If you are into OPD (on-policy distillation), please don't forget to check our Speculative OPD (Speculative Knowledge Distillation).
Idea: For each token, sample it from the student but discard if it teacher is unlikely to generate it (top-K), and resample from teacher. This dynamically switches between on-policy and supervised distillation.
🧩 How can we assign fine-grained credit over long tool-use trajectories and let agents learn from past attempts in agentic reinforcement learning when rewards are no longer verifiable?
Excited to share RubricEM, an RL framework for long-form deep research agents that plan, search, use tools, and write reports without exact answer checks.
📖 Paper: https://t.co/t1tksq5g30
(1/n)
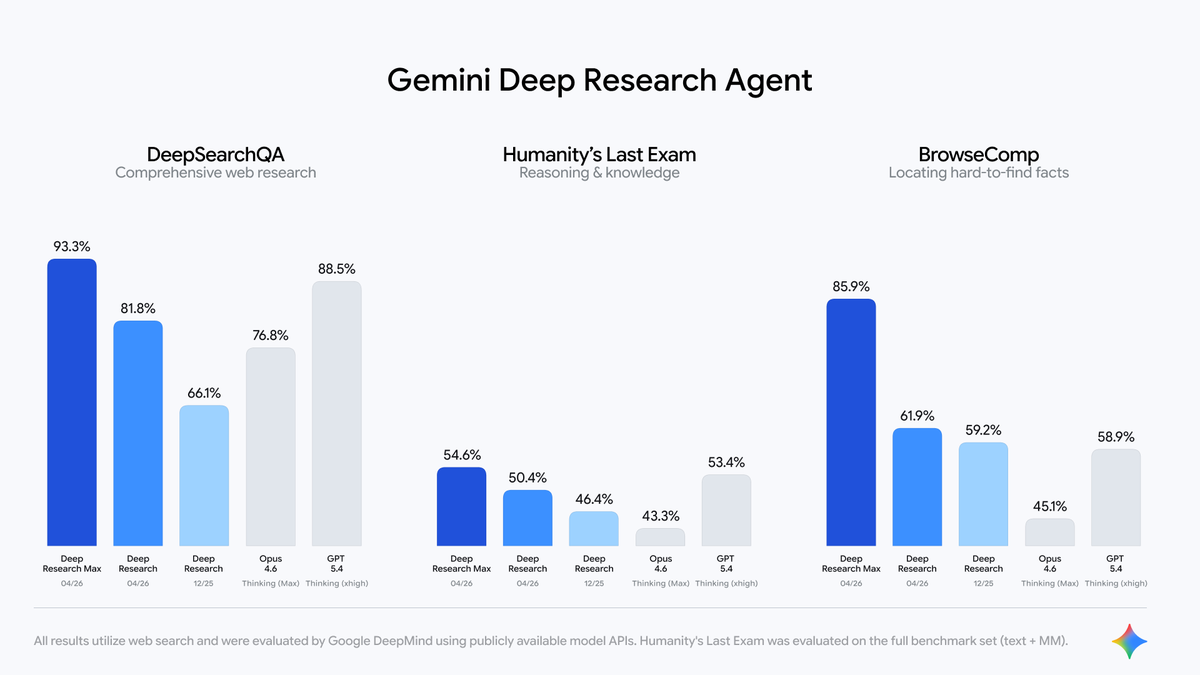
We are launching two powerful updates to Deep Research in the Gemini API, now with better quality, MCP support, and native chart/infographics generation.
Use Deep Research when you want speed and efficiency, and use Max when you want the highest quality context gathering & synthesis using extended test-time compute — achieving 93.3% on DeepSearchQA and 54.6% on HLE.
We are launching two powerful updates to Deep Research in the Gemini API, now with better quality, MCP support, and native chart/infographics generation.
Use Deep Research when you want speed and efficiency, and use Max when you want the highest quality context gathering & synthesis using extended test-time compute — achieving 93.3% on DeepSearchQA and 54.6% on HLE.
Attending #EACL2026 and will present our paper https://t.co/IgqBeVNsGl at Findings Poster Session 6 at 11am on March 27. Please come by and ask any questions if you are around, and happy to discuss internship and full-time opportunities at Google Cloud AI Research.
🚀 New paper on synthetic data generation for deep search agents (accepted to #EACL2026 Findings)!
We introduce SAGE, an agentic pipeline for generating high-quality, difficulty-controlled training data for deep search agents on a given corpus, using execution feedback.
Transfer: Even though SAGE generates data using a fixed corpus (Wikipedia), we show agents trained on it can adapt to Google Searchat inference time without further training, though further research is needed in this direction.
🏧Giving your agent unlimited tool calls doesn't make it smarter.
💡Why? It lacks 'Budget Awareness'!
Introducing Budget Tracker, a simple plug-in that enables more effective scaling behaviors: higher performance, lower cost.
Paper: https://t.co/aKm2Tzt1wx
🧠🚀 Excited to introduce Supervised Reinforcement Learning—a framework that leverages expert trajectories to teach small LMs how to reason through hard problems without losing their minds. 🤯
Better than SFT && RLVR.
Read more: https://t.co/taEL8Vk4X5
#llms#RL#reasoning
Excited to share our #ACL2025NLP paper, "𝐂𝐢𝐭𝐞𝐄𝐯𝐚𝐥: 𝐏𝐫𝐢𝐧𝐜𝐢𝐩𝐥𝐞-𝐃𝐫𝐢𝐯𝐞𝐧 𝐂𝐢𝐭𝐚𝐭𝐢𝐨𝐧 𝐄𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 𝐟𝐨𝐫 𝐒𝐨𝐮𝐫𝐜𝐞 𝐀𝐭𝐭𝐫𝐢𝐛𝐮𝐭𝐢𝐨𝐧"! 📜 If you’re working on RAG, Deep Research and Trustworthy AI, this is for you. Why? Citation quality is critical for trust, but current metrics are falling short. Let’s fix that!
🧵 [1/10]
Can many-shot ICL be cached and still tailored per test sample?
We make it possible. 💡
Excited to share that our paper, "Towards Compute-Optimal Many-Shot In-Context Learning," has been accepted to @COLM_conf!
Paper: https://t.co/lBf4z5VCHN
#COLM2025#LLMs#AI#ICL
We performed in-depth analysis to show that diversity of search directions and timely incorporation of retrieved information help research agents scale more effectively. Read our paper for more detailed analysis: https://t.co/tDXt8vxlsV
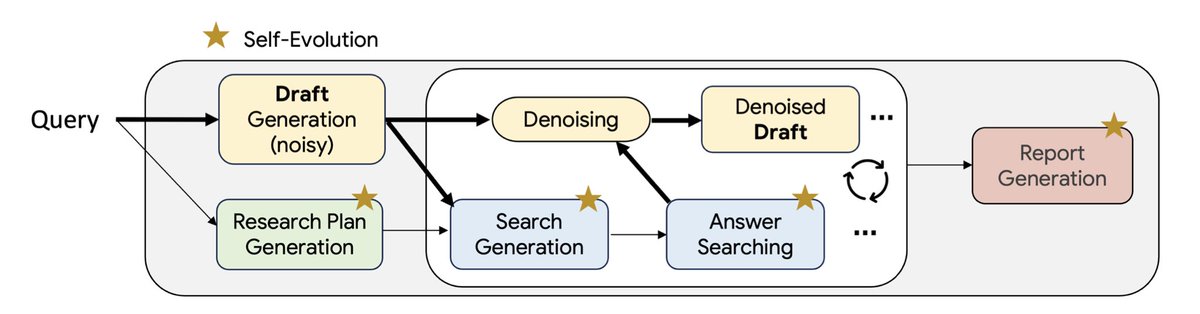
Very excited to share the project I've been working on over the past several months! We proposed Deep Researcher with Test-Time Diffusion, a novel method to leverage iterative draft+revision to tackle complex questions demanding exhaustive search and reasoning.
Further enhanced by self-evolving algorithms, we achieved SOTA results over a variety of research benchmarks with broad coverage of industry domains such as finance, technology, biomedical and legal.


































![yumo_xu's tweet photo. Excited to share our #ACL2025NLP paper, "𝐂𝐢𝐭𝐞𝐄𝐯𝐚𝐥: 𝐏𝐫𝐢𝐧𝐜𝐢𝐩𝐥𝐞-𝐃𝐫𝐢𝐯𝐞𝐧 𝐂𝐢𝐭𝐚𝐭𝐢𝐨𝐧 𝐄𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 𝐟𝐨𝐫 𝐒𝐨𝐮𝐫𝐜𝐞 𝐀𝐭𝐭𝐫𝐢𝐛𝐮𝐭𝐢𝐨𝐧"! 📜 If you’re working on RAG, Deep Research and Trustworthy AI, this is for you. Why? Citation quality is critical for trust, but current metrics are falling short. Let’s fix that!
🧵 [1/10]](https://pbs.twimg.com/media/GwsBuCTbgAMVXDg.jpg)