@kablotv [1] 1 ay kadar once babam vefat etti. Vefatindan sonra annem bir suredir onun adina olan kablo tv uyeliklerini iptal icin ugrasiyor. 73 yasinda bir kadina yasattiginiz durum herhangi bir musteri anlayisiyla bagdasmiyor.
@kablotv@kablotv [2] Musteri hizmetlerinizi her arayisimizda birbiriyle celisen bilgiler aliyoruz. Geri goturmemizi beklediginiz cihazi en sonunda bulup goturdugumuzde de sadece cihaza bakarak arizali raporu tutuyorsunuz.
🔥Joint video diffusion training & video point tracking
We present #Track4Gen: Teaching video diffusion models to track points improves video generation
at @CVPR
-project: https://t.co/xhx3MNCREn
Joint work with amazing Adobe mentors @guerrera_desesp, @paulchhuang, Niloy Mitra
🧵We present #Track4Gen where augment video generators with additional point tracking supervision. This results in better spatial awareness and reduces appearance drift. Work led by our talented intern Hyeonho @Hyeonho_Jeong99 together with @paulchhuang and Niloy Mitra.
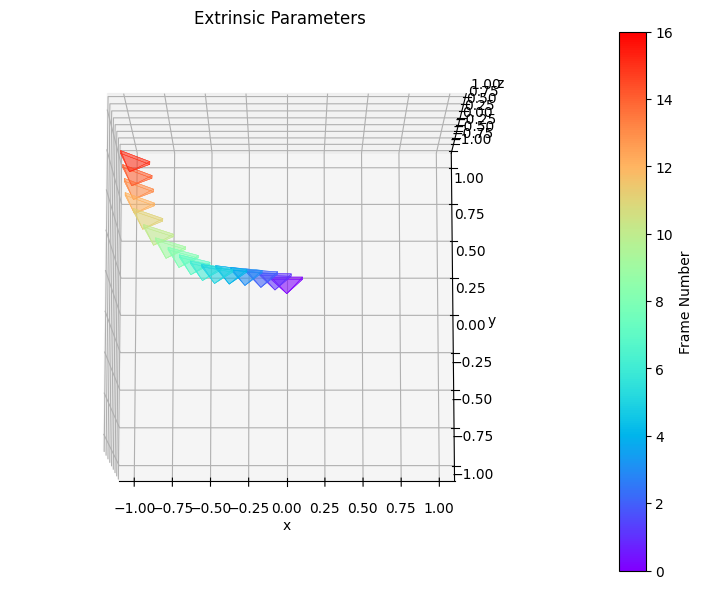
OpenSora is great but no viewpoint control? Check out our method which effectively moves the camera however you want for Video Diffusion Transformers.
Key features:
1. It also controls speed.
2. Only 1 frame has input camera also works.
Congrats @soon_yau for the amazing result🚀
Combining the power of 3d tools and workflows with generative models opens up many exciting opportunities. A great first step with our intern Shengqu @prime_cai !
Generative Rendering: Controllable 4D-Guided Video Generation with 2D Diffusion Models
paper page: https://t.co/28pBPHQqV5
Traditional 3D content creation tools empower users to bring their imagination to life by giving them direct control over a scene's geometry, appearance, motion, and camera path. Creating computer-generated videos, however, is a tedious manual process, which can be automated by emerging text-to-video diffusion models. Despite great promise, video diffusion models are difficult to control, hindering a user to apply their own creativity rather than amplifying it. To address this challenge, we present a novel approach that combines the controllability of dynamic 3D meshes with the expressivity and editability of emerging diffusion models. For this purpose, our approach takes an animated, low-fidelity rendered mesh as input and injects the ground truth correspondence information obtained from the dynamic mesh into various stages of a pre-trained text-to-image generation model to output high-quality and temporally consistent frames. We demonstrate our approach on various examples where motion can be obtained by animating rigged assets or changing the camera path.
Thanks @_akhaliq! I have been thinking about how to bridge the gap between traditional CG pipelines and generative model, now that’s a first attempt. We can get some interesting results using only a 2D model, without any video training! Project page: https://t.co/g5SdDm7olX.
Applications for 2024 internships are open! If you'd like to work with the Adobe Research London Lab on exciting research projects, apply through here:
https://t.co/WAEFpEJz6R
We will present Pix2Video this Friday afternoon at #ICCV2023.
The code is released: https://t.co/EGACXjYFMq
Video: https://t.co/tNfnu8wNhx
If you'd like to chat about the work or potential internship projects in Adobe, drop by "Foyer Sud - 118" or drop me a line :)
Happy to announce our paper got accepted at #CVPR2023!
We generate cinemegraphs from images by animating clothes using a CycleNet trained without real data.
This is the result of my internship at #AdobeResearch.
Website: https://t.co/NZMS0WfQEb
arXiv: https://t.co/Ty2ZLXjAK3