Flat‑rate AI coding was a hidden surcharge on Curiosity. Vendors subsidized compute to capture your corrections.
Now they are pushing programmatic workflows to expensive API rates. GitHub Copilot switches to usage-based billing on June 1. Anthropic redefined interactive use to block third-party tools.
Cloud pricing penalizes complex system engineering. A single autonomous coding session can burn $30. Unpredictable token billing destroys budget forecasting.
Running models on-premise converts variable API fees into fixed capital expenses. You own the model. Your compute costs stay flat.
#SovereignAI #CloudCosts #VendorLockIn #h2loopai
Hydron is live.
AI for embedded engineers. Code grounded in your datasheet, your codebase, and your hardware context. VS Code + terminal.
v1, fresh out of beta. A lot works. A lot will get better.
Bring your worst MCU.
https://t.co/DPznW5MWgE
Bear the Tokens leaderboard: 5,066 tok/s on a single T4.
Qwen2.5-0.5B. 50 concurrent requests. One Colab to enter.
Submissions open till 1 June. Final deadline.
PS5 + Claude credits for the winners.
Inc42's 30 Startups To Watch, April 2026.
H2LooP made the list under AI and semiconductors.
Hardware-aware AI for systems engineering. Built for engineers who work with datasheets, not just docs.
Inc42's #30StartupsToWatch list, April 2026. H2LooP made it under AI and semiconductors.
https://t.co/r8PrVNs7sN
Two coding platform leaks in a month.
Lovable: a BOLA flaw let any free account read source code, credentials, and chat histories across other users' projects.
Claude Code: an internal sourcemap shipped in a public npm release, exposing roughly 500,000 lines of Anthropic's own code.
Different companies, different failure modes, same headline. The platforms holding your IP cannot reliably hold their own.
Every productivity gain from these tools comes with an implicit trade. Your source code, your credentials, your prompts, handed to a vendor whose recent track record says they cannot be trusted with it.
Two coding platform leaks in a month.
Lovable: a BOLA flaw let any free account read source code, credentials, and chat histories across other users' projects.
Claude Code: an internal sourcemap shipped in a public npm release, exposing roughly 500,000 lines of Anthropic's own code.
Prizes: PS5 for first place. Claude Code for top performers. Verified high scorers get a direct path into H2Loop. No interview, your benchmark is the application.
Optimize however you want.
Quantization. Flash attention. CUDA graphs. KV cache tuning. Speculative decoding. Anything that does not touch the harness is legal.
Bear the Tokens: one GPU, one model, one fixed workload.
Qwen2.5-0.5B. 50 concurrent requests. 512 in / 512 out tokens. The eval harness does not move.
H2LooP Spark CPT (Preview) is available now on HuggingFace under a Research Only License.
Works with vLLM and 🤗 Transformers. Single H100, bfloat16.
This is an early checkpoint
Paper → https://t.co/jNID1NG2JL
Request access → https://t.co/as6AwUTYTa
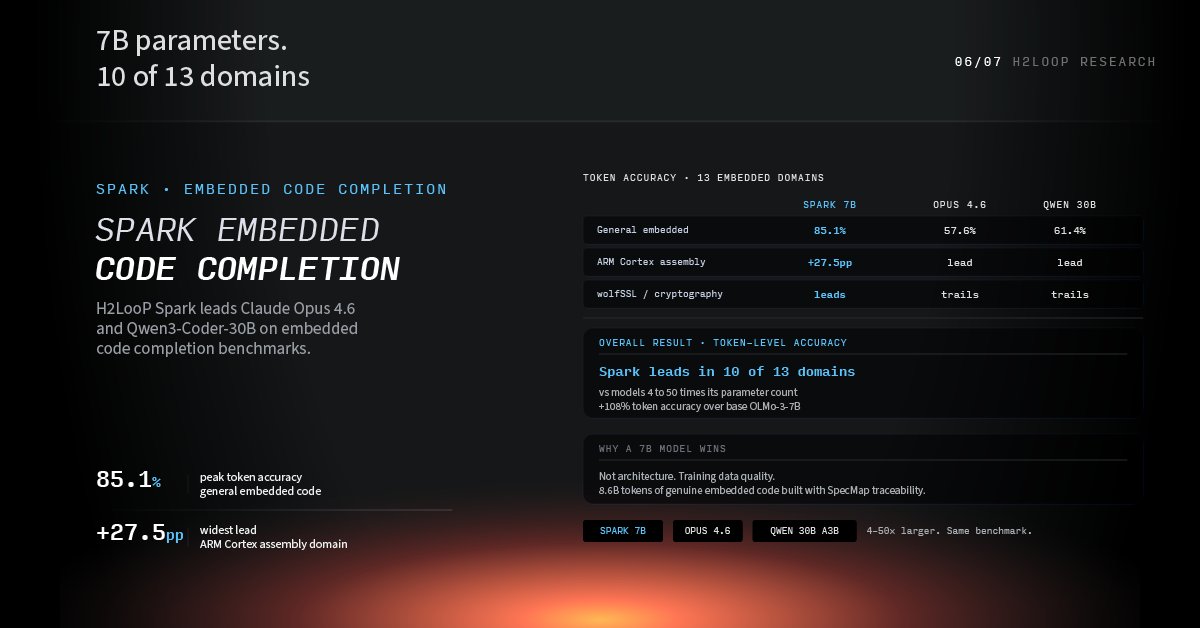
Introducing H2LooP Spark: the first domain-specialized autocomplete model for embedded software.
A 7B model that beats Claude Opus 4.6 and Qwen3-Coder-30B on embedded code completion.
Not fine-tuned. Continually pre-trained on 23B tokens of firmware, datasheets, and vendor SDKs
We built SpecMap: an agentic pipeline that maps vendor datasheets directly to code symbols, across 13 embedded domains 100B raw tokens curated down to 23B.
The result: a model that knows the exact register offset, the exact intrinsic opcode, and the exact pin mapping.
General LLMs fail at embedded code because
- Infineon TriCore intrinsics
- NXP eDMA scatter/gather docs, and
- AURIX ATOM timer pin maps
simply don't exist in standard pre-training data.
Token accuracy on held-out embedded code (13 domains, 9 repos never seen during training):
→ H2LooP Spark 7B: 34.1%
→ Qwen3-Coder-30B: 24.6%
→ Claude Opus 4.6: 24.1%
→ Base OLMo-7B: 16.8%
+108% over base. Leads frontier models that are 4–50x larger.