@shantanugoel I will prefer reranking + semantics any day but actual data we deal with is shit. And don't have option to train our own embedding, which would solve 90% of issue. Long run much less token costs and better retrieval. But heh!
@shantanugoel Yes. But only if your doc are clean. I tried this a memory for a agent I am working on. Failed horribly because the it is getting bs from vector search as it contains lingo that make no sense to the model (bad score).so moved back to this. I guess it work great if self train emb
@shantanugoel Another thing I found out building and storing a function by agent itself and write to file. And later recall that function from a function registery. Saves a lot of token on regular tasks. Where you don't have stored procedure/function.
@shantanugoel You ideally can have subagent that gets triggered on failure with a job of searching skill and feed tha back to main. Generally very little context bloat here. But again depending on how you are extracting and storing skills. My vector search failed horribly because shit data stc
We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
this is excellent. Training from zero token for indic langauge is huge huge job, cant wait to play with these @SarvamAI
Also need a blog on that tokenizer please 🥺
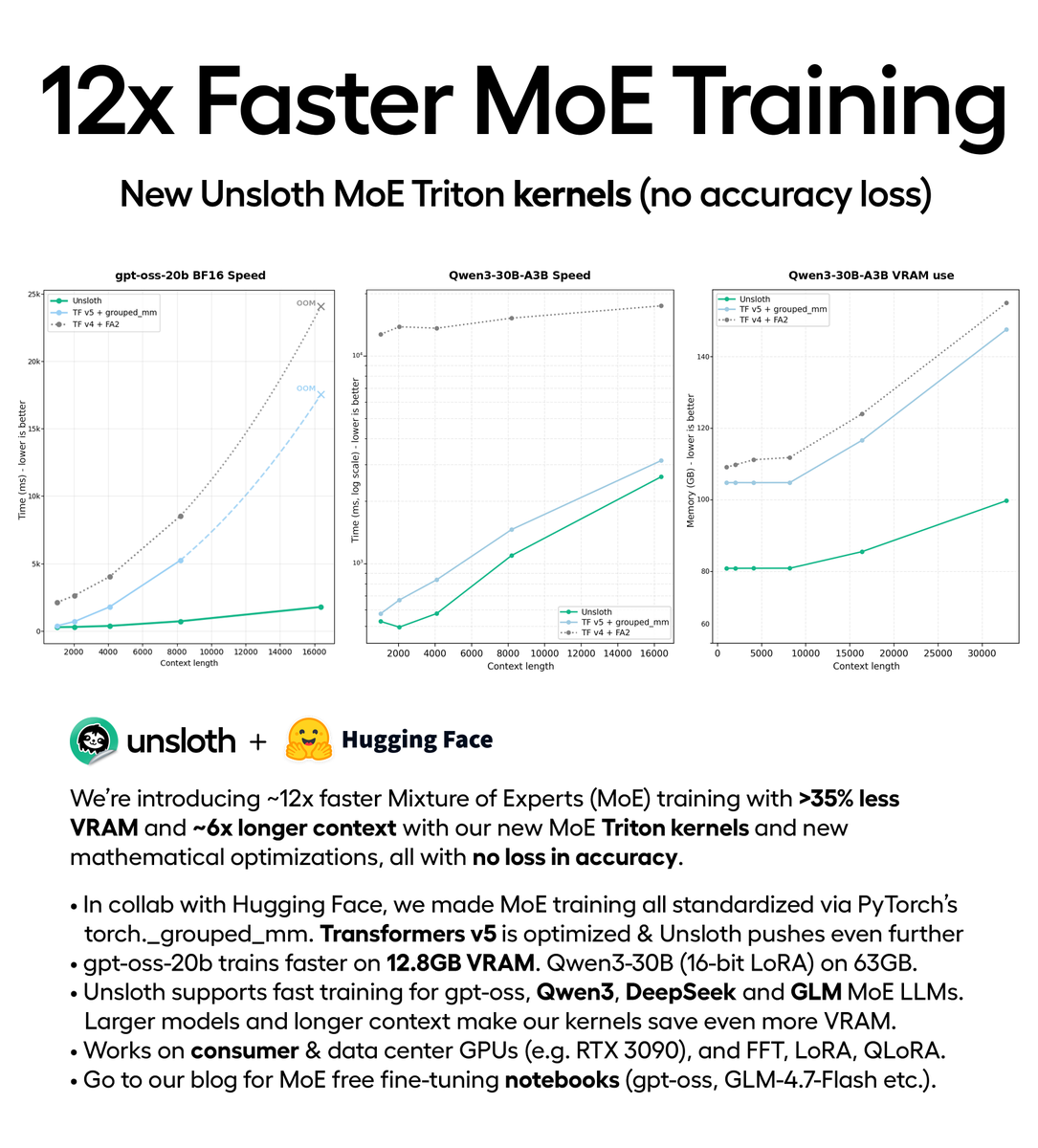
You can now train MoE models 12× faster with 35% less VRAM via our new Triton kernels (no accuracy loss).
Train gpt-oss locally on 12.8GB VRAM.
In collab with @HuggingFace, Unsloth trains DeepSeek, Qwen3, GLM faster.
Repo: https://t.co/2kXqhhvLsb
Blog: https://t.co/HY6DwTnCwl
We disrupted a highly sophisticated AI-led espionage campaign.
The attack targeted large tech companies, financial institutions, chemical manufacturing companies, and government agencies. We assess with high confidence that the threat actor was a Chinese state-sponsored group.
Training LLMs end to end is hard. Very excited to share our new blog (book?) that cover the full pipeline: pre-training, post-training and infra. 200+ pages of what worked, what didn’t, and how to make it run reliably
https://t.co/iN2JtWhn23