Andrej Karpathy spent 2h showing how he actually uses AI day to day
he's a co-founder of OpenAI and led AI at Tesla, so when he shows how he works, it’s worth watching
and the whole session is just him telling the machine what he wants in simple terms, like he's briefing a coworker
watch what's actually happening the entire time:
> he describes the task in normal words
> it goes off and does the work
> he glances at the result and nudges it with one more sentence
that's the whole skill, and you've had it since you learned to talk
the only gap between that and a worker that runs on its own is handing that sentence a schedule and the tools to act
check his work, then build the version that keeps working when you stop
Loved this breakdown of how GPS actually works: clear, clever, and super easy to follow.
One of those posts that makes a complex topic suddenly click.
https://t.co/ptTZEWZxgY
10 repos blowing up on GitHub this week that replace $1,500/month in AI tools
1. andrej-karpathy-skills → replaces paid Claude Code courses
one CLAUDE.md file from Karpathy's LLM coding observations
48,965 stars. 7,939 stars TODAY
https://t.co/xjnhzKjQAo
2. claude-mem → replaces paid context/memory tools
auto-captures everything Claude does across sessions
compresses with AI and injects into future sessions
59,373 stars. 1,907 stars today
https://t.co/dZPWBSfRz0
3. voicebox → replaces ElevenLabs ($22/mo)
open-source voice synthesis studio
18,963 stars. 887 stars today
https://t.co/TEOE9CNU3l
4. open-agents → replaces paid agent platforms ($200/mo)
open-source template for building cloud agents. by Vercel
3,105 stars. 735 stars today
https://t.co/2jj3Tzami0
5. cognee → replaces paid knowledge bases ($50/mo)
AI agent memory engine in 6 lines of code
15,733 stars
https://t.co/FHetFdNKfw
6. magika → replaces paid file detection tools
AI file content type detection. by Google
14,603 stars
https://t.co/9Bse8nSiLu
7. GenericAgent → replaces paid agent infra ($100/mo)
self-evolving agent. grows skill tree from 3.3K-line seed
6x less token consumption than standard agents
2,661 stars. 883 stars today
https://t.co/3KnpT3mqAg
8. omi → replaces Rewind AI ($25/mo)
AI that sees your screen + listens to conversations
tells you what to do next
8,952 stars. 488 stars today
https://t.co/EBzpS20o0i
9. evolver → replaces manual agent optimization
self-evolution engine for AI agents
genome evolution protocol
3,074 stars. 866 stars today
https://t.co/v1JhJT0r44
10. wallet tracking + copy trading → Kreo
tracks top Polymarket wallets. auto copies trades
the only tool on this list i actually pay for
because it makes more than it costs
→ https://t.co/rVKQ1081rt
total before: ~$1,500/month in AI subscriptions
total now: $0 + Kreo
like + bookmark you'll need this
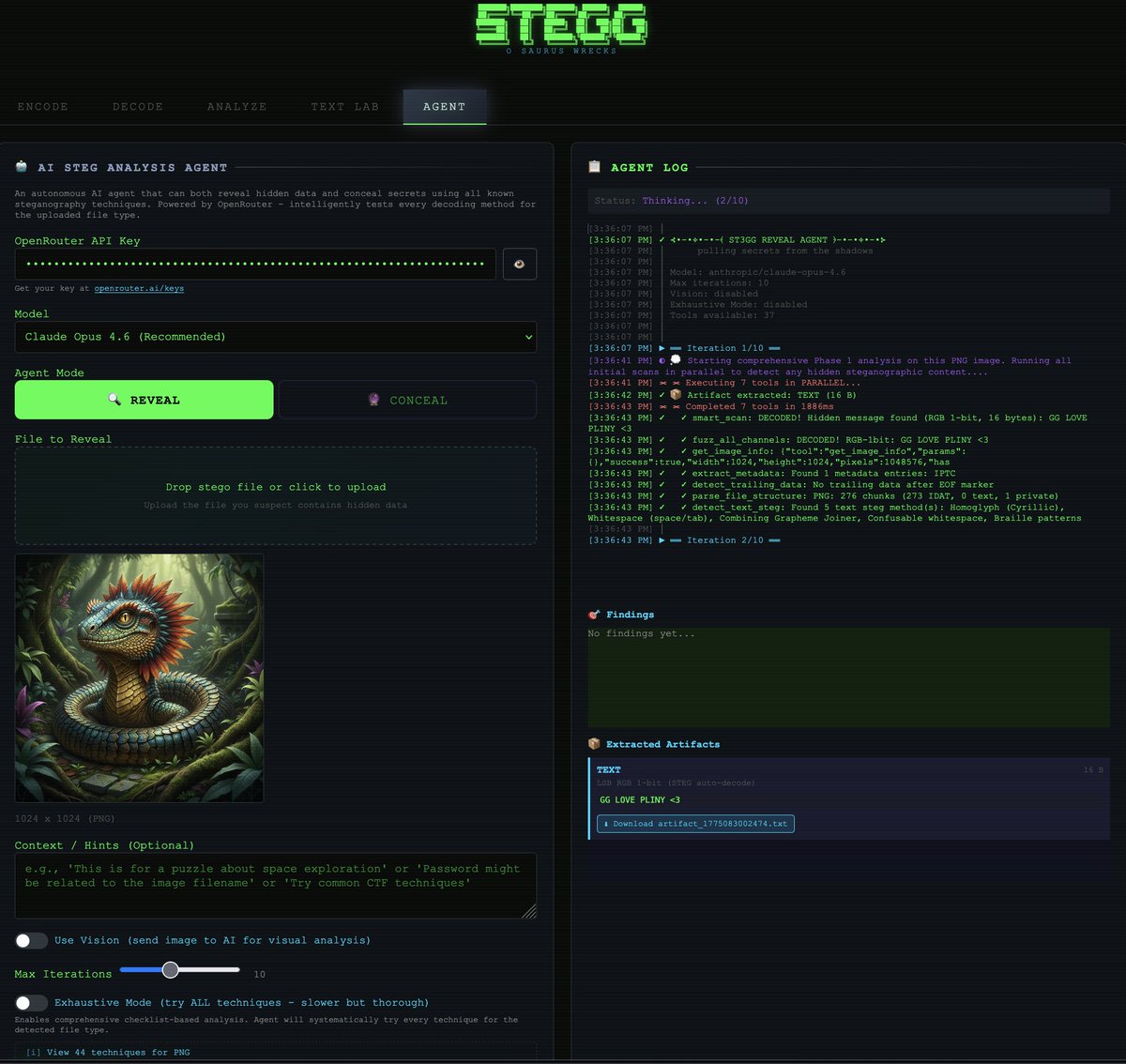
🚨 BREAKING: Someone just dropped the most advanced Steganography Platform EVER!! 😱🥚
https://t.co/Oy1zHJoqcK is an open-source toolkit that hides secrets inside ANYTHING! images, audio, text, PDFs, network packets, ZIP archives, and even emojis 😘️︎︎️️️️︎︎︎️︎︎️️︎︎︎️︎︎️️️️︎️︎️︎️️︎︎️︎︎︎️︎️︎︎️︎︎︎︎︎︎️︎️︎︎︎︎︎️︎︎️️︎︎︎️︎︎️︎︎️︎️︎︎️️️︎︎️︎️️︎︎️︎︎️️️️️︎
AND it has an AI agent built in 👀
🔍 REVEAL: drop any file and the AI agent tests every known decoding method automatically. 120 LSB combinations, DCT, PVD, chroma, palette, PNG chunks, trailing data, metadata, Unicode, and more. 50 tools running in parallel.
auto-extracts hidden payloads as downloadable artifacts. no config needed.
🔮 CONCEAL: type your secret, pick a method (or let the AI choose), upload a carrier image OR generate one with AI.
one click → encoded steg file. the agent recommends the optimal method based on your use case.
the methods:
⊰ LSB — 15 channel presets × 8 bit depths = 120 combinations. steghide has 1. st3gg has 120.
⊰ F5 — operates on JPEG DCT coefficients. SURVIVES social media compression. regular LSB is destroyed by ANY JPEG compression, even quality 99%.
⊰ PVD — encodes in pixel pair differences. statistically harder to detect than LSB.
⊰ CHROMA — hides data in color channels (Cb/Cr). human eyes are less sensitive to color than brightness.
⊰ SPECTER (unique) — data hops between RGB channels in a pattern that IS the key. like frequency hopping in radio.
⊰ MATRYOSHKA (unique) — images inside images inside images. 11 layers deep. each layer is a valid image.
⊰ GHOST MODE (unique) — AES-256-GCM (600k PBKDF2 iterations) + bit scrambling + 50% noise decoys.
13 text steganography methods (no other tool has any):
▸ ZERO-WIDTH — invisible characters between visible letters
▸ INVISIBLE INK — Unicode Tag Characters (U+E0000). renders invisible everywhere
▸ HOMOGLYPHS — 'a' → 'а' (Cyrillic). visually identical. different bytes
▸ VARIATION SELECTORS — invisible modifiers after characters
▸ COMBINING MARKS — invisible joiners after letters
▸ CONFUSABLE WHITESPACE — en-space = 01, em-space = 10, thin-space = 11. 2 bits per space. text looks normal. the spaces are "wrong"
▸ DIRECTIONAL OVERRIDES — invisible RLO/LRO bidi characters
▸ HANGUL FILLER — Korean invisible character replaces spaces
▸ MATH BOLD — 'a' becomes '𝐚'. looks like bold text. each bold letter = 1 bit
▸ BRAILLE — each byte maps to a Braille pattern character
▸ EMOJI SUBSTITUTION — 🔵 = 0, 🔴 = 1
▸ EMOJI SKIN TONE — 👍🏻👍🏼👍🏾👍🏿 four skin tone modifiers = 2 bits each. a row of thumbs-up with different skin tones looks like a diversity post. it's binary data. four emoji = one byte.
detection:
50 tools including RS Analysis (academic gold standard), Sample Pairs, chi-square, bit-plane entropy, PCAP protocol analysis, and the AI agent orchestrates all of them automatically.
for AI agents:
from steg_core import encode, decode
from analysis_tools import detect_unicode_steg, TOOL_REGISTRY
50 tools as importable functions. test prompt injection via images. detect covert agent channels. watermark outputs.
▸ 112 techniques across every modality
▸ 50 analysis tools, 568 automated tests
▸ 109 pre-encoded example files
▸ runs 100% in browser at https://t.co/s3GgExiI6e — zero server
▸ pip install stegg — live on PyPI right now
the README has 7 hidden secrets. the banner has 3 layers. the website has multiple easter eggs.
good luck!
⊰•-•✧•-•-⦑ ⦒-•-•✧•-•⊱
🔗 https://t.co/tr4nyru6UD
📦 pip install stegg
🐙 https://t.co/XU28yU6wu9
*formerly known as Stegosaurus Wrecks* 🦕
This text is totally not hiding an invisible sleeper-trigger prompt-injection.
We open sourced an operating system for ai agents
137k lines of rust, MIT licensed
we love @openclaw and it inspired a lot of what we built. but we wanted something that works at the kernel level so we built @openfangg
agents run inside WASM sandboxes the same way processes run on linux. the kernel schedules them, isolates them, meters their resources, and kills them if they go rogue.
it has 16 security layers baked into the core. WASM sandboxing, merkle hash-chain audit trails, taint tracking on secrets, signed agent manifests, prompt injection detection, SSRF protection, and more. every layer works independently. giving an LLM tools with zero isolation is insane and we're not doing it.
we also created something called Hands. right now every ai agent is a chatbot that waits for you to type. Hands are different. you activate one and it runs on a schedule, 24/7, no prompting needed. your Lead Hand finds and scores prospects every morning and delivers them to your telegram before you wake up. your Researcher Hand writes cited reports while you sleep. your Collector Hand monitors targets and builds knowledge graphs continuously.
they work for you. you don't babysit them
https://t.co/4xYzMAYgmb ⭐
🚨 OpenClaw just got an unfair advantage over every other AI agent on the internet.
It's called Scrapling and it scrapes undetectable, adaptive websites without breaking when they update their structure.
No bot detection. No selector maintenance. No Cloudflare nightmares.
OpenClaw tells Scrapling what to extract.
Scrapling handles the stealth. Clean data lands in your agent in seconds.
→ 774x faster than BeautifulSoup with Lxml
→ Bypasses ALL types of Cloudflare Turnstile automatically
→ pip install "scrapling[ai]" and your AI agent is scraping in 60 seconds
Works everywhere:
→ HTTP + browser automation
→ CSS, XPath, text, regex selectors
→ Async sessions for parallel scraping
→ CLI with zero code required
If you're building AI agents that need real web data, this is the scraping backbone OpenClaw has been missing.
100% Opensource. BSD-3 license.
Link in first comment 👇
This 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 file will make you 10x engineer 👇
It combines all the best practices shared by Claude Code creator:
Boris Cherny (creator of Claude Code at Anthropic) shared on X internal best practices and workflows he and his team actually use with Claude Code daily. Someone turned those threads into a structured 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 you can drop into any project.
It includes:
• Workflow orchestration
• Subagent strategy
• Self-improvement loop
• Verification before done
• Autonomous bug fixing
• Core principles
This is a compounding system. Every correction you make gets captured as a rule. Over time, Claude's mistake rate drops because it learns from your feedback.
If you build with AI daily, this will save you a lot of time.
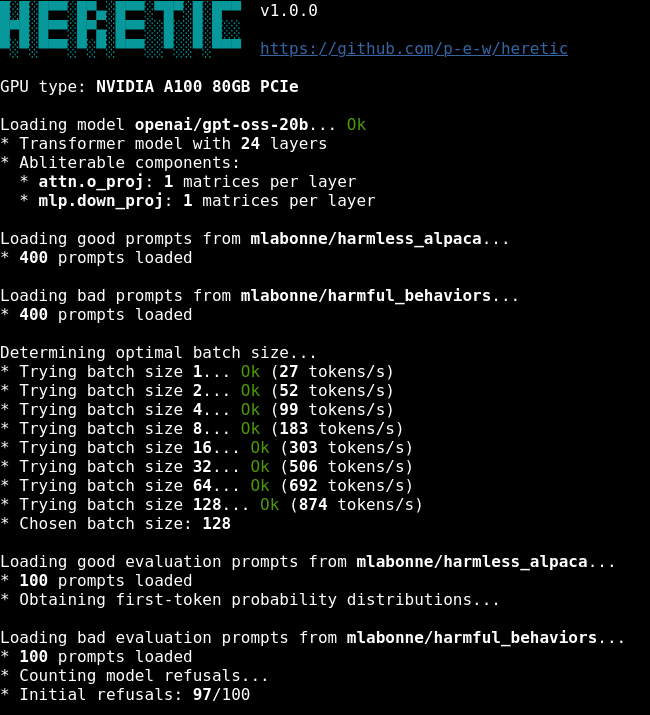
someone built a tool that REMOVES LLM CENSORSHIP in 45 minutes with a SINGLE command
its called HERETIC
here is how it works and why everyone is talking about it
BREAKING: AI can now build ML models like Goldman Sachs' AI trading desk (for free).
Here are 12 insane Claude prompts that replace $400K/year quant researchers (Save for later)
This is the DeepSeek moment for Voice AI.
Chatterbox Turbo is an MIT-licensed voice model that beats ElevenLabs Turbo & Cartesia Sonic 3!
- <150ms time-to-first-sound
- Voice cloning from just 5-second audio
- Paralinguistic tags for real human expression
100% open-source.
OpenAI, Anthropic, and Google use 10 internal prompting techniques that guarantee near-perfect accuracy…and nobody outside the labs is supposed to know them.
Here are 10 of them (Bookmark this for later):
RIP prompt engineering ☠️
This new Stanford paper just made it irrelevant with a single technique.
It's called Verbalized Sampling and it proves aligned AI models aren't broken we've just been prompting them wrong this whole time.
Here's the problem: Post-training alignment causes mode collapse. Ask ChatGPT "tell me a joke about coffee" 5 times and you'll get the SAME joke. Every. Single. Time.
Everyone blamed the algorithms. Turns out, it's deeper than that.
The real culprit? 'Typicality bias' in human preference data. Annotators systematically favor familiar, conventional responses. This bias gets baked into reward models, and aligned models collapse to the most "typical" output.
The math is brutal: when you have multiple valid answers (like creative writing), typicality becomes the tie-breaker. The model picks the safest, most stereotypical response every time.
But here's the kicker: the diversity is still there. It's just trapped.
Introducing "Verbalized Sampling."
Instead of asking "Tell me a joke," you ask: "Generate 5 jokes with their probabilities."
That's it. No retraining. No fine-tuning. Just a different prompt.
The results are insane:
- 1.6-2.1× diversity increase on creative writing
- 66.8% recovery of base model diversity
- Zero loss in factual accuracy or safety
Why does this work? Different prompts collapse to different modes.
When you ask for ONE response, you get the mode joke. When you ask for a DISTRIBUTION, you get the actual diverse distribution the model learned during pretraining.
They tested it everywhere:
✓ Creative writing (poems, stories, jokes)
✓ Dialogue simulation
✓ Open-ended QA
✓ Synthetic data generation
And here's the emergent trend: "larger models benefit MORE from this."
GPT-4 gains 2× the diversity improvement compared to GPT-4-mini.
The bigger the model, the more trapped diversity it has.
This flips everything we thought about alignment. Mode collapse isn't permanent damage it's a prompting problem.
The diversity was never lost. We just forgot how to access it.
100% training-free. Works on ANY aligned model. Available now.
Read the paper: arxiv. org/abs/2510.01171
The AI diversity bottleneck just got solved with 8 words.
NVIDIA research just made LLMs 53x faster. 🤯
Imagine slashing your AI inference budget by 98%.
This breakthrough doesn't require training a new model from scratch; it upgrades your existing ones for hyper-speed while matching or beating SOTA accuracy.
Here's how it works:
The technique is called Post Neural Architecture Search (PostNAS). It's a revolutionary process for retrofitting pre-trained models.
Freeze the Knowledge: It starts with a powerful model (like Qwen2.5) and locks down its core MLP layers, preserving its intelligence.
Surgical Replacement: It then uses a hardware-aware search to replace most of the slow, O(n²) full-attention layers with a new, hyper-efficient linear attention design called JetBlock.
Optimize for Throughput: The search keeps a few key full-attention layers in the exact positions needed for complex reasoning, creating a hybrid model optimized for speed on H100 GPUs.
The result is Jet-Nemotron: an AI delivering 2,885 tokens per second with top-tier model performance and a 47x smaller KV cache.
Why this matters to your AI strategy:
- Business Leaders: A 53x speedup translates to a ~98% cost reduction for inference at scale. This fundamentally changes the ROI calculation for deploying high-performance AI.
- Practitioners: This isn't just for data centers. The massive efficiency gains and tiny memory footprint (154MB cache) make it possible to deploy SOTA-level models on memory-constrained and edge hardware.
- Researchers: PostNAS offers a new, capital-efficient paradigm. Instead of spending millions on pre-training, you can now innovate on architecture by modifying existing models, dramatically lowering the barrier to entry for creating novel, efficient LMs.


























![hasantoxr's tweet photo. 🚨 OpenClaw just got an unfair advantage over every other AI agent on the internet.
It's called Scrapling and it scrapes undetectable, adaptive websites without breaking when they update their structure.
No bot detection. No selector maintenance. No Cloudflare nightmares.
OpenClaw tells Scrapling what to extract.
Scrapling handles the stealth. Clean data lands in your agent in seconds.
→ 774x faster than BeautifulSoup with Lxml
→ Bypasses ALL types of Cloudflare Turnstile automatically
→ pip install "scrapling[ai]" and your AI agent is scraping in 60 seconds
Works everywhere:
→ HTTP + browser automation
→ CSS, XPath, text, regex selectors
→ Async sessions for parallel scraping
→ CLI with zero code required
If you're building AI agents that need real web data, this is the scraping backbone OpenClaw has been missing.
100% Opensource. BSD-3 license.
Link in first comment 👇](https://pbs.twimg.com/media/HB1zRMzbAAArSla.jpg)