Creating the perfect abstraction isn't hard, but it does take patience. A beginner can get it right with three examples in hand. We need to wait until then. Planning is extremely useful but we need to be aware that no amount of it will grant us omniscience.
If you're looking for your next FLOSS project, coding a vim plugin for the open source ML model ReplitML might be a good candidate: https://t.co/uVLdCJvTBC
New little script that pops me into a temporary directory for a while until I Ctrl-d.
I'm always going to ~/tmp && mkdir blahblahwahtever to test something out. `tmpsh` saves a few seconds. :)
ACID transactions are best practice & every distributed product should support them. There are probably weird corner cases where the data isn't essential & you can try to get by without them. But in this case you should just assume that some of your data is corrupted. 9/x
Yes, your PostgreSQL triggers also need tests.
I've built myself a script to run tests on code change (feedback loop, good for TDD) which I might open source one day.
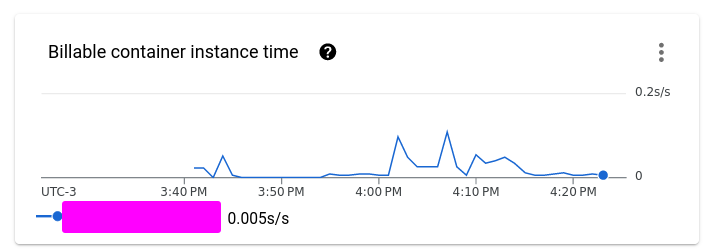
For scrapers, Google Cloud Scheduler + Google Cloud Run is magical. So robust. Publish the data to a PubSub and you can connect more consumers on demand. All cloud infra neatly written and documented as Pulumi scripts of course.
- If we want to preserve the zero-install experience of the web *and* enable rich web pages, we need *some* way to share objects across sites. We can't and shouldn't rely on browsers to implement the majority of APIs. There has to be some way for developers to do this.
For scrapers, Google Cloud Scheduler + Google Cloud Run is magical. So robust. Publish the data to a PubSub and you can connect more consumers on demand. All cloud infra neatly written and documented as Pulumi scripts of course.