Home
Language
English
Türkçe
Bahasa Indonesia
About
Privacy Policy
Terms of Service
Pricing
Sign In
Download All
Share
peter
@gonewithwill
Joined September 2021
334
Following
74
Followers
6.2K
Posts
gonewithwill
retweeted
Herman Jin
@ShanghaoJin
1 day ago
凡所有相,皆是虚妄。若见诸相非相,则见如来 作为一个AI死多头,我知道在所有人狂欢的时候,但凡发出一点悲观的言论都必被讥讽、嘲笑 但是,我很想写此文,其实是复盘与反思:不但是为自己这两年半写X、做交易做的;也是也是对这个疯狂市场做的 很幸运,作为闲暇的爱好,写X结识了很多新朋友。感谢互相欣赏与启发,在过去2年里,我从24年4月初清仓BTC换成AVGO NVDA,大选前AAOI PLTR TSLA INTC,关税战后INTC GOOG,25年底又加仓INTC AAOI,到今年春节逃跑、再满仓AMD NOK(最近又操作了ORCL LITE)。虽然,有买彩票SUP归零,MRVL MDB也有赚有亏,但是我一直坚信AI对token的需求会让半导体every dog has its time,获得了不差得收益。期间不少小伙伴们也都赚到不少于10倍收益 然而,此刻要清醒的意识到,收益并不是我们选股牛,眼光独到,而是市场牛!我复盘了我自己今年3月最后一周,周末前全仓买入。赚钱并不是因为当时买对了AMD,而是当时call 对了市场资金结构 所以,在这个时点上更需要静心凝神,好好反思下市场接下去会如何 喝醉酒的人是不会知道自己喝醉的;沉醉美梦中的人也不会意识到黄粱一梦,这过程可以很久,我们也可以继续疯,但是必须要清醒地在更高阶意识中,认识到随时有被敲醒的风险 One of the four beasts saying, COME AND SEE – Revelation 6:1 不同于华尔街很多人,我是“坚信”AI的 30年来第一次,AI模型用并行计算替代串联计算,把半导体的进步直接变成了生产力(之前科技进步只是作为平台,让用科技的软件、以及用软件的人创造价值) AI的结果是token需求指数级升高vs 而半导体供应只能线性增加。加上整个半导体老登们在过去几年黄金时间,没有因 “信” 而扩产,今年需求真正开始爆发后全产业链缺货。造就了这轮大牛市 不过,大牛市的命脉是市场price in了: 模型收入加速度,不远得未来可以justify Hyperscalers 的Capex 要知道任何动摇命脉预期的都会让市场陷入恐慌 1. 铜墙铁壁:horseman之一就是微观、公司层面真的无懈可击 从看模型架构、从架构看需求,微观看半导体每一个赛道,每一个公司都近乎完美。每一个,都越看的细致,越了解深入,越是有自信---- 这就是典型低PE泡沫 Rule of Thumb:当看了几十、上百家公司,每家需求、盈利都真实solid,你就必须质疑这个市场有没有问题 低PE泡沫一样是一个泡沫,只是他不同于2000年。高PE是个预期泡沫,市场会不停设定更高的收益预期,一旦核心公司预期破灭,整体预期立即调整,多米诺骨牌一样一片片倒下。这就好像去年的IGV,市场忽然不给EV/EBITDA估值了 但是低PE泡沫没有这个问题,盈利增长会给你足够信心在稍微下跌之后不断加仓冲进去。毕竟谁能拒绝个位数PE的存储,每年涨价涨盈利,毛利率80%。这个过程中,小跌小买,大跌大买。只要不被切中“命门”市场会非常坚挺。持续性正反馈,好像美梦一样让人不愿醒来,也不相信是做梦(买过p2p的知道我说的什么感觉吧) 不对称反馈:明显的体验是在过去1年中,市场对于宏观负面风险的反馈明显弱于正面利好。此时,并非没有“野蛮人”,而是公司盈利能力的城池固若金汤。不管伊朗危机、油价、通胀、利率、Fed统统能拒之门外。反之,一旦命门被破,所有野蛮人都会杀回来,过去没跌的够的一次性补完 2. 去监管与宏观流动性宽裕: 整个金融体系自从2008年金融海啸之后经历了一轮长期的监管与去杠杆,为了弥补系统性流动性损失美联储对应展开了一轮持续的QE。银行当时平均杠杆x30~x40,后来降低到了x15~20。去年美联储降低了eSLR要求,实质性让银行理论可扩4-5万亿美元资产负债表 其实,4月后银行间流动性泛滥,也加剧了风险资产狂欢,低PE下杠杆入市 流动性是一切之王,流动性泛滥征服一切。如果说疫情期间120b/月是细水长流,现在就是开闸放水。对应过往平衡的QE没有转向QT情况下,直接放任银行去监管,制造大量流动性 但是流动性又如多巴胺,不是快乐分子,而是期待分子 放任之后,现在通胀黏着,Fed其实没有短期降息余地。甚至在危机一旦发生之后,都很难去QE,只有降息手段的Fed面对可能的危机是一个纸老虎。而短期流动性的另一面是,目前半导体、特别是存储中的杠杆已经太高了 3. 群雄并起:He went forth conquering, and to conquer 可能因为TSMC带头不相信AI,半导体行业整体在过去2年没有应对AI需求大规模扩产 后果是,当整个产业面临硅基洪流需求,忽然傻眼。过去半导体产业链主要是为了消费电子设计、定价的。而现在,不但订单忽然拉满,而且需要不停迭代架构 NVDA就从GPU fabless,进步到rack方案解决,再往token factory迈进。每个过程需要的技术、供货商都不同。所有供货商都没有经过如此量产设计。这就好像把一台拖拉机强行拉上高铁,让他以200mile速度奔驰,每个零件都会嗡嗡作响。半导体每个细分行业都缺货,缺产能,提高不够产能 与之伴生的一个问题是:原来卖方市场只有TSMC一个“守门员”控货源、控margin、控价格。原仔汤搓的产业有肉吃,需求方对价格产能有预期,良性发展。今天忽然五亿探长“雷诺”控制不住了,每个“小混混“都能来涨价、收保护费。真正的结果不是半导体都牛叉,而是失控:失控会影响每GW需要投入的成本核算,影响到命脉的预期。会给capex与模型收入会师蒙上阴影 4. 钢丝起舞 AI模型收入预期太满 回顾一下,市场坚信定价Anthropic + OpenAI + Gemini的收入会快速增加让Capex合理。这条命脉的信仰是不能有一点动摇的。哪怕略微的动摇都会导致二级市场剧烈波动 那么,过去GPT 5.0也有模型不及预期,市场质疑scaling law为什么没有让半导体大跌? 首先当时半导体没有像今天这样全面开花,也没有如此高的杠杆;其次,当时hyperscaler的现金流冗余较多,只要他们表示相信,拿钱来capex支持是很容易度过难关的。毕竟一旦他们有钱、继续capex,可见2年NVDA收益确定性高,没有人能顶风做空NVDA的 后来也发生过GPT被Gemini追平,并且导致Orcl持有其大量backlog订单而被做空。不过大总统的好兄弟老Larry敢对wall street说F you,用股权融资也要继续加注。很快, Opus横空出世让人意识到AGI时代已经到了 然而,今年capex已经到了770b,明年要1tril,华尔街是不会看Hyperscaler总营收多少的(道理就跟当时ORCL一样:OAI Anthropic可都是拿了他们投资款的),他们必须看到Anthropic 与OAI的增速持续,这个才是维系整个链条自转下去的核心 与此同时,这个游戏中大厂一直担任AI的监护人角色。但是他们的自由现金流已经变负了。“父母老了,力尽了“,后面的路要靠自己。而且市场满满预期下,对这条路一根筋的执着,不会给“主线”一丝一毫的容错 (你们可以回想NV rack液冷出问题,交换机CPO良率问题,这些小巫见大巫、假以时日一定能解决的问题,市场尚且没有任何容错) 命门在Anthropic:大过,大者过也。栋桡,本末弱也 供应延迟、乃至技术卡壳的问题是腠理之疾;任何模型端的风吹草动才是心腹大患 现在御三家模型的统一问题:算力不够,所以失智 我在自己大量使用模型编程、交易程序部署,多个AWS服务互动过程中发现,Opus4.8实际能力已经远远不如中国模型kimi了。虽然GPT还勉强可堪一用,但是也在逐步降智。市场在用固有软件思维考虑AI, 系统开发成本高、使用成本很低。试用好用将来也就可以稳定保证系统质量。但是AI是一个工厂,模型输出需要成本,饭店吃饭的人多了,厨房做不过来,质量自然变差了 第二个市场固有思维:指数的token需求是没有波动的,也不因质量改变。事实上,虽然我因为模型变蠢多用了很多token。但是我质疑token质量不断下降,token消耗增加的怪异剪刀差可以持久。现在很多公司确实对token使用有KPI考核,很多惯性订阅使用者也会加速使用,但如果算力瓶颈无法解决,我非常担心Anthropic增长曲线会变缓。而且算力问题非一蹴而就,也不是一个新模型能解决的 但是当市场开始意识到这个问题的时候,投资人会质问: 1. 跑不过蒸馏你的,模型花那么多钱训练干嘛? 2. 模型是不是商品化的model commoditize ? 当承载整个AI时代的模型“梦”也将受到质疑,整个盈收逻辑将来能否自我循环跑通将被质疑,所有今天拿了PE估值的半导体都同样会被质疑--- 你是不是周期性的?? 有人会说,失智既然因为算力不够就应该加大投入半导体解决问题 没错!但是钱呢? 如果刨掉OAI 与Anthropic拿到的融资款反哺云厂,他们能有多少净现金流可以继续支持这个投入?这个账对华尔街来说非常好算。当然不排除他们像当时orcl,哪怕融股权也要继续投入,熬过这关。到那时,可能市场的反应就会远远超过去年,假设AMZN Meta如果面临CDS 飙升、负现金流,他能否像老larry一样孤注一掷是不确定的 另外有人会说,OAI收入增加能不能弥补投资人担心。我认为预期如此之满的状况下,因为“比烂”而被替代是很难让人安心的(两军对战关羽被阵斩了,你说还有个张飞?没用的) 同时,我们也要意识到。这个Low PE的泡沫又是非常坚韧的,在没有直击到命门伤到命脉预期之前,几乎无敌。不过,一旦点中死穴就会轰然倒塌 我就业以来也曾看过好几次次纸碎金迷,潮起潮落,没有一次全民疯狂会ends well; 也没有一次梦在其中的人,会想明白这个赛道“怎么输”。最近一次币圈小伙伴熟悉的Defi summer。Uniswap很短时间狂卷几十bil USD,当时觉得取代部分传统金融只是时间问题、多少问题,根本不会想、也想不明白“怎么会输”。然而,如果喝醉酒的人想明白怎么会输,他就不会输了 不管Anthropic模型怎么样,面临什么问题,都不会动摇AI是人类第三次工业革命。AI过程不会受任何危机影响,碾着狂欢者的尸体也会继续前行,直到他替代几亿脑力劳动者 最后评论Low PE泡沫:不要说做空,哪怕踏空,痛苦指数都非常高。回头看看2007年做空subprime的哪些基金,有几个活到了最后狂欢? 牛市踏空都会变成笑柄的环境,我接下去会需要很多Aura力量与专注的力量,去一边看空一边做多。请原谅会减少在推特上消耗自己修为论道了,赠言: 可以喝酒,但是不能喝醉 可以讲故事,但是不能真信 可以跳上party桌子跳舞,但是双眼必须紧紧盯着DJ,他放着音乐跑了,你也得跟着跑
See More
gonewithwill
retweeted
鱼总聊AI
@AI_Jasonyu
1 day ago
我是万万没想到现在 ChatGPT 开个会员。门槛也这么高了?? 我的 Payonner卡、Pingpong卡、国内的 Visa 卡,全部都被拒绝了。 除了礼品卡,大家用什么卡支付的目前?
peter
@gonewithwill
1 day ago
@edward40e
啊,不能拆个开源的吗
gonewithwill
retweeted
yibie
@yibie
3 days ago
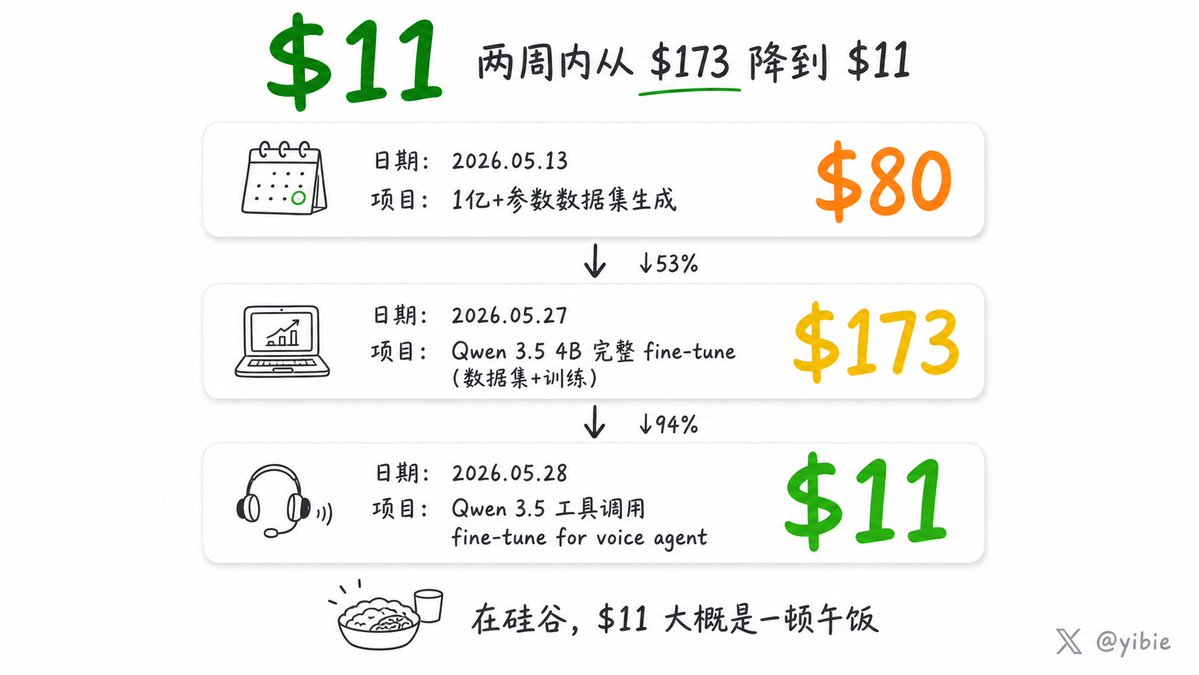
训练小模型:2026 年最被低估的 AI 技能 2026 年 5 月 11 日,一个叫 CJ Zafir 的人发了一条推文。他想教普通人 fine-tune 开源模型。 2538 个赞,316 次转发,178,000 次观看。这条推文炸了。不是因为他发明了什么新东西——Unsloth 早在 2023 年就开源了,Hugging Face 上的 fine-tuning 教程有几百篇。炸了是因为他在一个所有 AI 公司都在比赛造「更大模型」的时候,反手指向了完全相反的方向:小模型。你自己训练的。在 Colab 上。花几十美元。 两个月过去了。CJ 没有停。 他把这条推文变成了一套完整的方法论:Codex 5.5 做大脑规划工作流,DeepSeek v4 Pro 做肌肉批量生成数据,Unsloth 做训练引擎,Qwen 3.5 4B 做基座模型。然后他用这套方法论,花了 $173 训练出一个 4B 模型,在垂直任务上精度 96%+,击败了 20 倍大的模型。 再后来他做了个 voice agent 的工具调用 fine-tune——成本 $11。 从 $80 到 $173 到 $11。这不是渐进式优化。这是在重置整个 AI 部署的经济学。 一、CJ 方法论:为什么值得认真对待 CJ 不是第一个倡导 fine-tuning 的人。但他做对了一件事:他把整个流程的成本打到了个人开发者可以承受的水平,并且公开了每一步。 工具链 | 角色 | 工具 | 成本 | |------|------|------| | 规划(Orchestrator) | Codex 5.5 | 订阅内 | | 数据生成(Generator) | DeepSeek v4 Pro | API 按量 | | 训练框架 | Unsloth | 免费开源 | | 训练硬件 | Google Colab Pro A100 80GB | ~$0.60/hr | | 推理部署 | llama.cpp / Ollama | 免费 | 数据流水线 CJ 最核心的洞察不是「用什么工具」,而是「怎么造数据」: 「"Low quality data = Low quality model performance"」 他的流水线是自进化的:Codex 设计工作流 → DeepSeek 批量生成数据行 → 每批次过 Quality Gates → Codex 根据上一批结果优化生成规格。结果是越跑越快、越便宜、质量越高。 $80 生成了 1 亿+参数的高质量数据集。 不是简单 paraphrase,是「手工打造」每一行——Codex 设计的多样化 prompt 模板 + DeepSeek 的高速执行 + 可编程的质量门槛。 模型选择 CJ 实测了 Gemma 4 和 Qwen 3.5 全系列后,结论很明确: 「Qwen 3.5 9B 和 4B 是垂直训练的完美基座模型。Gemma 4 在垂直任务上不及 Qwen 3.5。」 他的 Qwen 3.5 4B fine-tune 在精度和延迟上击败了 20 倍大的模型。不是什么小众 benchmark——是他自己在垂直任务上实测的结果。 二、这不是 CJ 一个人的实验——行业数据在同时发声 CJ 的方法论看起来像「个人黑客技巧」,但独立的数据正在从各个方向验证同一个趋势。 市场规模 SLM(Small Language Model,1B-13B 参数)市场 2024 年达到 65 亿美元,年复合增长率 25.7%。SLM 在大多数企业任务上已经匹配或超过 GPT-3.5 级别性能,只需一小部分成本。 性能 阿里巴巴的 Qwen 3.5 9B 在 MMLU-Pro、GPQA Diamond 和 multilingual MMMLU 三个基准上击败了 OpenAI 的 gpt-oss-120B——13 倍参数差距,小模型胜。 另一项独立的 brand normalization 案例中,一个小模型达到了 90.6% 准确率,超越了 GPT-5.2 和 Gemini 3 Pro。 企业已经在省钱——真正的省钱 | 公司 | 方案 | 效果 | |------|------|------| | Knowunity | 用 Distil Labs fine-tune SLM | 推理成本降 68% | | 某客服 agent | 从通用大模型切换到 fine-tuned SLM | 月成本从 $13,000 降到 $400 | | EliseAI | 专门训练的垂直小模型用于住房和医疗 | 推理成本降 60%,延迟降 80% | | AT&T | 专用 SLM 做客服和欺诈检测 | 数百万美元节省 | 400 美元一个月。一个客服 agent。这是几个工程师的年收入可以覆盖无限次 API 调用的部署方案。 三、「数据集工厂」才是真正的护城河 CJ 在 5 月 22 日发了一条推文,八个词: 「"The moat might not be the fine-tune itself. It might be the dataset factory."」 这是整个小模型运动最重要的洞察。Fine-tuning 技能本身正在被民主化——Unsloth 已经能在 3GB VRAM 上训练,Colab 免费提供 GPU,CJ 连 prompt 模板都公开了。当人人都能做 fine-tune 的时候,差异化从「会不会做」转移到了「数据从哪里来」。 中文社区的 AKIRAXCLAW 在一篇分析里补了一个关键观察: 「「CJ 的工作流在 2026 年多数是业界共识,但真正难点不是工具——而是你有没有 200 笔干净数据 + 自动评估脚本。」」 在 CJ 的体系里,Codex 的核心角色是 orchestrator,不是因为它比 DeepSeek 聪明,而是因为它能设计数据流水线、构建 Quality Gates、自进化优化生成规格——它在管理数据生产的质量系统,而不仅仅是生产数据。 四、从边缘到生产线:部署已经在发生 SLM fine-tune 的部署门槛已经降到消费级硬件。Unsloth 2.0 支持 GGUF 量化导出 + llama.cpp / Ollama 部署。一个 3B 参数量化到 INT4 后占用 1.5-2GB 内存,可以在树莓派 5 上运行。Qwen 3-0.6B 在 Pixel 8 和 iPhone 15 Pro 上实现约 40 tokens/s 推理。 2024 年你可能需要一台 A100 才能跑 fine-tune。2026 年你可以在 Colab 上训练、在手机上推理。这种从「数据中心才能碰」到「个人设备上运行」的变化,是 Platform Shift 级别的。 而 NVIDIA 在推动的「Data Flywheel Blueprint」——用生产流量持续生成训练数据,自动 fine-tune,自动部署——正在把这个流程变成企业基础设施。NVInfo AI 用这个方案在三个月内把内部知识助手的质量提升到覆盖 30,000 名员工。 五、成本轨迹:从「公司预算」到「午饭钱」 CJ 的公开成本记录是最好的注脚: | 日期 | 项目 | 成本 | |------|------|------| | 05-13 | 1 亿+参数数据集生成 | ~$80 | | 05-27 | Qwen 3.5 4B 完整 fine-tune | ~$173 | | 05-28 | Qwen 3.5 tool calling for voice agent | $11 | $11。这在硅谷大概是一顿午饭。在印度、东南亚、非洲,是一个独立开发者完全负担得起的预算。fine-tune 已经从「大公司才有资格做的研发项目」变成了「个人开发者用午休时间能完成的 side project」。 六、结论:学会训练你的第一个模型 CJ 给的学习路线图异常简单: 1. 从 1B-4B 小模型开始,不要一上来就搞大模型 2. 用 Colab Pro(A100 ≈ $0.60/hr),不要急着买 GPU 3. 先 fine-tune 7-10 个模型积累经验(SFT → LoRA/QLoRA → GRPO/DPO) 4. 用 Codex 做规划,DeepSeek 做数据生成 5. 理解量化(GGUF)、本地推理(llama.cpp)、KV 缓存 他甚至在 5 月 23 日直接发布了一个「复制粘贴就能用」的 prompt——把整个学习路径封装成一段对话,扔进 Codex 或 ChatGPT,让 AI 带你从 beginner 到 advanced。 这就是 2026 年 AI 技能民主化的真实面貌:不是每个人都需要学会训练模型。但学会训练小模型的人,不再需要 10 人团队和 10 万美元预算。 通用大模型的军备竞赛还在继续。GPT-5、Claude Opus 5、Gemini 3 会越来越强。但越来越多的真实场景正在证明:一个花了 $173 训练的 4B 小模型,在你自己的数据上,比你花 $200/月订阅的通用大模型更好用。不是因为小模型更聪明。是因为它只做了你需要的那一件事。 参考来源:CJ Zafir X 推文系列 (2026.05.11-05.28);AKIRAXCLAW 中文分析;Alibaba Qwen 3.5 benchmark (VentureBeat);Unsloth 2.0 文档;NVIDIA Data Flywheel Blueprint;AT&T / EliseAI / Knowunity / https://t.co/7r0fApoHPJ 企业案例;Manicode / Arendil 独立 benchmark;SLM Market Report 2024-2026
See More
Who to follow
Mir5
@mirpangh
Near1991
@BerhaneB91
footballer
Kosmic.Kin
@Toddylee1
Truth seeker Kin and Code
gonewithwill
retweeted
ريان || Rayan
@Trend_A9
4 days ago
شخص ثري قال لي مرة : "المال يحب الماء." أخذ مني الموضوع سنوات لأفهم...
gonewithwill
retweeted
小盖
@xiaogaifun
20 days ago
强烈安利这个讨论 AI Coding 方法的演讲。 AI Coding 工具正在同时被过度低估和过度吹捧。 关于 Vibe Coding,看到的都是类似的说辞:编程已经没有门槛,用自然语言说出自己的想法,就能够写出一个软件。 另外一方面,真正用 AI 写过成体系代码的工程师都会发现,AI 确实非常强,但它也容易把代码库变成一坨没人敢动的屎山。 前段时间在 AI Engineer 大会上,资深工程师 Matt Pocock 做了一个分享,标题挺反共识的,叫 Software Fundamentals Matter More Than Ever。 软件工程基本功在 AI 时代不仅没过时,反而比以前更值钱了。 这句话第一眼看上去像是老工程师的精神胜利法,但听完他的论证再回头看自己用 AI 写代码踩过的坑,会发现讲的全是实话。 下面我分享一下我的感受。 1 很多人对 Vibe Coding 的理解是,随性地跟 AI 聊,用自然语言表达想法。哪里有 bug 或者跑不通,继续让 AI 改就行,反正 AI 已经很强了。 如果只是做一个小工具,用户量不大,那这套打法绝对没问题。但如果你想做的是一个大中型系统,那完全就是另外一回事了。 懂代码的人深入看一眼就会发现问题。Vibe Coding 第一遍 AI 生成出来的代码还行。第二遍质量下降一点。 第三遍更差。几轮下来代码库的可维护性会变得很差,逻辑散落、命名混乱,连 AI 自己再回来读都得绕半天。 《程序员修炼之道》这本老书里有个词准确地描述了类似的现象:软件熵。 熵增是宇宙基本规律,万事万物都倾向于变得混乱。软件也一样,每次改动只盯着眼前这一处,不考虑整个系统的设计,代码就会一点点烂下去。 AI 生成代码的速度比人快十倍,这意味着熵增的速度也快了十倍。 Vibe Coding 这套打法的底层假设是一句话:代码很便宜。但这个假设错得离谱。代码从来不便宜,烂代码反而比以前更贵了。 为什么这么说,因为 AI 在好代码库里能跑得飞起,在烂代码库里寸步难行。 想象两种场景。一种是代码库结构清晰、命名一致、模块边界明确,AI 接到任务能很快找到该改哪里、不会改坏什么。 另一种是代码像一锅乱炖,同一个概念有三种叫法,逻辑散落在十几个文件里,AI 每次改动都得先猜半天,改完还经常牵一发动全身。 在第一种代码库里,AI 是杠杆,把产出放大十倍。在第二种代码库里,AI 是放大器,把混乱放大十倍。 这就是整件事的核心:AI 是复杂度放大器,不是复杂度清洁工。 那问题来了。既然 AI 会天然放大复杂度,那真正该做的事情是什么? 答案是主动给代码库加秩序。 这时候。那些老掉牙的软件工程原则和方法,在 AI 时代不是变得过时了,而是第一次变成了真正的生产力。 2 很多人用 AI 写代码的第一感觉是,怎么 AI 做出来的不是我想要的。 明明指令也下了,要求也说了,做出来的东西就是差点意思。然后再补一句 Prompt 调整,再差点,再补一句,几轮下来开始怀疑人生。 软件这行有句老话,没人真正知道自己想要什么。 解决方案有两个,都是开工前的功夫。 第一个叫 Grill Me。 让 AI 反过来盘问你。Prompt 简单到就一句话:围绕这个计划的每个细节相关地审问我,把设计树的每个分支都走一遍,把依赖关系一个个理清,直到我们对要做的事达成共识。 这个仓库在 GitHub 上拿了一万三千多颗星,可见多少人有同样的痛点。 实际用起来什么效果,AI 会问你四十个、六十个、有时候一百个问题。问到后来自己都觉得烦,但就在这种烦中,原本以为想清楚了的需求,会被它逼出一堆没考虑到的角落。 《人月神话》的作者曾经讲过一个观点:两个人一起设计一个东西,他们之间会有一个看不见的共同理解,那个理解不在任何文档里,就在两个人的脑子里。 如果这个共同理解没建立,两个人各自走各自的方向,最后做出来的东西必然对不上。 人和 AI 之间也一样。你以为说清楚了,AI 以为听明白了,其实双方脑子里想的根本不是同一个东西。 Grill Me 干的事就是把这个隐形的共识显形化,让双方的脑子在动手之前先对齐。 第二个方法叫 Ubiquitous Language,通用语言。 这是 DDD 里的老概念。DDD 是什么,我不展开了,不熟的同学可以去搜一下。最近 Vibe Coding 比较多,我又再次意识到十年前学的 DDD 有多重要。 举个例子。一个电商项目,运营那边把订单叫做单子,客服那边叫订单,技术那边在代码里写 Order,数据库表叫 trade_record。这次 Prompt 用了订单,AI 就写一个 order_service。 下次 Prompt 用了交易,AI 又写一个 trade_handler。过几轮回头看代码,发现同一件事在三个文件里有三种命名,调用关系绕来绕去。重构一次得改半天。 通用语言的做法很简单,维护一个 Markdown 文件,列清楚项目里所有关键概念的精确定义,哪些词不要用,命名规则是什么。然后让 AI 每次工作前先读这个文件。 效果挺明显的。观察 AI 的思考过程会发现,术语对齐之后,AI 想问题的方式都不一样了,输出更精准,写出来的代码命名也更一致。 把这两件事放一起看,会得到一个挺反直觉的结论:和 AI 协作里最贵的成本,不是写代码的时间,是消除歧义的时间。 前面花十分钟跟 AI 对齐清楚,后面能省两个小时的返工。这笔账怎么算都划算。 但人有种本能,看到 AI 能写代码,就想赶紧让它开始写,先跑起来再说。 这种心态在 AI 时代会被反复教训。 3 意图对齐之后,下一步是怎么让 AI 实际干活。 这里有两个关键的节奏控制方法,垂直切片和 TDD。 先说垂直切片。 很多人用 AI 的姿势是这样的:给我做一个任务管理系统,要有用户登录、任务列表、提醒、协作。 然后 AI 开始一通生成,前端、后端、数据库、接口,一口气出来几十个文件。 这种打法有点像先横着铺架构,前端、后端、数据库、接口都先摆出来,再一层层往里填。问题是哪一层都没填完,哪一层都跑不通,想验证某个具体功能能不能用都不知道从哪儿下手。 更靠谱的打法叫垂直切片。 从一个具体的用户场景切入,比如用户能创建一个任务并在列表里看到它。 围绕这个场景,从前端的按钮到后端的接口到数据库的存储,竖着打通一条完整链路。这条链路能跑通了,再做下一片。 这么做的好处特别实在。每一片代码量都不大,能看懂 AI 在做什么。 每一片做完都有一个能演示的成果,业务价值看得见摸得着。出了问题改动范围有限,不会牵一发动全身。 用得好的人都在做精细手术,一片一片地打通。用得差的人都在让 AI 拿电锯推楼,看起来气势大,结果一片狼藉。 切片切对了方向,每一片里面也不能让 AI 一通乱写。这里就要用到 TDD,测试驱动开发。 AI 写代码默认是一种很冒进的状态。给它一个任务,它会一口气写一大堆代码,写完才想起来要不要类型检查一下,要不要跑个测试。 这时候已经晚了,错误已经扩散到很多地方,找起来非常痛苦。 《程序员修炼之道》里有句话说得贴切,反馈的速度就是你的速度上限。反馈跟不上代码生成的速度,迟早翻车。 TDD 干的事是给 AI 装一个限速器。先写一个测试描述期望行为,让 AI 实现这个测试能过的最小代码,跑通,再写下一个测试。 AI 被强制一小步一小步走,每一步都有验证,跑偏了立刻就能发现。 这里有个心态上的变化值得说说。以前是人写代码再补测试,测试是写完之后的事情。 现在更像是人设计测试和行为,AI 去把实现填满。测试从事后检查变成了事前约束,从安全网变成了方向盘。 AI 不缺速度,AI 缺的是约束。约束是人加的。 4 活动现场,Matt 问现场的程序员,有多少人觉得自己比以前更累。台下很多人举手了。 AI 不是号称可以提高效率吗,怎么用了 AI 反而更累。 原因其实很简单。AI 产出代码的速度,已经超过了人脑处理这些代码的速度。能写出来不等于能看懂,能跑通不等于能维护。 而代码库的组织方式,直接决定了这种过载有多严重。 如果代码库里全是浅模块,AI 写得越多,人需要装进脑子的东西就越多。 每个模块接口都不一样,调用关系绕来绕去,想看懂 AI 改了什么,得把整张地图重新理一遍。AI 在跑,人在喘。 解法是回到一个老概念,深模块,Deep Modules。这个概念出自斯坦福教授 John Ousterhout 写的《软件设计的哲学》。 什么叫深模块。一个模块对外暴露的接口越少越简单,内部封装的复杂度越多,这个模块就越深。 举个例子。要发邮件,深模块的做法是对外就一个函数 sendEmail(收件人, 主题, 正文),调用方填三个参数就完事。 这个函数里面要做的事其实一大堆,连服务器、认证、组装邮件头、处理重试、关闭连接,但这些细节全部藏在模块内部,外面看不见。 浅模块的做法是把这些细节一个个暴露出来,对外给六七个函数,调用方得自己按顺序调用。 注意,深模块不是说一个函数里塞很多东西,那是反面教材。 深模块讲的是整个模块对外的接口少而干净,内部该拆几十个小函数就拆几十个小函数,但拆出来的小函数是模块内部的事,不暴露给外面。 AI 天生爱生成浅模块。让它写代码,它倾向把内部步骤一个个变成对外函数,看着 DRY,实际上把内部复杂度泄露给了调用方。 深模块的好处是人可以把模块内部当成灰盒看。接口设计清楚了,行为有测试盖着了,里面怎么实现的日常不用盯每一行,需要的时候再掀开看。 这部分脑力就省下来了,省下来的脑力放在更上层的事情上,模块边界画得对不对,接口够不够清晰,整体架构有没有走样。 人的大脑能装的东西是有限的。AI 把代码生产速度推上去之后,这个有限性就成了瓶颈。 深模块的本质是给大脑减负,让人不用把整个系统的复杂度都装进脑子才能干活。 到这里,AI 时代开发者的角色就清楚了。 AI 是手脚极快的实施兵,能把活干得又快又多。但实施兵需要有人指挥,得有人在更上面盯着系统该往哪儿长。这个人就是开发者。 这种分工下,开发者每天该投入的不是敲键盘的时间,是想清楚系统该怎么设计的时间。 写到这儿,开头那个反共识的结论可以收一下了。 AI 正在把程序员从代码工人推向系统设计师。生成代码这件事,AI 已经接手了大半。 人剩下的价值集中在四件事上:画清楚模块边界,控制系统的熵增,设计反馈的回路,统一整个系统的语言。说到底是一件事,管理复杂度。 会写 Prompt 只是入门,能管复杂度才是真本事。 5 前面这些原则,通用语言、垂直切片、TDD、深模块,单拎出来没有一条是新的。每一条都能在二十年前的工程书里找到出处。 这正是这场分享真正想讲的事。 Matt 在开场说过一句话,这场 talk 是讲给那些觉得自己的技能在 AI 时代不再值钱的人听的。 台下很多是干了十年、十五年、二十年的开发者,看着 AI 一夜之间能写代码,会下意识觉得自己被淘汰了。 但他要表达的其实不是替老工程师找补。他真正想讲的是另一件事。 即便 AI 的能力已经这么强,写代码的速度这么快,那些过去几十年攒下来的软件工程原则,仍然需要被一代一代的开发者认真学习、认真理解。 这些原则不是历史遗产,是真正构成判断力的基石。没有这些基石,就驾驭不了 AI 写复杂代码。 AI 时代有一件事翻转了。以前稀缺的是手快的人,能一晚上撸出来一个原型的程序员很厉害。 AI 把手快这件事变成了基础设施,稀缺性整个反转过来,反转到了对代码的驾驭上。 所以这场分享真正想说的是,AI 不是让软件工程让这门功课变得比以前更重要。 老工程师过去几十年学的那些东西没白学,年轻开发者今天该学的那些东西也没法跳过。 AI 能帮人写代码,帮不了人去理解什么是好代码。 编码容易,测试也容易。架构、设计和品味,才是真正有价值的事。
See More
peter
@gonewithwill
4 days ago
@Kai866
想象力的
peter
@gonewithwill
4 days ago
@alexhyzhang
@ixiaowenz
专业和脑子是两码事
gonewithwill
retweeted
Vince 聊开发
@vincemask
5 days ago
一个 Google Cloud 工程师演示用 Claude从零开始开发应用。 重点是穿插把 Claude Code 的核心工作流讲透了:CLAUDE.md、上下文管理、从开发到部署、以及如何让 Claude 承担真实工程任务。 这 30 分钟,讲透了vibe coding的本质。
vincemask's tweet video.
gonewithwill
retweeted
Barret李靖
@Barret_China
6 days ago
最近的工作模式已经逐步变成,AI 监控群聊/线上日志/会议纪要,定时产出可执行的 todo list,加入到 AI 自己的看板,然后结合对应项目的源码仓库和 okr 文档,能提代码的直接产出PR,能出方案的直接产出文档,要么就是各种私聊催办,让责任人补齐上下文材料,好让它继续干活儿。 目前一个复杂项目 15% 以上的代码,都是 AI 全流程自助完成,给自己建需求、写代码、跑单测、提 PR😅,甚至合并代码都被 AI给干了(换两个模型轮流交叉 review)。
gonewithwill
retweeted
geniusvczh
@geniusvczh
5 days ago
Windows 11有个动画的bug,该播动画的时候没刷新,导致看起来无缘无故卡了。你在性能设置里把动画关了,UI直接起飞🤪
gonewithwill
retweeted
Kai
@real_kai42
6 days ago
Kimi code 支持了接入专业数据库,直接从官方数据源 查询 • stock_finance_data — A股/港股/美股 综合金融数据:实时行情、历史价格、财务报表、公司公告、股东信息、财务指标、业务分部、盈利预测、智能选股 • yahoo_finance — Yahoo Finance 全球金融数据:股票/外汇/ETF/加密货币/指数的历史价格、财报、股东、分析师评级、期权链、公司新闻 • world_bank_open_data — 世界银行宏观经济数据:全球各国 GDP、人口、通胀、失业率、教育、医疗、贸易、环境等 29,000+ 指标 • tianyancha — 天眼查中国企业工商信息:工商登记、股东结构、司法风险、知识产权、经营状况、关联关系 • arxiv — 学术论文预印本:计算机/物理/数学/生物等领域论文的搜索、下载、阅读 • scholar — Google Scholar 学术搜索:论文检索、作者画像、引用分析
See More
peter
@gonewithwill
6 days ago
@LifeBeLikeThatX
哇哈t
gonewithwill
retweeted
Mr Panda
@PandaTalk8
7 days ago
agent 团队? 别搞笑了。 最近又开始有很多人搞 agent 团队, 就是给ai 设定各种角色来组成ai agent 团队。 比如 有AI Agent 的产品经理、 AI Agent 前端工程师、 AI Agent 的后端工程师 等等, 然后他们相互协作去完成一项团队级别的任务。 实际上我曾经也做过试验,我认为没有啥用。 AI/LLM 想要用的好, 最重要的上下文约束做的好 。 现在我们人为把他们分开, 各有个的上下文,协作不可能顺利。 那么最好办法是什么 ? 我认为把任务背景、目标、约束、关键上下文结构化的输入AI/LLM , 这才是真正的有效的事情。 真正重要的是:你能不能把一个复杂任务,压缩成 LLM 可以理解、推理、执行和验证的结构化上下文。
See More
gonewithwill
retweeted
好奇猫a
@acnekot
7 days ago
你怎么能直接 commit 到我的 master 分支啊?!GitHub 上不是这样!你应该先 fork 我的仓库,然后从 develop 分支 checkout 一个新的 feature 分支,比如叫 feature/confession。然后你把你的心意写成代码,并为它写好单元测试和集成测试,确保代码覆盖率达到95%以上。接着你要跑一下 Linter,通过所有的代码风格检查。然后你再 commit,commit message 要遵循 Conventional Commits 规范。之后你把这个分支 push 到你自己的远程仓库,然后给我提一个 Pull Request。在 PR 描述里,你要详细说明你的功能改动和实现思路,并且 @ 我和至少两个其他的评审。我们会 review 你的代码,可能会留下一些评论,你需要解决所有的 thread。等 CI/CD 流水线全部通过,并且拿到至少两个 LGTM 之后,我才会考虑把你的分支 squash and merge 到 develop 里,等待下一个版本发布。你怎么直接上来就想 force push 到 main?!我拒绝合并!
See More
gonewithwill
retweeted
Tigris 会讲课教授是好老师
@tig88411109
8 days ago
开年最差之一,3/30日标普500在最底部下跌7%,现在已上涨10% 你还能不能记得,在最黑的时候到底学到了什么。 很多人总想要一个完美答案: 现在是不是最低点? 现在是不是要 all in? 现在是不是该清仓? 市场从来不给这种答案。 你卖的时候,不会刚好卖在最高点。 你买的时候,也不会刚好买在最低点。 真正成熟的投资,不是执着于那个神话般的最优点,而是用你自己活得下去的仓位结构,持续做高赔率的事。 树不会长到天上去。再好的板块,涨多了也会透支赔率。再差的情绪,跌到脱离合理价值以后,也会出现修复。 所以最难的,从来不是看懂一次暴跌。 而是当市场重新热起来、重新顺起来、重新让你觉得自己无所不能的时候 你还能不能记得,在最黑的时候到底学到了什么。 多数人不是死在底部。多数人死在从底部活过来以后,以为自己刀枪不入。 市场会反复奖励勇敢。 但它最终只长期奖励有纪律的人。
See More
peter
@gonewithwill
8 days ago
现在才反应过来关注美伊战争是浪费时间,当美股大幅反弹时,这个指标早已失灵。
gonewithwill
retweeted
烦恼小羊
@fannaoxiaoyang
12 days ago
你是一个经验丰富的美股投资者,过去数十年,每逢大回调你都重仓抄底。果然,你的胆识带来了丰厚回报,每次都是V型反转,有惊无险。 你走在街上,看到那些为生活奔波的熙攘人群,优越感不禁涌上心头,你由衷认为人就应分三六九等,你天生靠脑子赚钱。 时间来到1999,电视又开始播报那些无聊的互联网泡沫新闻,市场再次大幅下跌。你内心轻蔑一笑,这种危言耸听的场面你见过无数次,而你早已游刃有余,你知道一切只是华尔街的戏法。 你即将迎来第三个孩子,是时候换带泳池的大房子了。这次你铆足了劲,开始下更大的赌注…
peter
@gonewithwill
9 days ago
地缘政治事件只适合埋伏,不适合追高,没有可持续性,这个教训太惨痛了
gonewithwill
retweeted
高军
@GoJun315
11 days ago
Anthropic 黑客松获奖者,把自己 10 个月重度使用 Claude Code 沉淀下来的整套打法,毫无保留地开源了出来。 ECC,一个面向 Claude Code、Cursor、Codex 等主流 AI 编程工具的 Agent 工程化框架,目前在 GitHub 上狂揽了 18 万 Star。 它不是简单一份配置模板,而是一整套把 AI 编程工具当成基础设施来用的完整系统: - 60 个专用 Agent,覆盖规划、架构、TDD、代码审查、安全审计、构建排错等场景 - 232 个按需加载的 Skill,写代码、写文章、做投资材料、跑营销都有现成模板 - 内置 AgentShield 安全扫描,专门审计 CLAUDE.md、MCP 配置、hook、skill 里的安全风险 - 三个 Opus 4.6 跑红蓝对抗,攻击方找漏洞、防守方评估、审计方给出最终风险评级 - 连续学习层会自动把每次会话里有效的模式,沉淀成可复用的 skill - 覆盖 TypeScript、Python、Go、Rust、Java、Swift 等 12 个语言生态 GitHub:https://t.co/UG9LsDURSX 可作为 Claude Code 插件一键安装,建议重度用 Claude Code 写代码的朋友使用。 也推荐研究一下这套配置思路,能学到很多把 AI 编程工具真正用出生产力的玩法。
See More
Last Seen Users on Sotwe
GRUP BOKEP TELEGRAM
Seen from
Malaysia
👠-
Seen from
Germany
Inara
Seen from
Malaysia
KDAKDA rda
Seen from
India
Shabery Cheek
Seen from
Denmark
Nazrul kobiraz
Seen from
Singapore
Güvenilir Sena
KARISINI PAYLAŞANLAR- KENDİSİNİ PAYLAŞAN HANIMLAR
Seen from
Turkey
Bora'nın🐆Esra'sı
Seen from
Turkey
BJ
Seen from
Netherlands
Trends for you
1
Brunson
Under 10K tweets
2
Knicks
Under 10K tweets
3
#AEWDynamite
Under 10K tweets
4
#loveislandusa
Under 10K tweets
5
Champagnie
Under 10K tweets
6
Scott Foster
Under 10K tweets
7
Shamet
Under 10K tweets
8
Harrison Barnes
Under 10K tweets
9
Josh Hart
Under 10K tweets
10
#NYKvsSAS
Under 10K tweets
Most Popular Users
1
Elon Musk
@elonmusk
240.1M followers
2
Barack Obama
@barackobama
119.3M followers
3
Donald J. Trump
@realdonaldtrump
111.6M followers
4
Cristiano Ronaldo
@cristiano
108.7M followers
5
Narendra Modi
@narendramodi
106.9M followers
6
Rihanna
@rihanna
97.2M followers
7
NASA
@nasa
92.1M followers
8
Justin Bieber
@justinbieber
90.5M followers
9
KATY PERRY
@katyperry
86.7M followers
10
Taylor Swift
@taylorswift13
80.5M followers
11
Lady Gaga
@ladygaga
72.1M followers
12
Kim Kardashian
@kimkardashian
69.3M followers
13
YouTube
@youtube
68.6M followers
14
Virat Kohli
@imvkohli
68.4M followers
15
Bill Gates
@billgates
63.4M followers
16
The Ellen Show
@theellenshow
62.5M followers
17
CNN
@cnn
61.9M followers
18
Neymar Jr
@neymarjr
60.9M followers
19
X
@x
60.9M followers
20
CNN Breaking News
@cnnbrk
59.9M followers
Olivia
Online
✨
⭐
💫