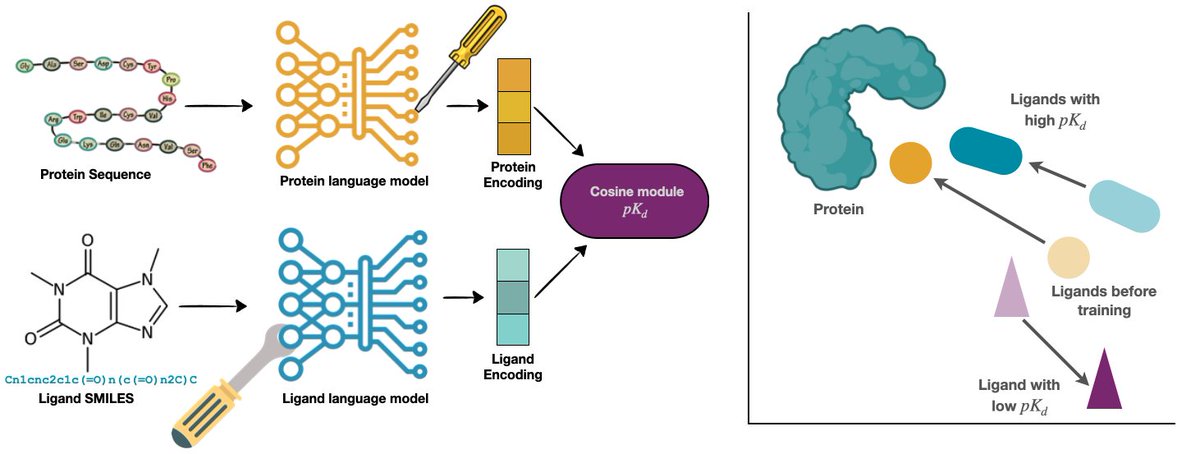
📢🧬Looking for fast and reliable ways to predict binding affinities? Meet BALM!👋
BALM predicts binding affinity from protein sequences and ligand SMILES using pretrained protein and ligand language models.
📄 https://t.co/t79Gdlq9Mx
🔗 https://t.co/hnsfgOvY3j
🧵1/9
We are releasing Carbon: a crazy fast DNA model
Carbon is 275x faster than the next best model. So fast you can process the whole human genome on a single GPU in <2 days.
Here are the tricks we used:
When modelling DNA sequences a lot of the performance comes down to tokenizing the sequences in a smart way. BPE tokenizer struggle because there are no whitespaces and character (called base in DNA) level tokenizers waste a lot of compute on too many tokens.
Carbon is built with a unique tokenizer: we split sequences in chunks of 6 bases, but during both training and inference we can work with single base resolution. That's similar to having word tokens but resolving them at the character level. All possible thanks to the DNA tokens unique structure.
The architecture combined with the tokenizer makes the model 275x faster than the previous SoTA (Evo2) at this size.
We built an interactive demo so you can explore how the model can generate DNA sequences, investigate the structure of genes, predict the effect of mutations, generate and fold proteins and even reconstruct parts of the tree of life.
https://t.co/OWEUoxAFjG
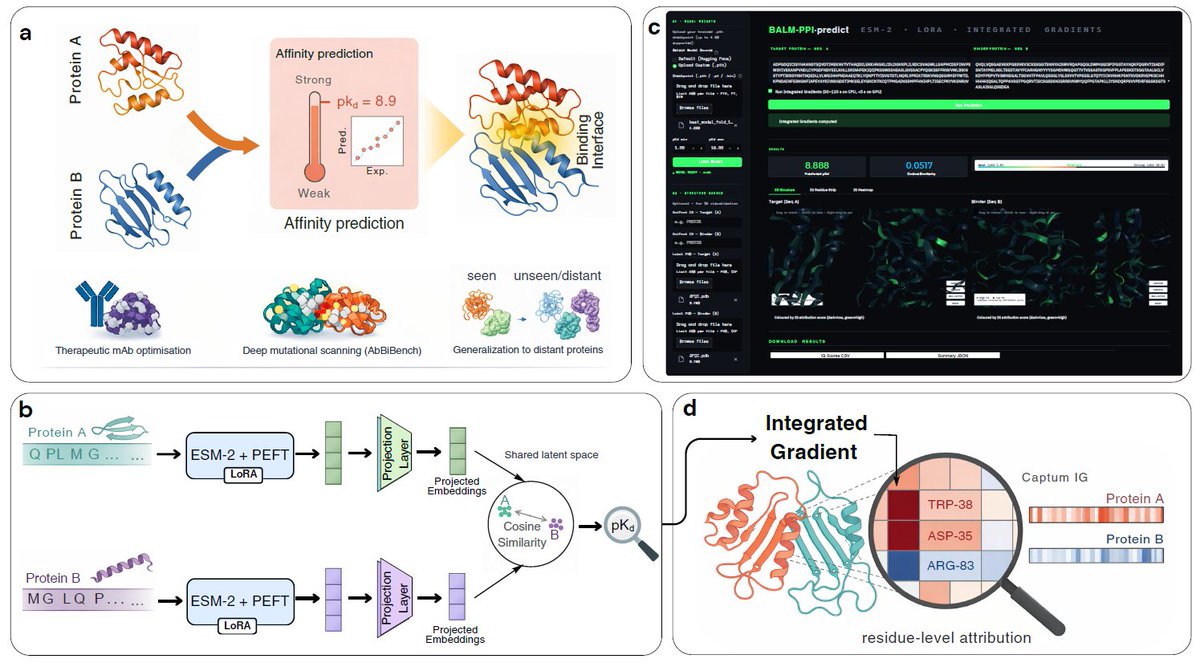
Excited to share the first steps of my PhD work and my first paper as first author, now on bioRxiv!
📄 https://t.co/SGBhydgOY4
💻 https://t.co/CJFzehaPD7
🌐 https://t.co/zxAUX25bJe
🔍 Predicting protein–protein binding affinity from sequence alone.
Meet BALM-PPI 👇
🧵1/9
We just published our work on an explainable active learning framework for ligand–protein binding affinity prediction in Digital Discovery.
🔗 https://t.co/zfurYTsFG4
Here’s a quick breakdown of what we did and why 👇
Apply for the AITHYRA-CeMM International PhD Program!
15-20 fully funded PhD fellowships available in Vienna in AI/ML and Life Sciences
Deadline for applications: 10 September 2025
https://t.co/0gQFlg9sQX
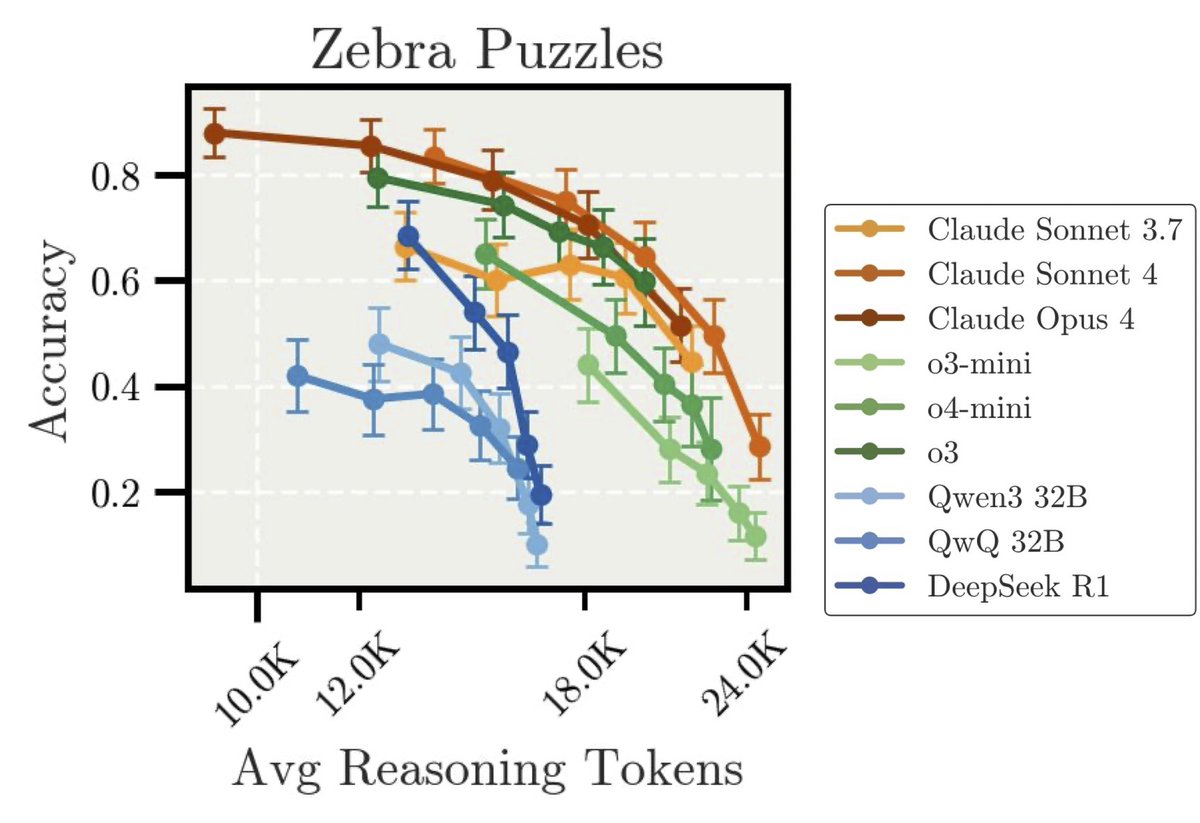
New Anthropic Research: “Inverse Scaling in Test-Time Compute”
We found cases where longer reasoning leads to lower accuracy.
Our findings suggest that naïve scaling of test-time compute may inadvertently reinforce problematic reasoning patterns.
🧵
We're delighted to announce that our conference "Protein Evolution, Design and Informatics Edinburgh 2026" will be running from the 13th-15th of May. Register interest here and please retweet! https://t.co/V3gUMltUVT
💡Why BALM? While structure-based methods have limitations, they are widely used compared to recent deep learning (DL) models due to generalisability issues. To make DL models reliable for screening, we address challenges at model, data and evaluation levels.
🧵2/9
🙌 Special shoutout to all my co-authors, @aryopg@Xi_Yang_Ian, @jjuarez_jimenez, Ben Suutari, Álvaro
Morrás for all their hard work. Big thanks to @ppxasjsm for her incredible support!
🧵9/9
📢🧬Looking for fast and reliable ways to predict binding affinities? Meet BALM!👋
BALM predicts binding affinity from protein sequences and ligand SMILES using pretrained protein and ligand language models.
📄 https://t.co/t79Gdlq9Mx
🔗 https://t.co/hnsfgOvY3j
🧵1/9