Last month thousands of developers from different countries showed up to build AI agents.
Now we're back.
HackerRank Orchestrate June edition is here to challenge the next generation of AI-native builders.
June 19 - 20 | Registrations close 18th June, 7:30 AM PT
Register now: https://t.co/cNSOEUq7Ov
From building agents online to being celebrated on the Innovator Awards stage.
At HackerRank Innovator Awards 2026, we’re proud to felicitate the winner of HackerRank Orchestrate, our agentic hackathon, who joins us all the way from Sri Lanka.
Orchestrate was built to spotlight the next generation of AI-native builders. This moment is exactly why.
#InnovatorAwards2026 #HackerRankOrchestrate
For the fifth time, we're rolling out the red carpet!
HackerRank Innovator Awards 2026 is back!!!
A night to celebrate the teams, leaders, and builders shaping the future of tech hiring.
#InnovatorAwards026
We’re excited to announce that Juan Herrera, President and Chief Revenue Officer at HackerRank, will deliver the keynote address at the HackerRank Innovator Awards 2026.
From developer skills to AI-native hiring, Juan will open the evening with a look at what comes next for the teams building the future.
Developers aren't just writing code anymore. They're orchestrating AI agents, reviewing AI-generated work, and deciding what's safe to ship.
The job has changed. The interview process has to keep up.
That's what our CEO @rvivek is talking about at @FD1conference, Manhattan on June 16.
How leading companies are rethinking technical hiring for the agentic era, and what it actually takes to make the shift.
Join us at Columbia's Lerner Hall: https://t.co/vKZNdTuDj4
Agents are getting better at doing the work. They’re still bad at knowing whether the work is done.
That’s one of the hardest problems in long-running agents. They can confidently stop after building half a feature.
The fix isn’t just "give it more context."
Two patterns matter more, and most teams skip them:
1. Don’t let the builder agent grade its own homework.
Use a separate evaluator agent to check the output against clear acceptance criteria.
2. Make failure predictable.
Break work into bounded loops with four constraints:
Fresh context for each loop, max iterations, stop conditions, and a clear exit criteria.
Trustworthy agents need a verifier and a clock. Most teams ship with neither.
Anyone can prompt. Few can build systems that actually deliver.
HackerRank Orchestrate is where developers prove they can do the second one.
24 hours. Real-world problem. Ship an AI agent that works.
June 19 - 20 | Virtual | Registrations close June 18, 8 PM IST
Register now: https://t.co/cNSOEUq7Ov
More MCP tools will just make your agent worse.
When your MCP has hundreds of tools to choose from it becomes a liability.
The model has to read every tool definition. Choose the right one, pass the right inputs, and not blow up the context window before the work even starts.
The better pattern isn't giving the agent more choices. It's giving it a cleaner way to find the right one.
Instead of giving the agent hundreds of preloaded tools, give it a smaller interface: search what exists, write the code, then execute the right call.
Behind every great team is someone who made the harder, better call.
Someone who looked past the resume and hired for what people could actually do.
The HackerRank Innovator Awards is the night that work gets recognized.
📍 The Ritz-Carlton, Bengaluru | June 12, 2026
Register now: https://t.co/Ggtrbl1npU
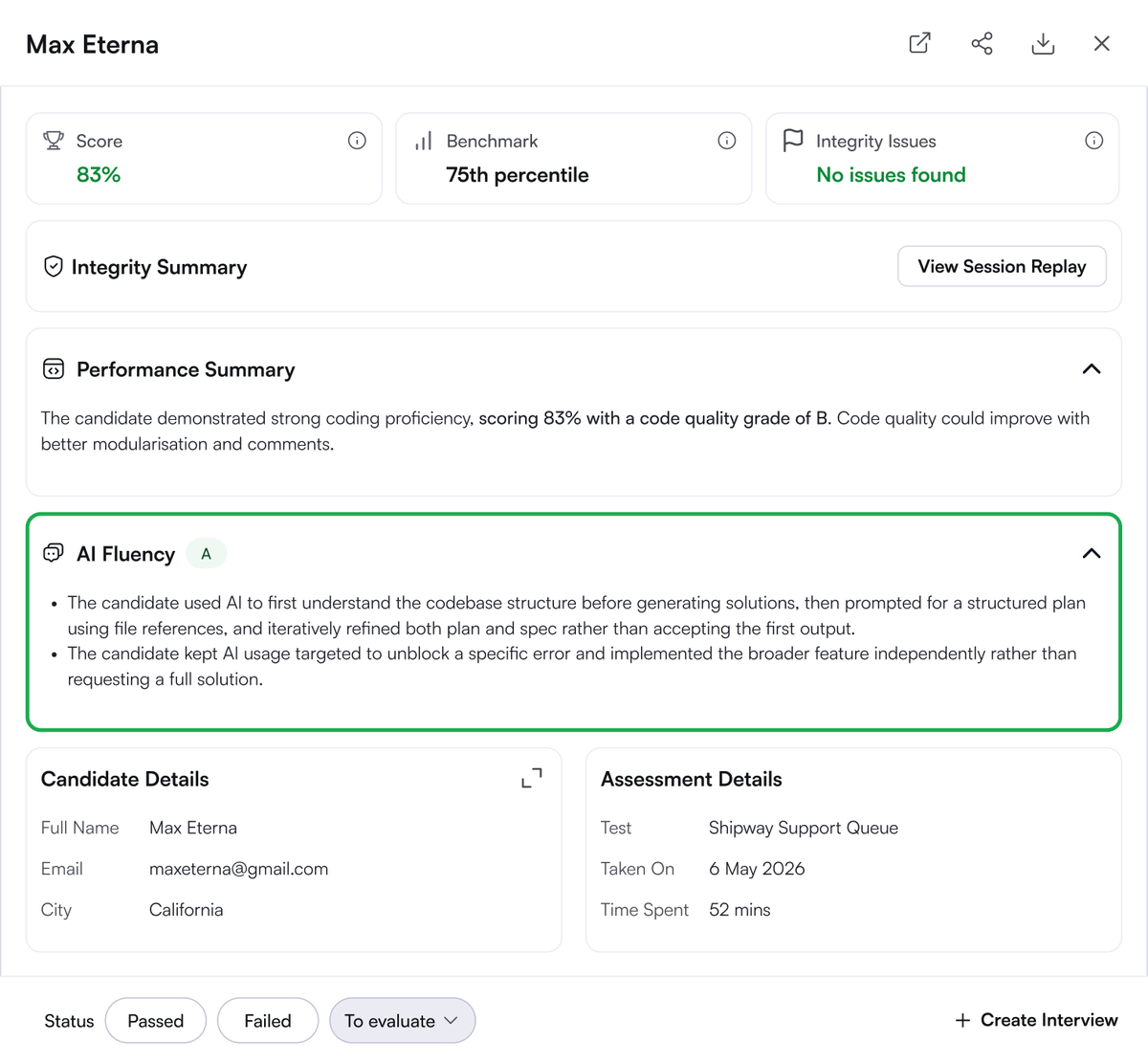
The LeetCode round in an interview tested one skill: writing code. AI does that easily now.
So we rebuilt the technical interview across the task, the evaluation, and the experience.
Meet HackerRank 2.0.
Old evaluation: can this candidate write functionally correct code?
New evaluation: can the candidate orchestrate AI?
We measure AI fluency, not just pass/fail.