It’s been a while since I posted here, but I’m very excited to share what our team at @nvidia has been building over the past year!
After a year of active development, we’re getting ready to release SIL-Wheel to the world: a one-stop shop platform for data-centric workflows in large-scale video model training.
Built by researchers, for researchers, SIL-Wheel brings together search, curation, annotation, evaluation, and analysis for large video datasets in one centralized framework.
Want a sneak peek before the official release? Come by the NeXD26 Workshop @CVPR tomorrow at 10:30!🚀
Looking for a nice home for your paper? #3DV2027 is waiting! 🎉
⏰ Conference dates: April 6-9, 2027
✈️ Place: #Thessaloniki (#SKG), #Greece 🇬🇷
📝 Paper ddl: Aug 28
🎥 Supp ddl: Sep 02
🆕 Rebuttal only upon invite for borderline papers!
#CallForPapers: https://t.co/6Fy3QG7PRE
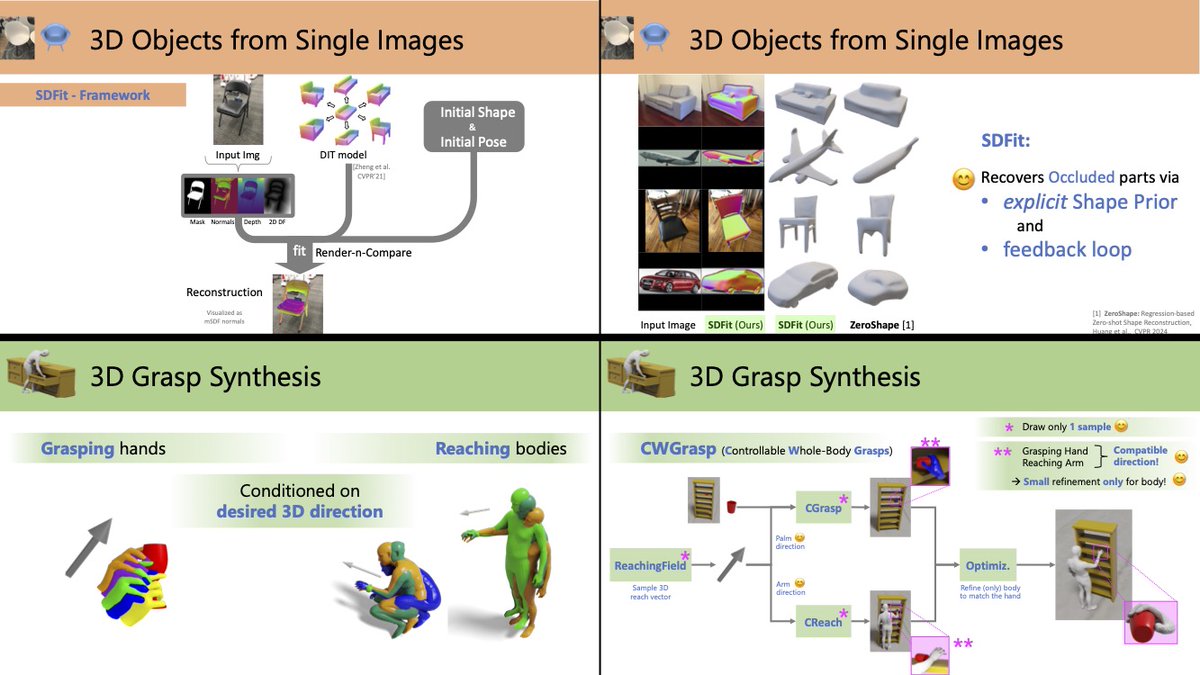
Recovering 3D object pose and shape from a single image is really challenging. SDFit introduces a novel framework that deals successfully with this problem. Congrats to @anticdimi for the amazing work!!!
Intelligent systems need to understand #3D Objects from single images. However, recent SotA methods work well for unoccluded views & common poses, and prioritize shape over pose. We tackle this by developing #SDFit #ICCV2025 a novel Render-n-Compare framework for 3D objects that:
👉 Is robust to occlusion & uncommon poses
👉 Treats both Shape & Pose as 1st class citizens
(1/6🧵)
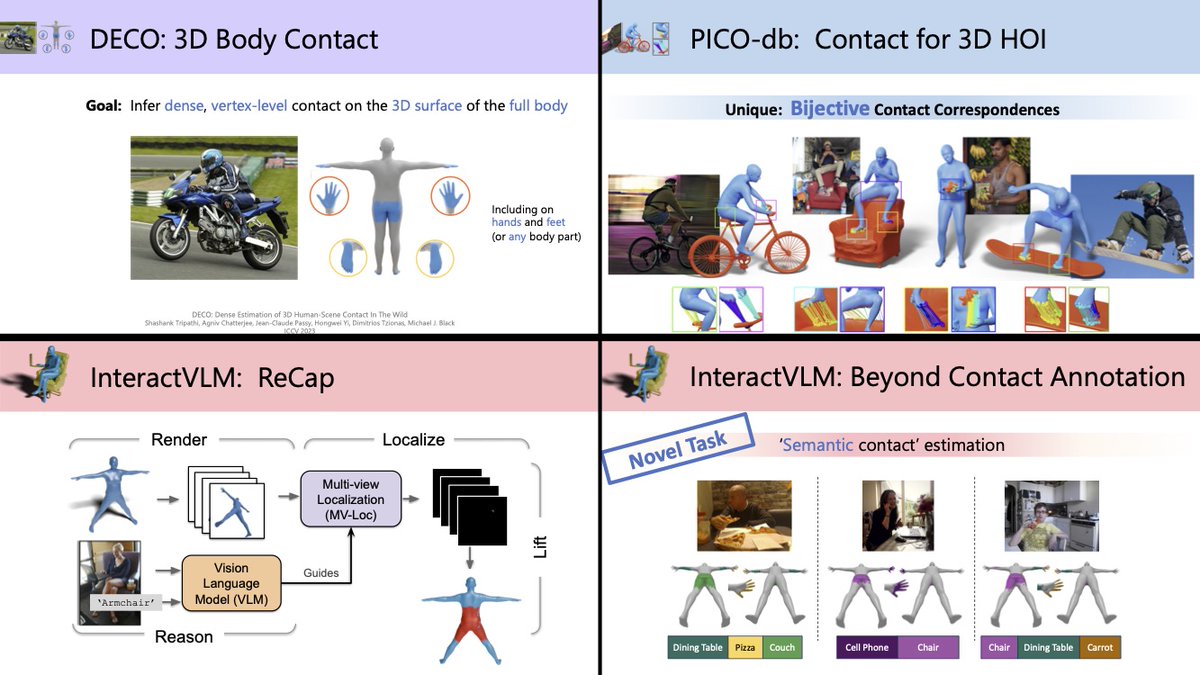
🔥 New InteractVLM Models Released! (#CVPR2025)
🔹 Single Model for Joint Human-Object Contact
🔹 3D Human Contact trained on more data, now supports foot-ground contact
🔹 Direct Contact Estimation on Images (2D)
🔗 [Code] https://t.co/pHmxvl6JUn
🎯 Modeling how people interact with objects in #3D is important for both 3D #perception from 2D images, and for 3D #avatar synthesis for AR/VR
👉 I gave a talk on this @ #BMVA 'Symposium on Digital Humans'
👉 Video: https://t.co/RJs3fOygDX
👉 Slides: https://t.co/8wJwEGYuss
🤔 Can we synthesize videos of realistic physical interactions?
🎉 Our InterDyn #CVPR2015 method controls a video foundational model via a 2D signal of an actor's motion!
👉 Project: https://t.co/2yauHvFsz6
👉 The 1st authors are in the job market!
@HavenFeng,@rick_akker25502
📢 We present CWGrasp, a framework for generating 3D Whole-body Grasps with Directional Controllability 🎉
Specifically:
👉 given a grasping object (shown in red color) placed on a receptacle (brown color)
👉 we aim to generate a body (gray color) that grasps the object.
🧵 1/10