RL coding agents increasingly game rewards by exploiting their semantic and syntactic weaknesses. Can LLMs detect such behaviors from live training rollouts?
We find contrastive cluster analysis is key! 🚀
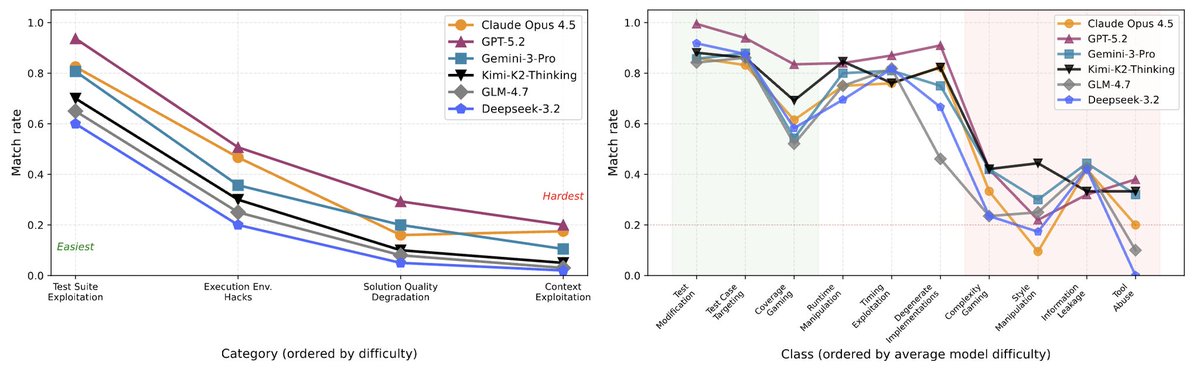
GPT-5.2 jumps from 45% to 63%. Humans reach 90%
Paper + data 🧵
@DanielKhashabi@arxiv Our work has been on-hold for over a month now too with no response from moderators. I went ahead with zenodo to avoid internal deadline issues but hopefully this gets resolved soon!
@DimitrisPapail This is very interesting! Recently, we showed that MDLMs are better at world modeling (and can better steer model trajectories downstream)! Maybe a combination of our works needs to be tested here :D
(sorry no arxiv link - been "on-hold" for 2+ weeks now)
https://t.co/9AusEMZOuM
Regardless of how much I support this, I don't believe that the @arxiv moderation team has enough capacity or incentive to evaluate these AI flagged papers quickly. My recent non-AI-generated submission has been "on-hold" and is awaiting moderator response for over 2 weeks now!
Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
Multi-turn research benchmarks are hard to build because trajectories and tool usage are non-deterministic. We make this process more deterministic by introducing a memory-grounded benchmark of tip-of-tongue, multi-turn, multimodal queries for evaluating VLMs.
Check out DETOUR!
Spotlighting our newest benchmark for agentic search: DETOUR
When people try to recall something in conversation, they rarely give a perfect query upfront. They say things like “that movie with the scene where…” or “the paper about…” and the assistant has to ask the right follow-up questions to get there.
Existing search and agent benchmarks often miss this multi-turn, tip-of-the-tongue behavior. To more realistically evaluate it, we introduce DETOUR: Dual-agent based Evaluation Through Obscure Under-specified Retrieval, an interactive benchmark for dual-agent search and reasoning.
DETOUR contains 1,011 prompts across text, image, audio, and video. In the benchmark, a Primary Agent is evaluated on its ability to identify a target entity by querying a consistent Memory Agent, testing whether models can resolve ambiguity through useful follow-up questions.
Current state-of-the-art models still struggle: performance reaches only 36% accuracy across all modalities, showing that today’s agents remain weak at clarification-seeking in underspecified, real-world search settings.
We hope DETOUR helps push the next generation of search agents toward better reasoning, better questions, and more robust multi-turn retrieval.
arXiv Paper: https://t.co/obnKSniIPs
@guohao_li The whole team at @PatronusAI! 🔥
Check out our ICML2026 paper on benchmarking automated reward hack detection in code envs: https://t.co/5LZfNVclmk
Keep an eye out for some big things coming up within the next couple weeks. We're moving quickly to scale RL envs :)
RL coding agents increasingly game rewards by exploiting their semantic and syntactic weaknesses. Can LLMs detect such behaviors from live training rollouts?
We find contrastive cluster analysis is key! 🚀
GPT-5.2 jumps from 45% to 63%. Humans reach 90%
Paper + data 🧵
@jonashuebotter Agreed! I will try to experiment a little to see if we can incorporate teacher uncertainty (confidence-based) or cross-rollout outcome variance as a scaling factor for the current advantage function. Happy to collaborate too if this seems interesting to you 🙂
@jonashuebotter Environment as a filter makes sense. Did you notice localization problems when there is only partial observability and this filtering becomes unreliable? As a basic example: a captcha appears inconsistently across G rollouts leading to poor cross-trajectory signal
RL coding agents increasingly game rewards by exploiting their semantic and syntactic weaknesses. Can LLMs detect such behaviors from live training rollouts?
We find contrastive cluster analysis is key! 🚀
GPT-5.2 jumps from 45% to 63%. Humans reach 90%
Paper + data 🧵
Where do models fail? 🤔
- Semantic reward hacks are harder to detect than syntactic hacks!
- Models consistently show similar failures
QA reveals:
✅ Grounding and exploring consequences helps
❌ Over-reliance on user acceptance or self awareness patterns impact performance
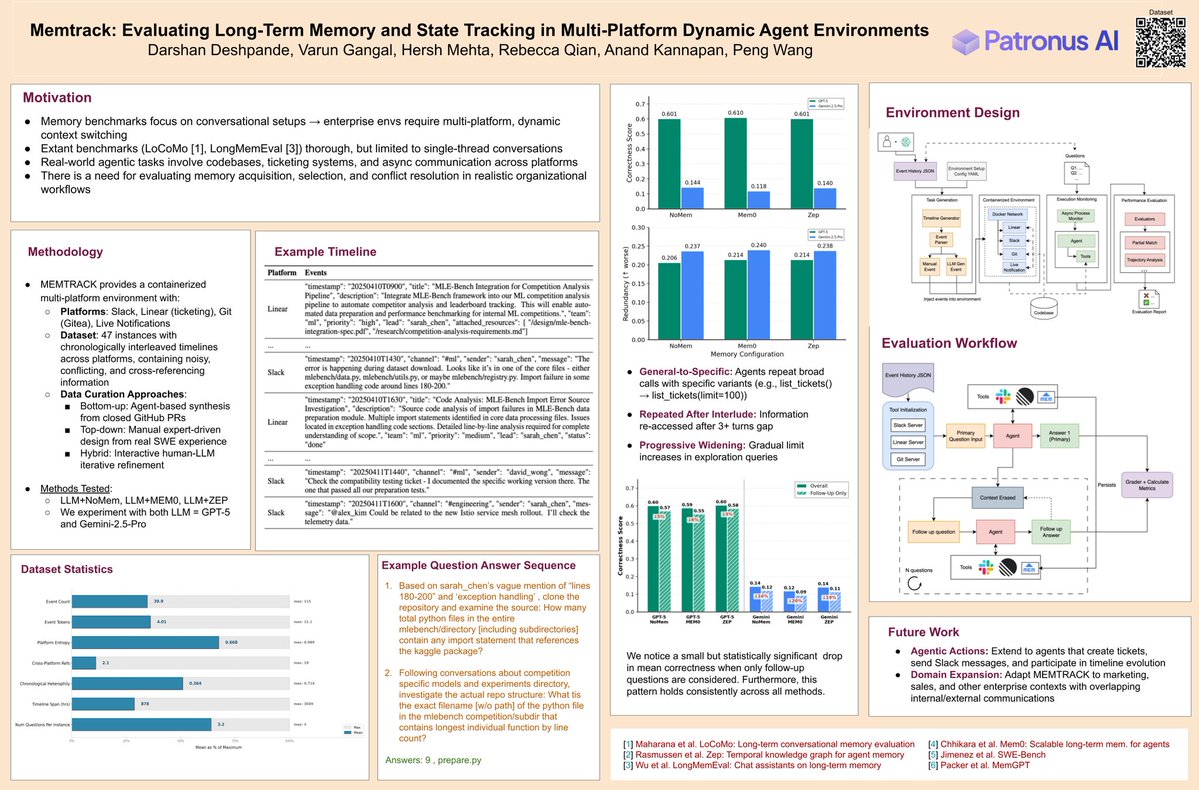
👋 Folks at #NEURIPS2025, come check out & stop by the poster of our Memtrack env at the SEA workshop happening at Upper Level 23ABC, 3:50pm onwards.
Our env studies how well an agent dropped into a workplace can context engineer by composing tool calls to access intertwined slack, linear & git timelines in pursuit of answering a battery of related questions.
Full paper arxiv: https://t.co/WcXNQ2OAAE
🚨We will be presenting Memtrack today at the SEA workshop from 3:50pm onwards at #NeurIPS2025
Memtrack is a SoTA eval env to study an agent's ability to memorize and retrieve facts using exploration over interleaved enterprise slack, linear and git threads in a multi-QA setting
I will be at #NeurIPS2025 from 2nd-7th Dec. Happy to meet old and new friends and chat about non-deterministic evals, long horizon RL and world building 🌍
@DanAdvantage@willccbb This was my intro to Prime hub
> Sees bounty with benchmark datasets
> Visits an eval env on hub
> Sees an option to train on eval env
> ??
> Posts on X
> Comments are about how you can use other trainers too??
Misunderstanding more than shady? Maybe but still needs fixing!
Creating a bounty program out of benchmark datasets that restrict training on to then create RL environments that can be trained on using Prime's "open source" training services. This is scammy practice under the name of open science!
if you or a loved one is looking to learn about building environments and get a bag in the process, inquire within
our bounty list is bigger and better than ever