A lot of useful training data can't be shared due to privacy. How do we create synthetic training data without data owners ever sharing their content?
🚀 Introducing 𝐃𝐏-𝐑𝐅𝐓: using RL to train LLMs to generate high-fidelity domain data without seeing a single private sample.
People are increasingly worried that AI tools make us overreliant.
But how do we actually measure this? We introduce Offloading Score, a measure of reliance based on the fraction of cognitive effort offloaded to AI while completing a task.
In a controlled user study, Offloading Score detects increased reliance under time pressure, while several common alternatives do not.
(1/9)
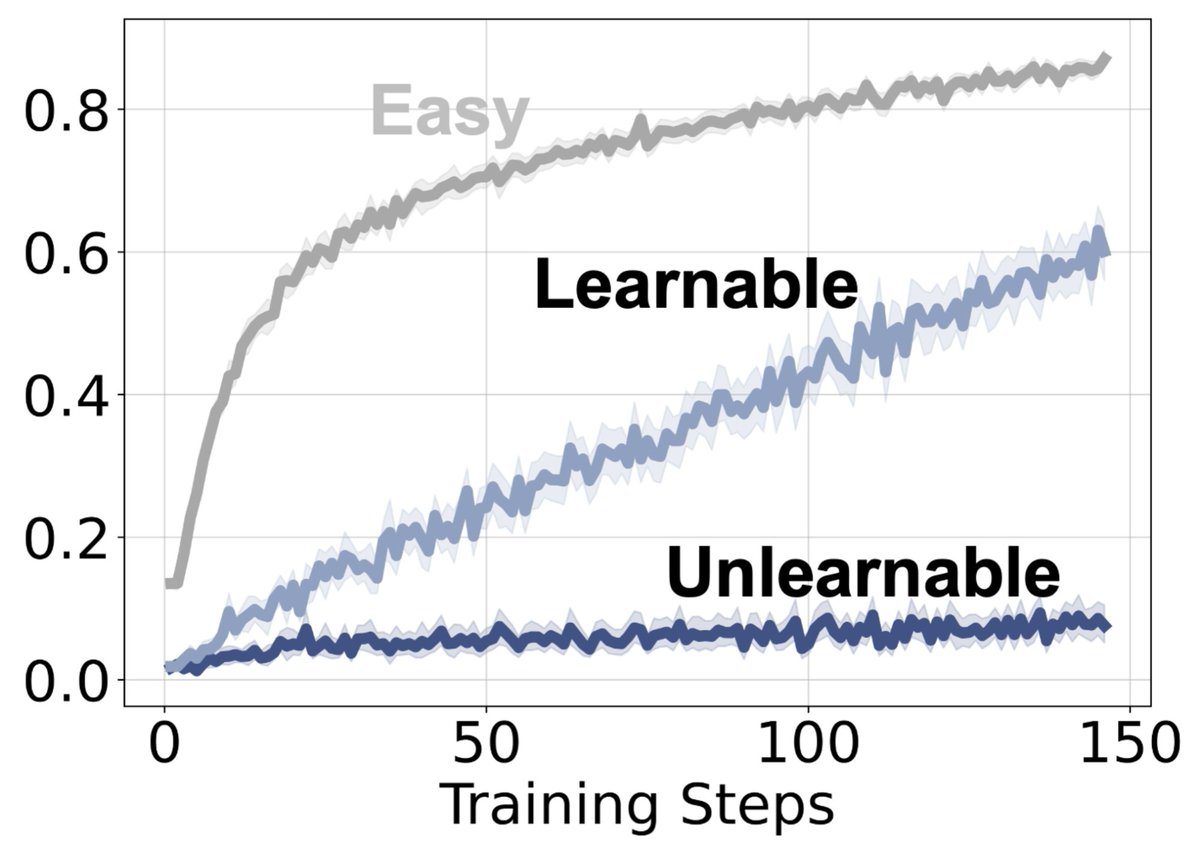
Most assume unlearnable examples never get positive reward. They do.
In our ICML paper, We reveal that a hard problem can receive positive reward during RLVR but remain unlearned.
We show the phenomenon is more likely a representation issue rather than RL optimization artifact.
New paper! 🏁 My final one from my PhD at UT Austin.
🦜LLMs sound empathic, but they keep saying the same thing over and over.
Not just the same words, the same discourse moves, turn after turn.
We found that LLMs repeat the same discourse moves at nearly 2x the rate of human supporters across a multi-turn conversation, and existing metrics don’t catch this.
So we built MINT 🌿 (Multi-turn Inter-tactic Novelty Training), the first RL framework to optimize discourse move diversity in multi-turn empathic dialogue. +25% empathy, −26% repetition.
w/ @jessyjli@_desmond_ong et al.
📄 https://t.co/fJ8IvkXkbM
Can LLMs generate diverse outputs for open-ended questions? Is it helpful if we ensemble outputs from multiple models? We study 18 LLMs on 4 datasets and find that no single model is best at generating diverse outputs 👇/ 🧵
Really excited to have this dataset released to the community! There's a gap in our understanding of how users interact with coding agents at scale. SWE-chat fills that need to help shape the next generation of human-centered evals and training objectives for coding agents! 🤖🚀
🧵 1/8
What should an LLM assistant remember across conversations?
Existing memory work studies this one task at a time. But real-world assistants see all kinds of conversations, and that changes the problem.
Introducing BEHEMOTH 🦣 + CluE 🌱: a benchmark & self-evolving method for heterogeneous memory extraction.
📄 Paper: https://t.co/szLIOdA4bm
Excited to share our new work from Meta MSL 🔥
LLMs write great Python/C++ but struggle with uncommon languages. Data scarcity is the bottleneck ⌛ Can we leverage cross-PL transfer to overcome this? Yes ✅
A new method to unlock cross-PL transfer 🧵 https://t.co/8EK05gMgCl
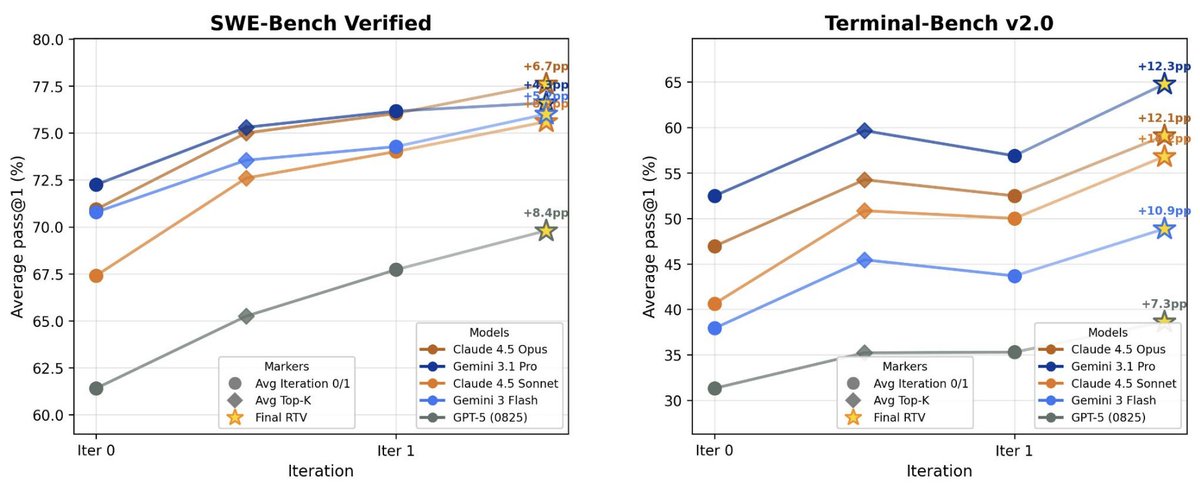
New work @AIatMeta: We enable test-time scaling for long-horizon coding agents by using better representations, selection and reuse of agentic trajectories, with Claude 4.5 Opus improving by +6.7% on SWE-Bench Verified and +12.1% on Terminal-Bench 2.0.
📄: https://t.co/tvhdw0DuYd
How should we effectively aggregate long-horizon agent trajectories? 🧐
Unlike CoT reasoning, agentic tasks pose unique challenges: they are long, multi-turn, and tool-augmented.
Introducing 👉🏻 AggAgent 👈🏻 — which treats parallel trajectories as an environment to interact with.
Would you realize if the book you were reading was AI? What if it was humanized to remove AI-speak?
We find that even without using stylistic cues (e.g., word choice or sentence structure) narrative choices alone give AI fiction away!
PhD defended at UT Austin today.🤘
The best thing was having an advisor who believed in me before I believed in myself.
Jessy taught me how to write, how to think, and how to chase research ideas. Then the rest followed.
Thank you, @jessyjli
👀 Can AI produce a novel worth reading? We built a platform to find out.
📚 Introducing AutoFiction: a web platform that hosts AI-generated novels by Claude Code & Codex, rated and reviewed by real readers.
We have 33 books so far, spanning dark fantasy, murder mysteries, Harry Potter fanfics, and more. All free to read.
(1/n)
Auto research is on 🔥
We give algorithmic problems (like circle packing) to general coding agents, let it run overnight. 🌙
Agents reach SoTA. But more importantly: we analyze 100+ hours of trajectories to understand how it gets there 🧵
Proud to share our CHI 2026 Honorable Mention paper, Evalet! 🏅
LLM-as-a-Judge is everywhere, but a single score hides so much. Evalet fragments outputs into functional units so you can see exactly what's working and what's not—across hundreds of outputs, from reasoning traces to red-teaming conversations to computer-use agents. I had a great time working on this project led by the amazing @tae_skim and @heechanleekr, with @josephseering and @imjuhokim !
Check out the full breakdown below ⬇️
1/5 How do we update a model trained in 2025 with new world knowledge from 2026?
⚠️Continued training will undo skills learned by LLMs during post-training, e.g. instruction-following/math/code.
🤝Our method DiSC updates LLMs with new knowledge while preserving existing skills!
In 2023, WebArena took 7 grad students more than 6 months to build just 5 environments with 812 variable browser-use tasks.
Now, it takes under 10 hours and less than $100 per environment, with easy support for parallel generation.
Excited to introduce WebArena-Infinity: a scalable approach for automatically generating high-authenticity, high-complexity browser environments with verifiable tasks suitable for RL training and benchmarking.
Even strong open-source models that already achieve 60%+ success rates on WebArena and OSWorld complete fewer than 50% of tasks here.
Project page: https://t.co/tEtYkChMBt
Repo: https://t.co/lBg69T12xx 🧵 (1/n)
Your LLM already knows the answer. Why is your embedding model still encoding the question?
🚨Introducing LLM2Vec-Gen: your frozen LLM generates the answer's embedding in a single forward pass — without ever generating the answer. Not only that, the frozen LLM can decode the embedding back into text.
🏆 SOTA self-supervised embeddings
🛡️ Free transfer of instruction-following, safety, and reasoning