Searching for a faster way to find the best deal to rent that GPU you need?
https://t.co/8jdIIeP2Rl just shipped 🚢
Now you can now compare prices from @runpod, @vast_ai, @ThunderCompute & more in one place.
I wanted faster builds so I explored how to conditionally build our rust monorepo based on the cargo dependency graph - packaged it up as a github action for reuse across projects https://t.co/eZ8IMp7b1d
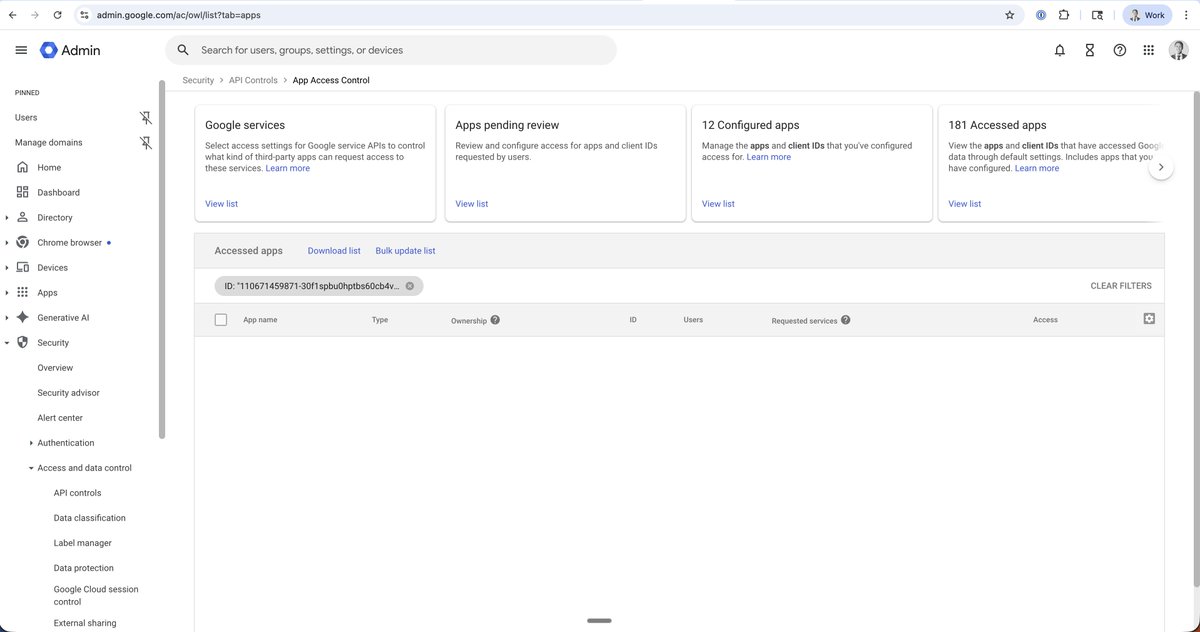
To check if your Google Workspace has been compromised by the same tool that compromised Vercel:
1. Go to https://t.co/TpuIOW5Fwg
- This is Google Admin Console > Security > Access and Data Control > API Controls > Manage app access > Accessed Apps
2. Filter by ID = https://t.co/uqJnCqp5Ah
- This is the ID of the compromised OAuth app
If you see an app after filtering, you have potentially been compromised
We're proud to share that @NVIDIA submitted the first-ever MLPerf Vision Language Model (VLM) performance benchmark using vLLM. This achievement showcases the strength of our ongoing collaboration with NVIDIA Engineering.
Check out their MLPerf blog and watch our On Demand Talk at GTC to learn more about how we are delivering the best performance on NVIDIA hardware.
🔗 Blog: https://t.co/sImlVjkMKW
🔗 Talk: https://t.co/dyDnQUG3AX
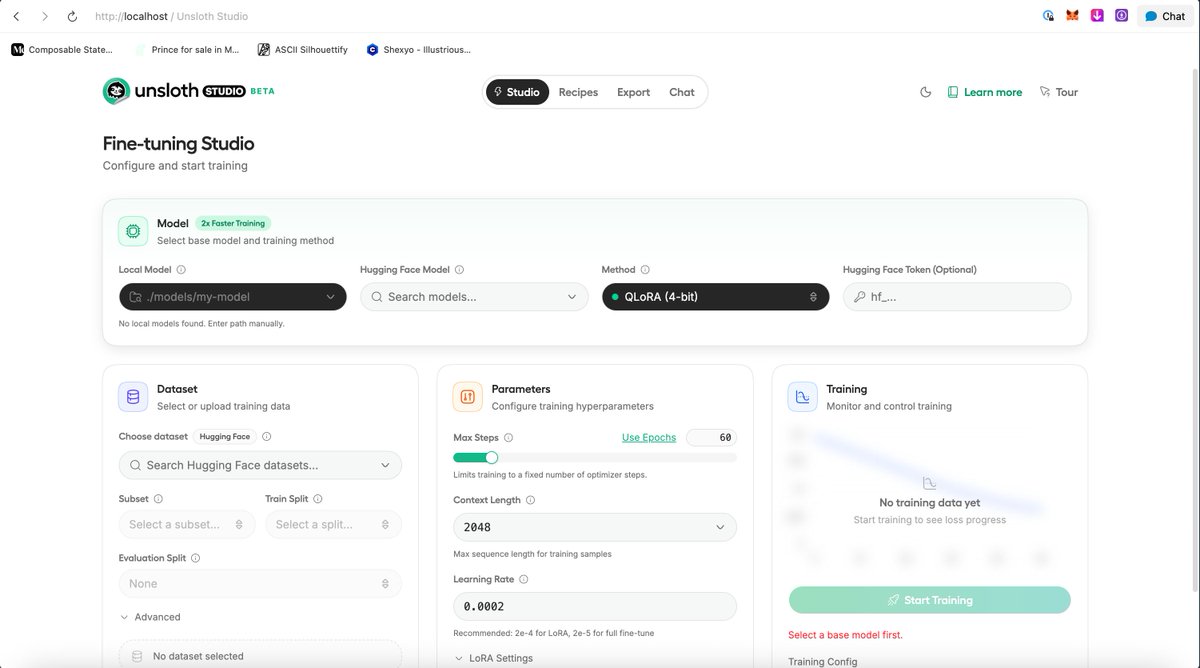
We're excited to announce we've just made working with #Unsloth Studio on cloud GPUs way easier with our new dedicated template.
This means training and running models is as simple as working with your local device and as powerful as the hardware you want to use.
#LLM#MLOps
One of the tougher parts of running OSS models is knowing what you can actually run on your hardware (or what hardware you need to run a specific model).
If that's you, check out this gem by Alex Jones
https://t.co/7D2pfZ6F1o
But what about the setup overhead? Thankfully GPU CLI makes running these models and many others from your terminal as easy as copy + paste, then selecting a machine.
Find us here https://t.co/qZEiw1X2Dh
Many people using the OpenAI API don't need to be.
OSS models have closed the gap for everyday tasks and the hardware to run them is cheap to rent with services like RunPod and VastAI.
If you don't need a top tier model, here are some alternatives that could save you money.
2. A100 80GB on RunPod + Qwen3-32B
- Price: $1.19/hr
- Nearest OpenAI tier: GPT-5.4 at $15/million output tokens.
Closer to frontier quality, still meaningfully cheaper at scale for most tasks.
Introducing Kitten TTS V0.8: open-source TTS that fits in 25MB.
Three variants: 80M | 40M | 14M (<25MB)
Highly expressive. Runs on CPU. Built for edge.
No GPU? No problem. Ship voice anywhere.
Check it out:
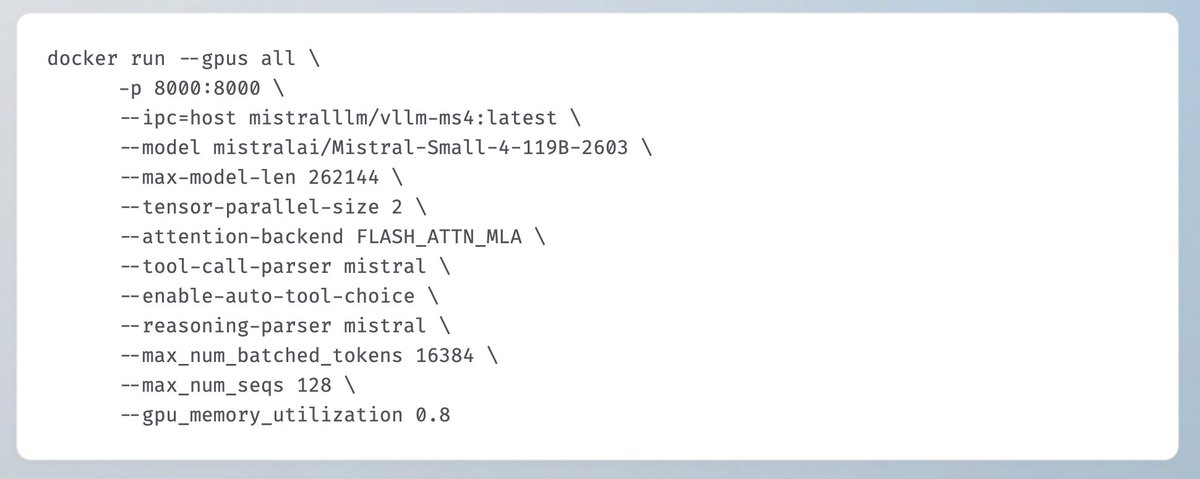
🎉 Congrats to @MistralAI on releasing Mistral Small 4 — a 119B MoE model (6.5B active per token) that unifies instruct, reasoning, and coding in one checkpoint. Multimodal, 256K context.
Day-0 support in vLLM — MLA attention backend, tool calling, and configurable reasoning mode, verified on @nvidia GPUs.
🔗 https://t.co/eDfQadxmiC