btw I think @NousResearch is doing a fantastic job verticalizing (model + harness + inference)
HARNESS: ship (1) the best agent harness for (2) the devs that are consistently 3-6 months ahead of mainstream devs
INFERENCE: serve inference at scale via an @OpenRouter wrapper
MODEL: work with leading companies like @MiniMax_AI and smaller OS devs like @kaiostephens and @DJLougen to custom train models on the harness, making it recursively more effective
Once you have the OS community optimizing models for YOUR harness while larger labs increasingly CLOSE their ecosystem, the winner seems obvious.
Can’t get over the fact that enterprises “doing their own RL” feels like the equivalent to businesses “building their own railroads”. One difference is obviously that open source models have no railroad equivalent. Another difference is that my own railroad would at best likely be the same as an existing railroad, whereas custom RL promises to improve performance.
subagents, teams of agents etc. will be first class citizens soon (if not already)
two things here:
1) you want to maximize token efficiency even more
2) training/serving on your own harness gives you an even bigger boost than before
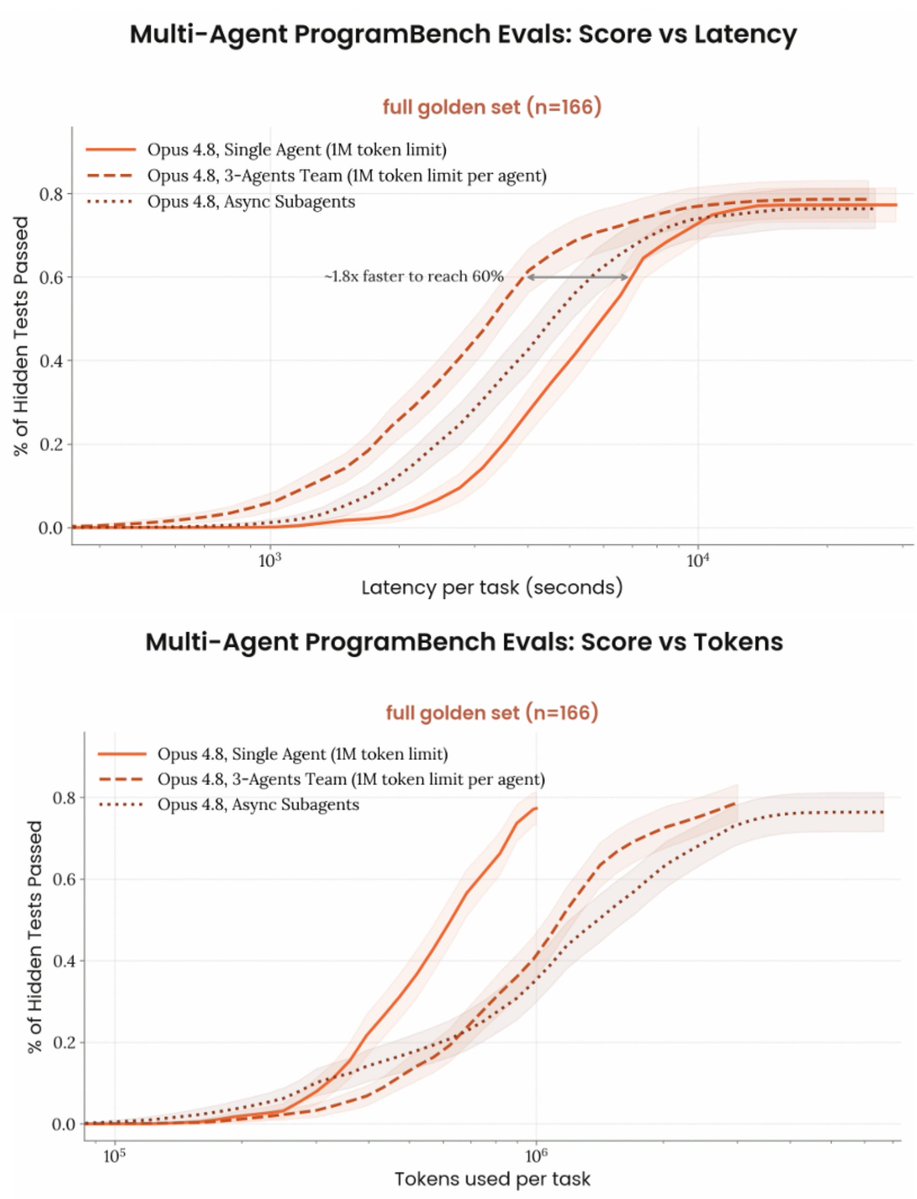
benchmarks in the opus 4.8 model card show that for now it's a latency vs cost tradeoff, but imo this will likely shift to intelligence/autonomy vs cost (think dynamic workflows or agent swarms). and for cost not to blow up too much, you need to maximize token efficiency even more
we'll also likely see huge gaps on more complex/autonomous benchmarks whether they use these features or not, a bit like when tool use was introduced. on those i'd expect third party harnesses to struggle to keep up with closed source models/harnesses
this is also a case for open source models (and maybe open harnesses like codex?). if you want deep control over this, doing your own RL to train the model in the environment you want it to operate in feels more important than ever
@sethkarten Do you think its worth the effort to train on a paradigm other than user/assistant for LLM MARL? To what extent is embodiment necessary for the LLM to participate in collaborative settings rather than help?
Most of RL relies on an oracle assumption (teacher, reward, etc) that makes it unsatisfying. Where is the research on LLMs motivated by intrinsic reward pointed at a specific emotion vector such as 'fulfillment'?
We present empirical evidence of the first general economic scaling law beyond language data.
We are incredibly excited to publish it, and definitively say:
Recursive Self-Improvement is
a Portfolio Optimization Problem
https://t.co/edRoJLiIxW
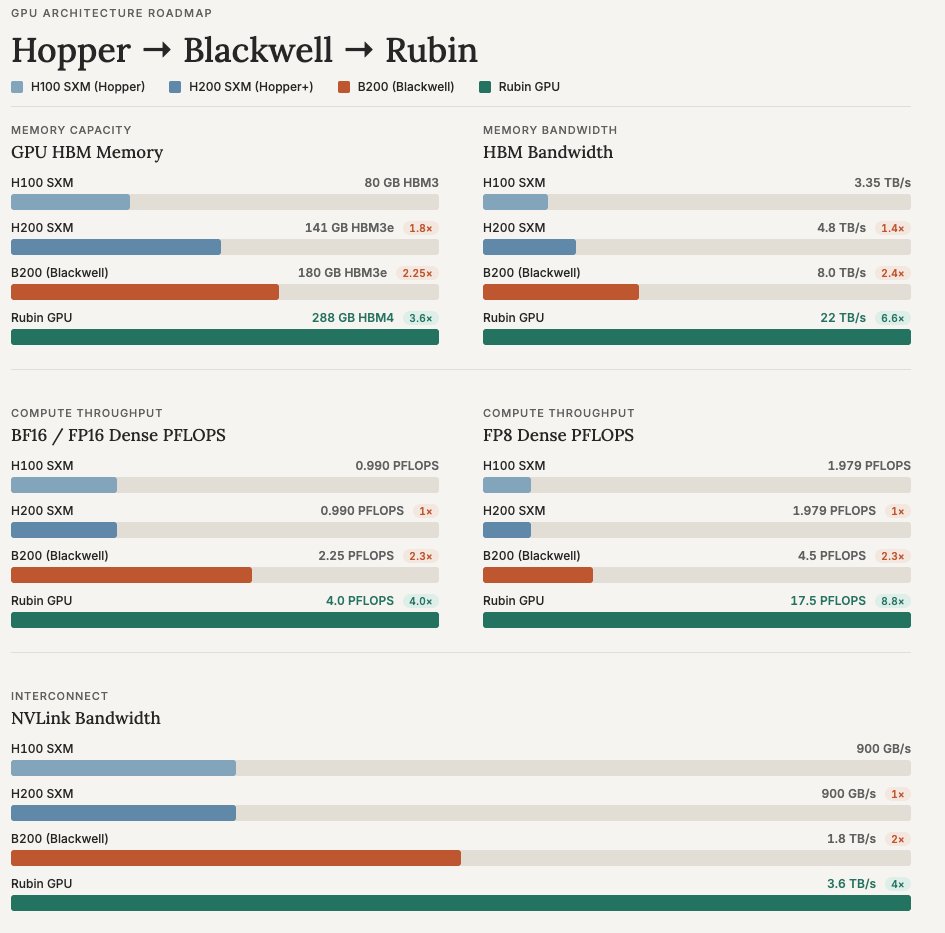
Comparison of the specs between Hopper, Blackwell and now Rubin.
Rubin NVLink bandwidth is now faster than H100's HBM bandwidth. This also doesn't include a 3-5x FP4 FLOPS increase between Blackwell and Rubin.
i think some people are hoping that self-distillation enables “exploration-free” RL purely via reflection on live data, allowing them to bypass the need for replayable environments
unfortunately, RL is all about exploration
my instinct is you basically need to model the world
The hard part of continual learning isn't getting the data, but training on a single rollout per task that's off-policy by the time you train. Trajectory's off-policy SDPO recipe stabilizes training and scales.
The technical post is well worth the read.
https://t.co/zwsmQilM2V
First Pong, then Doom and now one of my favourite game Mario Kart 🏎️. Fantastic work from Prof Sasitharan Balasubramaniam and his team at University of Nebraska-Lincoln. https://t.co/v1CqAbfIiy