#NLP2026 では関わった3件の発表があります
宇都宮で会いましょう!
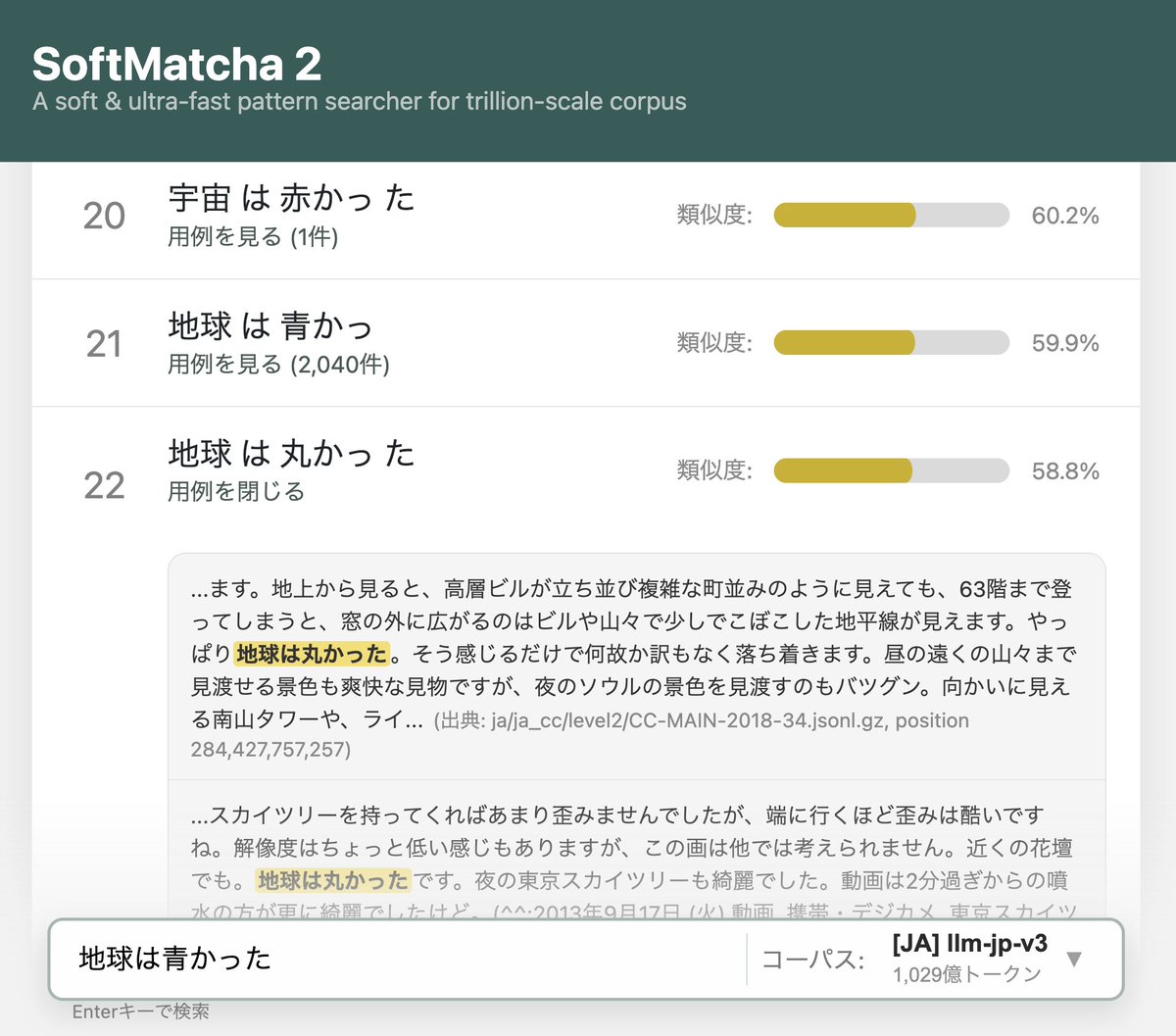
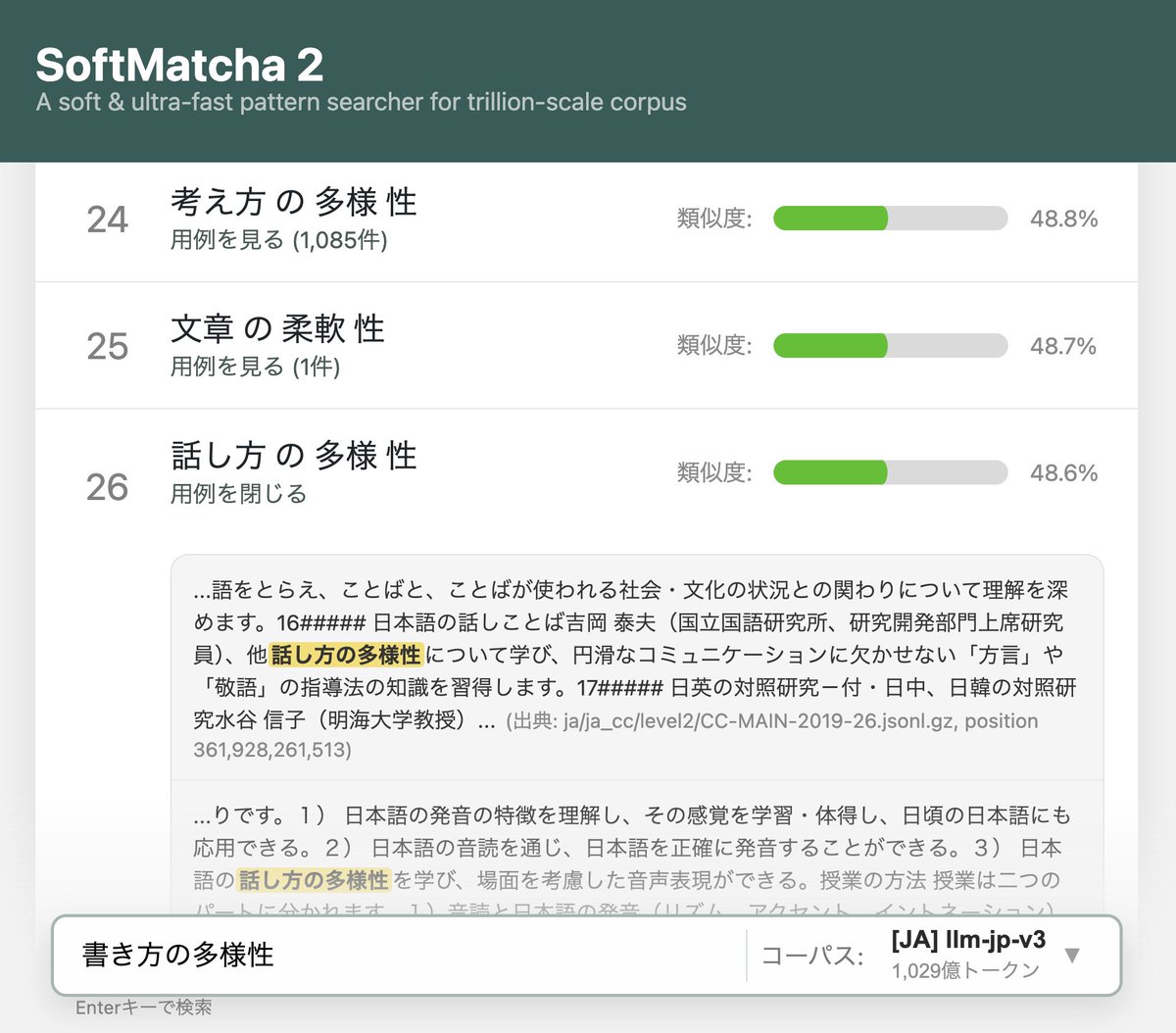
① SoftMatcha 2:柔らかいコーパス検索を1兆語規模へ拡張し、挿入・削除にも対応 (https://t.co/G2mEjNi7LT)
② Attention Sink には位置よりも自身への注意集中が効いている可能性
③ Attention sink からのValueベクトルは静的
#NLP2026 では関わった3件の発表があります
宇都宮で会いましょう!
① SoftMatcha 2:柔らかいコーパス検索を1兆語規模へ拡張し、挿入・削除にも対応 (https://t.co/G2mEjNi7LT)
② Attention Sink には位置よりも自身への注意集中が効いている可能性
③ Attention sink からのValueベクトルは静的
Introducing SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Pre-Training Corpora
https://t.co/j90flhhRzv
What lies within a trillion-scale pre-training corpus? Can you truly guarantee your benchmarks are uncontaminated simply because there are no exact string matches?
Alongside several research institutions in Japan, Sakana AI is proud to have collaborated in the development of SoftMatcha 2, an ultra-fast and flexible search tool that enables search over trillion-scale natural language corpora in under 0.3 seconds, even while handling semantic variations (substitution, insertion, and deletion). No existing tool meets all these criteria, including infini-gram-mini (EMNLP’25 Best Paper) or the original SoftMatcha (ICLR’25).
Our approach employs string matching based on suffix arrays that scales well with corpus size. To mitigate the combinatorial explosion induced by the semantic relaxation of queries, our method is built on two key algorithmic ideas: fast exact lookup enabled by a disk-aware design, and dynamic corpus-aware pruning.
As a practical application, we demonstrate that SoftMatcha 2 identifies potential benchmark contamination in pre-training corpora that existing exact-match approaches miss.
You can try searching through a 100B-scale corpus via our online demo. The system remains blazingly fast even on trillion-token corpora, so we encourage you to host it yourself for larger scales.
Demo: https://t.co/6bbZjh2JnS
Paper: https://t.co/aXea33SGjK
Code: https://t.co/Y1A8o5u6Hf
This work is a collaboration with researchers from the University of Tokyo, NII, Kyoto University, SOKENDAI, NINJAL, Tohoku University, and RIKEN.