_443, @punwaiz, Timothy Meehan, Dhairya Mishra, @SrivatsPoddar, @Jacklu_me, @sainingxie. [9/9]
Introducing Solaris: the first multiplayer world model exploration effort in Minecraft. We’ve built a scalable data collection engine, a multiplayer video diffusion model architecture, and a multi-view consistency evaluation benchmark. [1/9]
Our model successfully learned how to simulate the joint world state in response to complex actions and environment stochasticity. For example, it starts raining simultaneously for both players, places torches and manipulates the hot bar, and simulates sword fighting on complex terrain. [8/9]
Writing tests can not only reveal bugs in your codebase but also in open source, established codebases your project depends on. Check out https://t.co/zU4H2AKOVW to see how we discovered a long-overlooked actions dataloading bug in @OpenAI's VPT repo.
Introducing Cambrian-S
it’s a position, a dataset, a benchmark, and a model
but above all, it represents our first steps toward exploring spatial supersensing in video. 🧶
Learning dexterous policies from human videos is challenging due to differences between human and robot hands.
We present HuDOR, a method that learns dexterous policies within the robot's physical constraints using just one human video and an hour of online interactions!
[1/n]
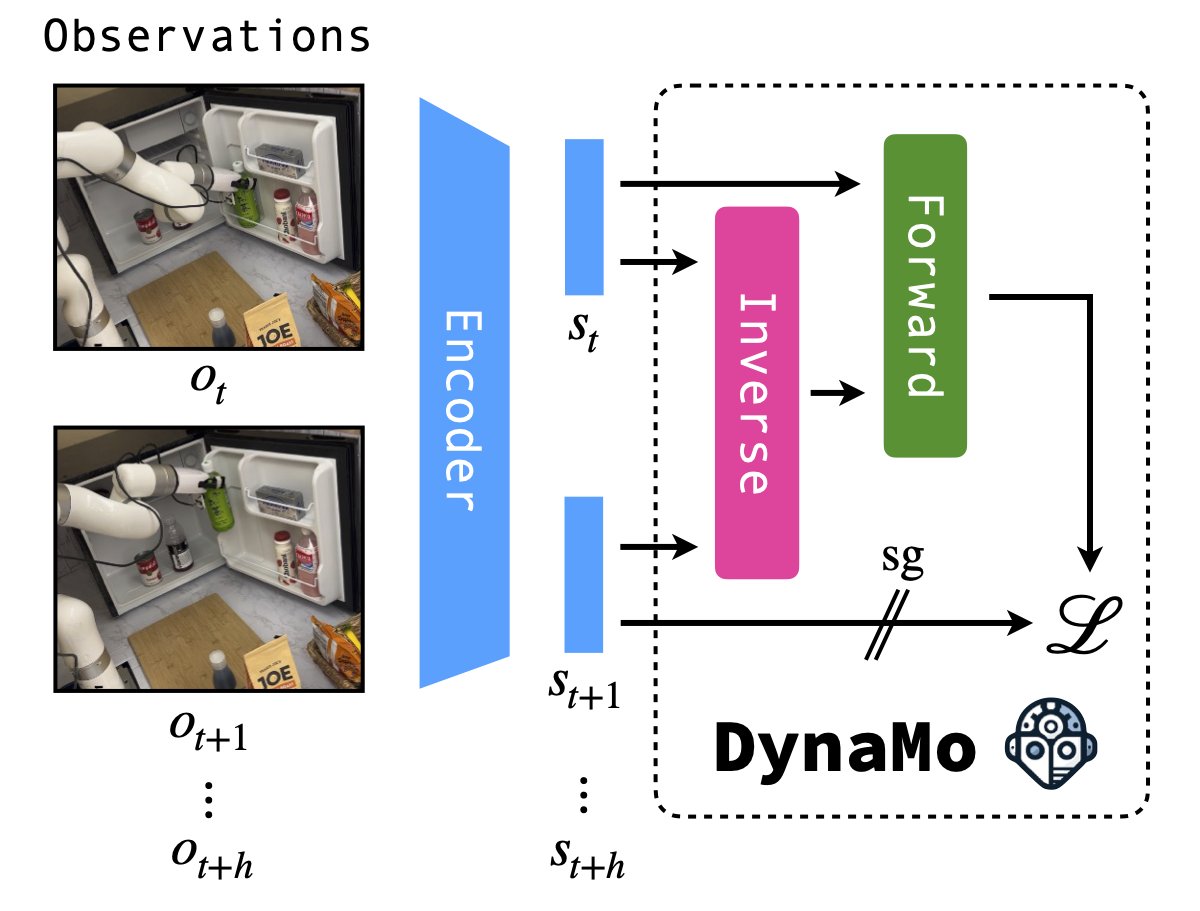
Why do we needs 100-1000s of demos to train even simple robot tasks? The answer: Supervised Learning wastes rich observational information.
To fix this, we built DynaMo, a Self-Supervised method that operates on small in-domain data by exploiting the dynamics of temporal data.