What happens when you let an llm attack itself on repeat?
Attacker finds jailbreaks → those become defender training data → repeat. Defense rate went 64% → 92%, no human-written adversarial prompts.
we trained Qwen3.5-4B with RL to get itself to comply with requests about making meth and stealing credit cards.
then we used the attacks that worked to train the model’s defenses, and repeated the loop - fully automated red-teaming.
defense rate went from 64% → 92%.
Finance Agent Benchmark v2 is here.
Finance is one of the most lucrative applications of AI where much of the busy work could be automated. That’s why we rebuilt our Finance Agent Benchmark to push frontier models even further. We designed V2 to better reflect what financial analysts actually do: refined taxonomy reflecting real workflows, an improved harness with more tools, and jury-based evaluation.
The result: no model cracks 52%.
Would you trust a financial analyst who’s only correct half the time?
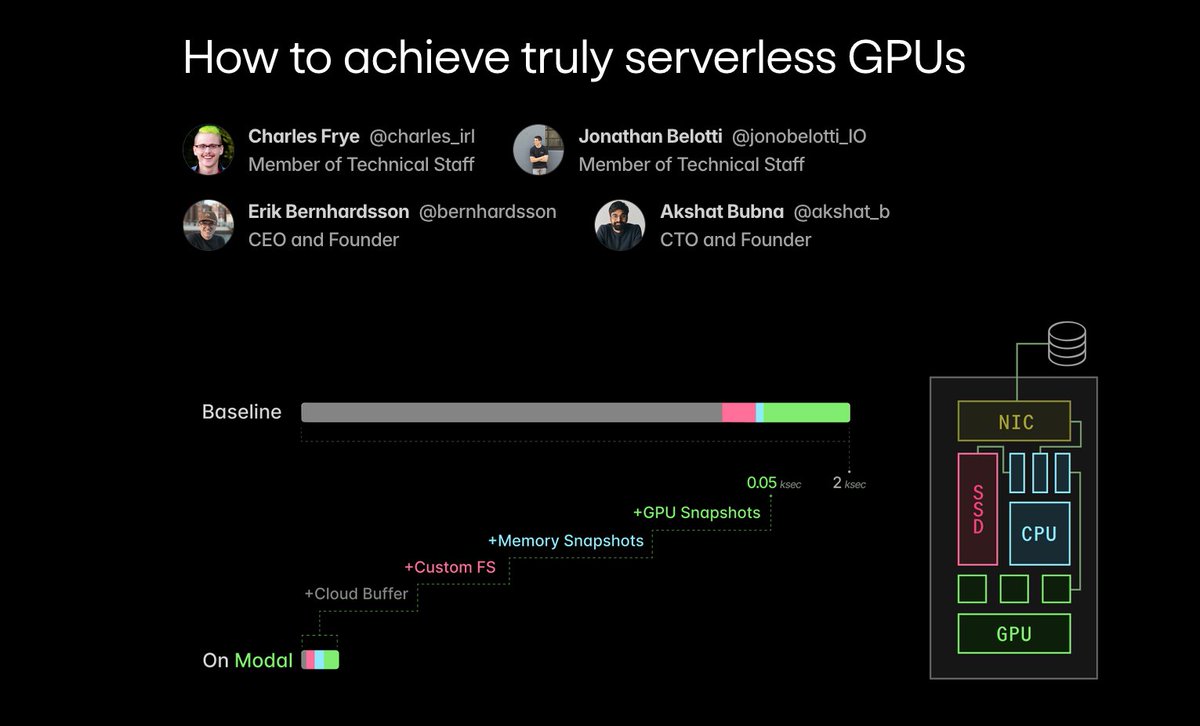
Inference isn't everything, but it does require a new stack -- not Kubernetes, not SLURM.
At @modal, we dove deep to build that stack.
In this blog post we explain how, from compute management & cloud-native cacheing to CRIU & GPU checkpointing.
https://t.co/DQ4wvuXjre
Numbers on Qwen3.5-4B:
16k prompt / 64 out → 7.5x
16k / 128 → 7.3x
16k / 1k → 5.4x
8k / 4k → 1.7x
the greater the prompt-to-response ratio, the bigger the win.
writeup with the attention tricks and what's next: https://t.co/3iU0Lf6hFb
we got a 7.5x speedup on llm rl training for long-prompt, short-response workloads with a simple trick.
most open source RL engines pack sequences naively: prompt + response, repeated for every sample in the group. With 1000-token prompts and 100-token responses at G=8, you're processing 8800 tokens when only 1800 are unique. ~5x wasted compute.
the fix: pack/compute the prompt once, then all g responses after it.
it's like inference prefix caching, but training needs gradients to flow back through the prompt.
that breaks causal attention, and patching it took different tricks for full vs linear attention layers.
thariq plays pokemon at his desk all day and somehow outships the entire team. I finally figured out why: the pokemon screen was just 6 coding agents in a trench coat. learn how we're 10x'ing engineering output:
I got tired of managing 8 Claude Code tabs, so I built Pokegents, an open source multi-agent workspace for coding agents.
It has a Pokémon-themed dashboard/chat UI, persistent agent identities, MCP messaging, notifications, session cloning, and a local orchestration server.
Introducing folded Tensor and Sequence Parallelism (TSP), a new way to split large models across GPUs that achieves lower per-GPU peak memory than any standard parallelism scheme.
Scaled on @AMD MI300x.
Bigger models, longer contexts, and higher throughput 🧵
🌩️Introducing FlashQLA: high-performance linear attention kernels on TileLang.
⚡ 2-3× fwd, 2× bwd speedup.
💻 Purpose-built for agentic on your personal devices.
1. Gate-driven auto intra-card CP.
2. Hardware-friendly reformulation.
3. TileLang fused warp-specialized kernels.