Internet Architecture Board (IAB) Statement with regards to Canada C-22 (“An Act Respecting Lawful Access”)
TL;DR: don’t do it, it weakens the Internet.
https://t.co/vNQunguv5o
@BjarkeIngels not sure if you’ve seen it yet, but the proposed Columbia Heights / Panorama rezoning appears likely to impact views from 111 Hicks, including Brooklyn Bridge sightlines. City filing here: https://t.co/aaRhORts1C
Interoperable E2EE RCS is finally rolling out in iOS 26.5. This is huge and I’m very proud of my teams to make this happen and protect the privacy of millions of users 🔒
Every lock needs a key. The hard part is not always designing the lock. Sometimes it is getting the key to the person who needs it.
That is the problem I address in the third post of my CDT series on Encrypted Client Hello. ECH is designed to close one of the last major metadata leaks in HTTPS: the exposure of the website name in the TLS ClientHello. But before a browser can encrypt that part of the handshake, it needs the server’s ECH configuration. In today’s deployment model, that usually comes from DNS.
This creates a very practical bootstrapping problem. DNS is not just a lookup mechanism here. It is the path by which the client learns the information needed to make ECH work. In normal network conditions, that is a clean design. In censorship environments, it is an obvious pressure point.
China is the clearest example. The Great Firewall has a long history of DNS injection and poisoning. Encrypted DNS changes the mechanics, but not the basic incentive. DNS-over-TLS can be blocked outright. DNS-over-HTTPS is harder to block cleanly because it runs over HTTPS, but it can be identified and degraded. The result is not always a crisp failure. It can be something more frustrating and more effective: temporary blacklisting, flakiness, and enough unreliability that users give up.
That matters for ECH because a censor does not need to break the TLS handshake if it can prevent the client from obtaining the ECH configuration in the first place. The failure occurs before the privacy property is enabled.
This is one of the recurring lessons of Internet security. Cryptography is necessary, but it is not the whole system. Discovery, distribution, caching, fallback behavior, and downgrade resistance are part of the security architecture too. Censors often attack those seams because they are cheaper to exploit than the cryptography itself.
The natural question is whether ECH configurations need to be tied so tightly to DNS. DNS currently handles both distribution and authentication. If those functions can be separated, ECH configs could be distributed via other paths while still being cryptographically authenticated. Well-known endpoints, cached configurations, CDN distribution, key transparency mechanisms, and signed ECH configurations are all part of that design space.
ECH is still one of the most important privacy improvements happening in the web platform. But if we want it to work for the people most likely to face network interference, we have to treat configuration delivery as a first-class part of the problem.
The next step is not just deploying ECH. It is making sure ECH can actually start.
https://t.co/fzzybveHni
I'm in Toronto discussing how websites can specify their preferences regarding how their content is used by search engines and AI crawlers. Here's what we have so far:
Want to help shape the cryptography that ends up in Internet standards? CFRG is looking for Crypto Review Panel members. Self-nominations welcome. Two-year renewable term.
Send nominations by April 20: [email protected]
https://t.co/DZRJUoX42x
ECH exposed a hard truth about privacy technology: you can win at the protocol layer and still lose at the deployment layer. The lesson from the ECH rollout is not just that a censor blocked it. It is that privacy can fail at the deployment layer even when the protocol is doing the right thing.
I wrote about it here for @CenDemTech: https://t.co/nImxU3W7y7
ECH's design goal is "do not stick out." If encrypted connections all look similar, they are harder to classify, monitor, and block. GREASE helped with that. It made ECH-shaped traffic common, so the syntax itself did not stand out. But that was not the whole story. Real deployments still produced a visible pattern. The issue was not the extension syntax. It was config update and recovery behavior.
In practice, those recovery mechanics pushed clients toward a common visible outer name. That created a cheap classification handle. So ECH stopped sticking out at one layer and started sticking out at another. That is the interesting deployment lesson.
Privacy is not just about cryptographic correctness. It is about operational indistinguishability too. Rollout paths, retry paths, and recovery paths matter.
That is why signed ECH config updates are interesting. The point is not just "more crypto." The point is to remove the deployment constraint that created a stable fingerprint.
This is the new draft with Dennis Jackson and Alessandro Ghedini:
https://t.co/2is53rUrtm
Interop work is here:
https://t.co/AafV2zBFKH
@benln If it’s a startup that is dedicated to the long-term health of the Internet or solving important human problems with cryptography (not including blockchain), I’m a good person to have aboard.
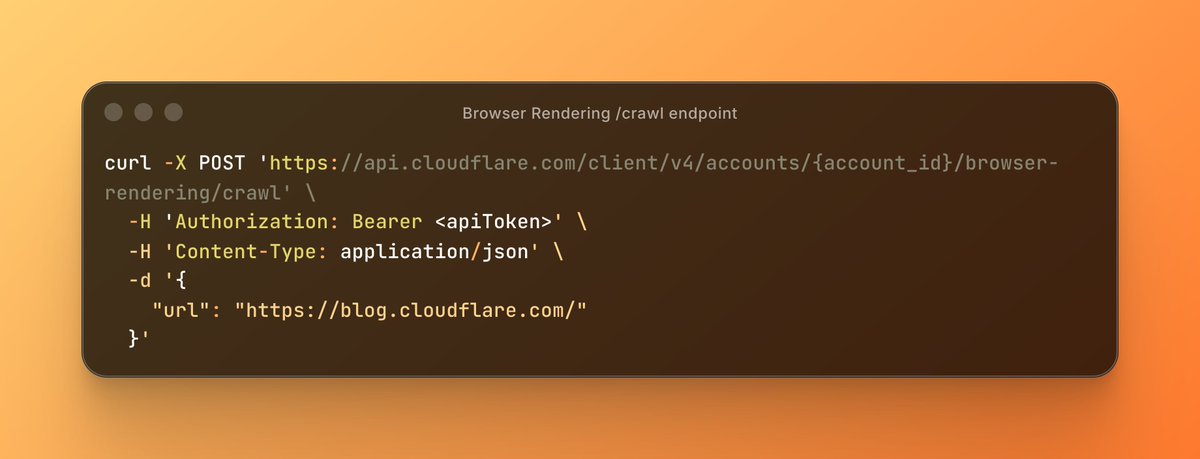
Love this from Cloudflare.
/crawl is built around the norms that keep the web sustainable: identifying itself honestly in the user-agent string, respecting robots.txt and crawl-delay, honoring site preferences, and backing off when told to. 429s, retry-after headers, the works. And with maxAge-based caching, repeated fetches to the same URL hit a cached result instead of the origin again. Less waste, less unnecessary load on publishers.
Crawling is not scraping. Not even close.
The Internet is one of the most important heirlooms we have as a society. Billions of people contributed to building it: publishing, linking, sharing, cooperating across borders and institutions and decades. That does not happen again. You do not get to inherit something like that and strip it for parts. You do not get to automate around the preferences of the people who built it, ignore the norms that made it valuable, and call that innovation. That is extraction. It degrades something irreplaceable.
Scrapling and Crawlee are the wrong approach. People who reach for those tools when they should be crawling have made a choice. It is worth being clear about what that choice costs.
The voluntary shared agreement that made the web work depends on people actually honoring it. Publishers set preferences. Crawlers respect them. Everyone benefits. That only holds if enough people take it seriously.
Use the good tools (this one counts). Respect site preferences. Do your part.
Introducing the new /crawl endpoint - one API call and an entire site crawled.
No scripts. No browser management. Just the content in HTML, Markdown, or JSON.
Encrypted Client Hello is now RFC 9849
This RFC defines an extension to Transport Layer Security that improves privacy for web users to a significant degree. Huge team effort by more than just the listed authors here, and a win for the internet at large. Now to get deployment up...
I wrote about this pending draft a few months ago and hinted at some of the challenges to come: https://t.co/Qk2EYX0SLN
Huge 🎉 novel crypto design by @Stanford@IBMResearch & @Mysten_Labs has been accepted to Eurocrypt 2026, one of the top cryptography conferences in the world.
TLDR: we took partial fraction decomposition (yes, the thing from high-school algebra) and turned it into a surprisingly powerful cryptographic primitive.
Instead of converting rational functions into polynomial divisions, we work directly with their algebraic structure. This reveals two powerful properties:
- Partial-fraction decomposition as a membership test:
Products of rational functions can be expanded into sums if and only if certain conditions hold. This gives us a beautifully simple mechanism for proving set membership and non-membership using just pairing equations.
- A new linear-independence property:
Using Cauchy matrices, we show that certain rational sum-based products are inherently linearly independent - a property we leverage to build dynamic threshold encryption.
---
It unlocks:
- Constant-size key-value commitments with homomorphic updates (great for stateless blockchains)
- Dynamic threshold encryption with compact keys & ciphertexts
- Broadcast encryption, Hadamard product proofs for zkSNARKs
- 🍒We believe this opens the door to new aspects of “rational-function cryptography,” with many unexplored applications.
Massive congrats to @SuiNetwork intern Rohit Nema, IBM’s Charanjit, and Mysten’s Arnab... incredible summer work that turned into a practical, peer-reviewed super-algorithm. This is how research should feel 🚀, and why blockchains advanced world's practical cryptography like nothing else in the last 2 decades.