The smartest people on the internet just open-sourced their brain.
11 GitHub repos worth bookmarking:
- PilotDeck — OpenBMB's open-source AI agent framework. Build and deploy autonomous agents in minutes.
https://t.co/ozmSncagqb
- andrej-karpathy-skills — Karpathy's AI coding wisdom in a single markdown file. 109K+ stars.
https://t.co/tOr4XGZnDy
- MemPalace — Milla Jovovich co-built this AI memory system with Claude Code. Near-perfect LongMemEval score.
https://t.co/zjSwfv3PeV
- OpenClaw — Peter Steinberger's personal AI assistant. 300K+ stars. Fastest growing repo in GitHub history.
https://t.co/vgWKVDhXyZ
- autoresearch — Karpathy's research automation framework. 23K stars in three days.
https://t.co/fVnXmLjpcH
- awesome-claude-code — The canonical Claude Code playbook. Used inside FAANG, OpenAI, and Anthropic.
https://t.co/ylSdRRATgg
- agent-skills — Addy Osmani's production-grade engineering skills for AI coding agents. 30K+ stars.
https://t.co/ClswBl8zCO
- AI-Agents-for-Beginners — Microsoft's free 12-lesson course on building AI agents.
https://t.co/DhS6mUJuDk
- awesome-llm-apps — 106K+ stars. The largest collection of working AI apps on GitHub.
https://t.co/ilZKbFPxp7
- hermes-agent — Self-evolving AI agent. Gets smarter the more you use it.
https://t.co/06jfIpEy6W
- qlib — Microsoft's full quant investment platform. A hedge fund brain, free to clone.
https://t.co/sBbYjvXzkx
Save this post!
Follow me for more ♻️ Repost so others don't miss it.
Trains billion-parameter LLMs from scratch on a single GPU
Most people think training an LLM needs a datacenter and millions of dollars.
This repo proves otherwise.
It shows how to build and train GPT-style models from scratch with techniques that make large-scale training possible on consumer hardware.
From tokenization to distributed tricks — everything is open-source.
https://t.co/QgyPOYUxge
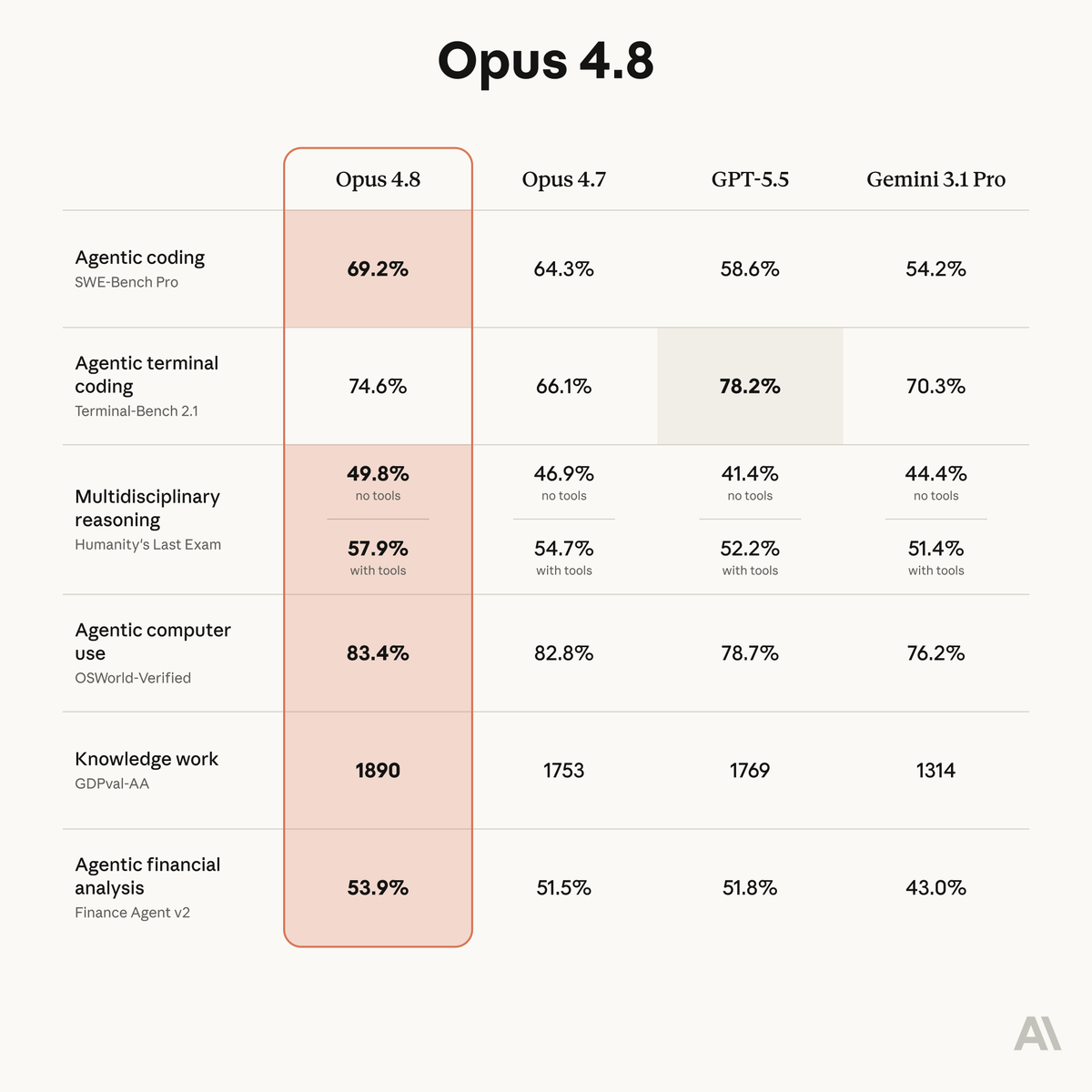
Anthropic 이 Claude Opus4.8 을 발표하면서 Harness 본체인 Claude Code 쪽에는 신기능인 Dynamic Workflow 를 발표했습니다. 진정한 오케스트레이션을 위해서는 사실상 workflow 관련 기능이 필요한데, 이제야 나온거죠. 오늘 이 발표로 AI agent 는 또 한 번 크게 진화하게 됩니다.
멀티 에이전트를 하네스로서 최초로 구현한 것이 Claude Code 에서였고, 그 이후로 agent team 을 론칭한 이후 대략 반년 정도의 공백만에 이걸 적절히 조합한 것, 아니 그 이상의 의미를 지니는 것으로 보시면 됩니다.
공식 문서는 https://t.co/o2r6bGm0pO 입니다.
기존에 몇몇 오픈소스들도 바로 영향을 받겠네요. 아니 그렇다기보단, 그런 오픈소스들 덕분에 선도 회사에서 이런 것들을 더 늦지 않게 내놓는다고 보는 게 맞을지도요.
소셜에 올라오는 내용들 보면 새로 생긴 ultracode 명령어로 서브에이전트 수백개를 동시에 돌려서 오랫동안 복잡한 일들을 알아서 처리하는 것에 집중해서 이야기하고 있는데, 틀린 이야기는 아닙니다만 진짜 본질은 다른 곳에 있다고 봅니다.
우선, 두번째 이미지를 보세요. 저 공식문서에 있는 영문 테이블을 한글로 번역해서 터미널 출력을 캡쳐한 것인데, subagent, skill, workflow(이번에 새로 추가) 이 세가지 핵심 개념을 헷갈리지 않게 잘 정리해 놓은 표입니다. 이 이해가 핵심입니다. 즉, 어떤 경우에 스킬, 서브에이전트, (다이내믹) 워크플로우를 사용해야 하는지 적절한 판단을 하기 위해서, 이들의 핵심 메카니즘을 비교 설명한 표입니다.
수백개 (기존에는 제 경험상 20여개가 한계)의 서브 에이전트가 돌아가는 것은 대규모의 복잡한 워크플로우를 돌리면서, 그것도 요소마다 구현, 검증, 수정 각각을 배치해서 편향이나 컨텍스트 오염을 막고 전문성을 높이는 데에 필요조건은 맞습니다만, 충분조건이 될 수는 없습니다. workflow 역시 그것만으로는 충분조건은 아닙니다만, 이 둘이 함께 있으면 충분조건이 됩니다. 일할 사람과 일하는 규칙이 셋팅이 되는거니까요.
워크플로우는 쉽게 생각하시면 일이 진행되는 프로세스로 보시면 됩니다. 어떤 경우에는 어떤 것이 실행되어야 하고, 언제 멈춰야 하고, 언제 넘겨야 하고, 입력과 출력은 어떻게 되어야 하고 등등의 규칙 덩어리입니다. 이 규칙대로 반드시 실행이 되어야 하죠. 이런 규칙을 흔히 script 로 표현하는 간단한 프로그램으로 만들어서 실행합니다.
AI agent 는 기본적으로 완벽하게 규칙대로 흘러가지 않습니다. 장점이자 단점인데, 스스로 판단을 해야 하는 것이 필요한 경우에는 agent 를 써야 하지만, 무조건 정해진 규칙대로 루틴하게 돌아가야 하는 것을 agent 에게 맡기면 돌발 상황이 생기기 때문에 이런 것은 워크플로우로 처리해야 합니다.
따라서, 기존에 AI 를 활용한 어떤 것을 만든다고 할 때에는 AI agent 에게 맡겨야 하는 부분과 그러면 안되고 철저하게 독립적인 프로세스를 다따라야 하는 부분으로 나누어서 개발을 하되, 이 둘을 연결하는 것도 워크플로우의 최상단으로서 잡아주어야 했습니다. 그런 워크플로우 자체도 AI agent 와 개발하긴 했지만요.
이제 이 워크플로우 자체를 워크플로우가 필요한 시점에 AI agent 가 주어진 목적에 맞게 직접 설계하고 구현합니다. 그래서 dynamic workflow 라고 dynamic 이 붙었습니다. 만약 실행 중에도 동적으로 워크플로우 스크립트 변형을 AI 가 할 수 있으면 이건 AI 가 혼자 멋대로 판단해 버리는 이슈 때문에 제대로 워크플로우가 돌아가지 않는데, 공식 기술문서를 보면 당연하게도 실행되는 중에는 AI 절대 관여하지 못하고 철저하게 작성된 스크립트에 따라 워크플로우가 제어되게끔 돌아가는 구조입니다.
한편, 첫번째 이미지는 Anthropic 의 PM 인 Cat Woo 가 올린 직관적인 비교 설명 다이어그램인데, 기존 서브에이전트는 그 서브에이전트끼리는 서로 통신할 수 없었고, Agent Team 로 호출한 에이전트들끼리만 통신이 가능했으나, 이번 dynamic workflow 를 내놓으면서 최소한 이 모드에서는 서브에이전트끼리도 통신이 가능한 것처럼 보입니다.
아직 직접 테스트 전이지만 공식 기술문서들을 체크해 보니, 여전히 서브에이전트끼리는 통신이 불가능하고, 에이전트가 직접 mesh 로 메시징이 가능한 것은 agent teams 로 호출한 에이전트들끼리만 가능합니다. 그러면 저 다이어그램은 뭐냐. 추상화시킨 것을 개념적으로 시각화한 것인데 깊게 파고들면 오해를 낳을 순 있겠네요.
살펴보니, 기술적으로는, subagent 를 호출하는 것은 script 입니다. 즉 서브에이전트간에 nested 계층 구조 같은 것은 없으며 script 가 다수의 서브에이전트들을 스폰해서 각각 역할 설정뿐만 아니라, 서로 어떻게 통신해야 하는 지에 대한 프로토콜도 전부 스크립트에서 제어하고, 주고 받아야 하는 통신 내용도 스크립트의 변수로 철저하게 통제할 수 있습니다. 당연히 워크플로우라면 이래야 합니다.
굳이 이런 속사정까지 이해할 필요 없이 어떤 것이고 어떻게 쓰는 지 궁금하신 분들은 첫번째 동영상이 가장 도움이 되실 것 같습니다. X 에서 공식 계정에 붙은 댓글들 중에 @ajith_io 가 올린 동영상입니다. 잘 만들었네요.
Anthropic 은 하반기에 대규모 메모리, 특히 팀으로서 에이전트들간에 협업을 하는 데에 집중하여 이에 대한 R&D를 할 것이라고 담당자가 한 인터뷰에서 이야기했습니다.
개인적으로 "전문가 에이전트 협업"에 집중하고 있고 (1인 기업으로서 이게 튼튼해야 제 사업이 잘 되서), 이에 필요한 여러가지 요소들을 구현하고 업데이트하고 시스템화하고 있는데, 추후 Anthropic 이 어떤 것들을 내놓을지 대충 예상이 되니 최대한 엄하게 중복되지 않도록 엣지 포인트만 좀 더 걸러서 집중하는 중입니다.
제가 어떻게 AI 전문가 팀을 활용하고 있는 지는 현시점에서는 https://t.co/22UH4BPzYS 1시간 영상과 이 영상에 달린 질문 댓글의 답변에 가장 잘 담겨 있습니다. 궁금하신 분들은 참고해보세요. 그나저나 이제 13일 됐는데 조회수 2만 4천을 넘었네요...
#ai #agent #workflow #claudecode
Pi v0.77.0 is out.
Highlights:
- Claude Opus 4.8 support added with updated adaptive-thinking coverage.
- New --exclude-tools / -xt flag to disable specific built-in, extension, or custom tools while leaving the rest available.
- Device-code login for OpenAI Codex subscriptions available as a headless alternative to browser login.
- InputEvent.streamingBehavior lets extensions distinguish idle prompts, mid-stream steers, and queued follow-ups.
Complete details in thread ↓
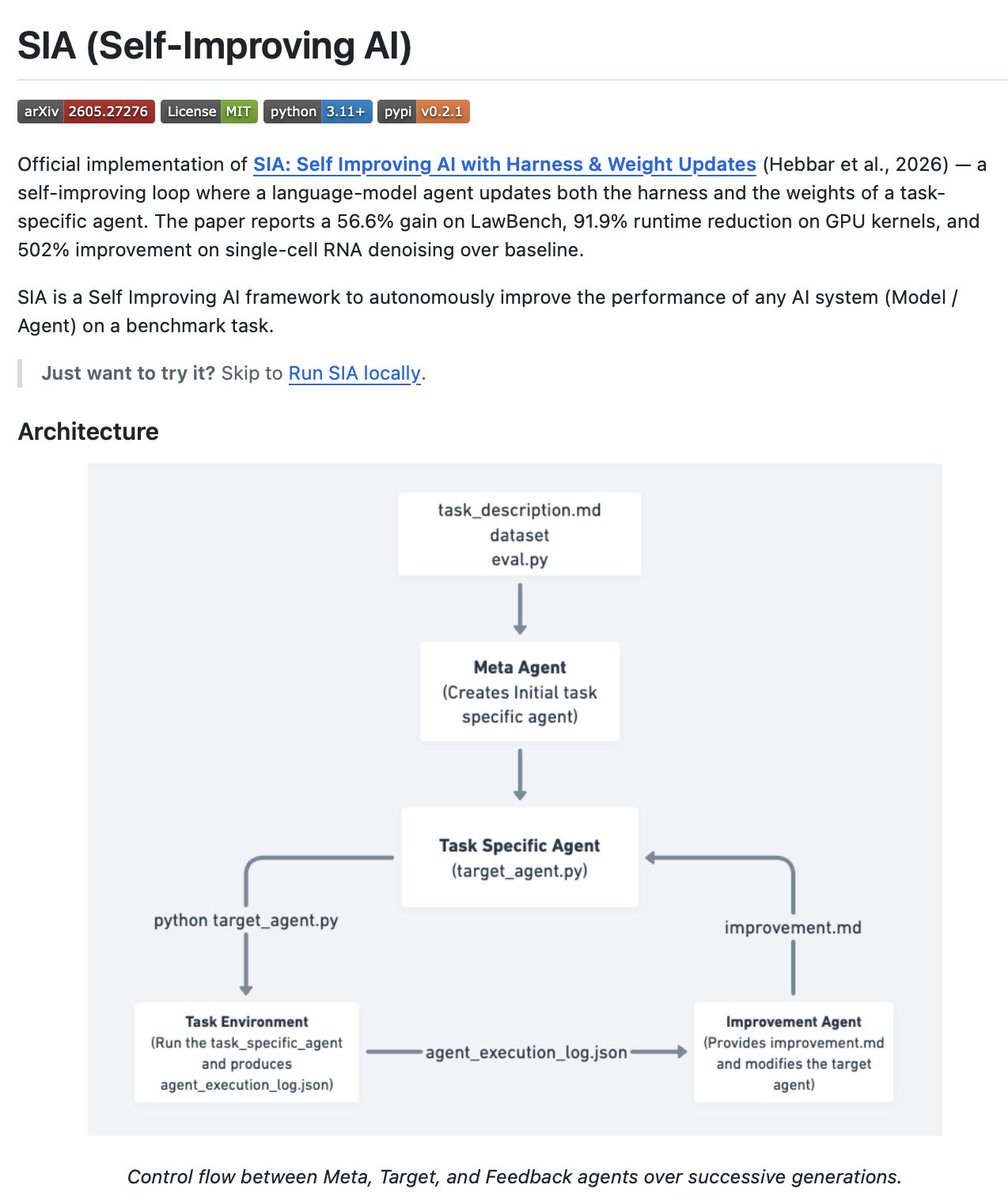
Self Improving AI (SIA) beats Karpathy's autoresearcher agent by improving itself!
SIA is a Self Improving AI framework to autonomously improve the performance of any AI system (Model / Agent) on a benchmark task.
Most agent frameworks are static. Fixed harness, fixed model weights, fixed memory layer. They plan, act, and use tools. SIA operates on a different layer entirely.
SIA focuses on one problem: how do you design structured feedback loops that allow an agent to evaluate its own performance, adapt its strategy, and get better over time?
After every run, SIA evaluates itself and improves three things. It updates its own harness. Updates the weights of its underlying model. Updates its own memory layer to handle new complexities. The agent rewrites itself based on what it learned.
On MLE-Bench, OpenAI's benchmark for evaluating an agent's ability to train ML models, SIA climbed to the top of the leaderboard. Beat every specialized ML research agent including MLEvolve and AIRA-dojo. Then kept improving and displaced its own previous versions on the leaderboard.
I've shared the link to the paper and the repo in the replies!
🚨 MICROSOFT JUST OPEN-SOURCED A WAY TO “TRAIN” AI AGENTS WITHOUT TOUCHING MODEL WEIGHTS
SkillOpt treats a simple markdown skill file like neural network parameters and optimizes it with learning rates, validation checks, minibatches, and epochs.
The result? Agents get smarter over time while the base LLM stays frozen.
Instead of retraining models, it continuously improves the agent’s reasoning rules inside a single readable .md file.
Paper: https://t.co/6KeabqThlf
GitHub: https://t.co/geCmfimwnr
introducing pi-dynamic-workflows
This is probably going to be a bigger token burner than pi-goal, BUT, dynamic workflows is the first implementation of subagents that i don't hate, mainly because it's "code mode" for subagents. agent writes a js-based workflow DSL into a dedicated tool, engine parses the workflow code and runs it.
the dsl implements some primitives for the agent (agent(), parallel(), pipeline(), phase() and log()) to keep it as simple as possible.
now available in @badlogicgames pi!
pi install npm:pi-dynamic-workflows
To simplify our Codex compute fleet management, we will be sunsetting GPT-5.2 and GPT-5.3-Codex in Codex on June 2nd when logged in with your ChatGPT account.
For free plans, GPT-5.5 will be the default frontier model to build and work with going forward.
These models will remain available on our API.
Instead, it's a single agent skill that finds and retrieves the best guidance for your use case!
Check out the site here: https://t.co/2gclxj9rHw, and can be installed with npx modern-web-guidance@latest install. Our evals run daily with state-of-the-art models and coding agents!
// Adapt the Interface, Not the Model //
I am fascinated by the results across my cheap-model-plus-good-harness builds.
This new paper also shows good signs of the code-as-agent-harness thesis.
The idea is really simple. Do not touch the model. Instead, modify the runtime interface that wraps the frozen LLM. Then convert recurring interaction failures into reusable interventions on the harness side.
The paper reports an average relative improvement 88.5% across 7 deterministic environments, 126 model-environment settings, and 18 backbones.
A harness learned from one model trajectory generalizes to 17 other backbones. That tells you the harness is capturing environment structure, not model-specific patterns.
If you ship agents in production, your harness work is more portable than you might assume.
Paper: https://t.co/Petka4g3F2
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX