How should we effectively aggregate long-horizon agent trajectories? 🧐
Unlike CoT reasoning, agentic tasks pose unique challenges: they are long, multi-turn, and tool-augmented.
Introducing 👉🏻 AggAgent 👈🏻 — which treats parallel trajectories as an environment to interact with.
Hooded six PhD students yesterday, my very first cohort at Princeton: Zexuan Zhong (@ZexuanZhong, 2024), Dan Friedman (@danfriedman0, 2025), Howard Chen (@__howardchen, 2025), Mengzhou Xia (@xiamengzhou, 2025), Tianyu Gao (@gaotianyu1350, 2025), and Alex Wettig (@_awettig, 2026)!
They started their PhD at the beginning of the pandemic and lived through one of the most revolutionary stretches our field has ever seen. Their work has shaped how we think about language models today. So proud of them, and can't wait to see what they do next!
MoEs are everywhere in frontier models, and they are deployed as a monolith system.
But many applications only need a narrow slice of capabilities, e.g., math, code, biomedical, etc.
So what if "modularity" is actually the missing opportunity for MoEs?
Today, we're releasing EMO: an end-to-end pretrained MoE where modularity emerges naturally, enabling selective use of experts!
We've released 8 parallel base rollouts for each (model x dataset) pair. Check out the links below: 👇👇
DeepSearchQA, HLE, HealthBench, ResearchRubrics
https://t.co/PpB01h1l4a
BrowseComp, BrowseComp-Plus
https://t.co/PLFHNtq1MD
How should we effectively aggregate long-horizon agent trajectories? 🧐
Unlike CoT reasoning, agentic tasks pose unique challenges: they are long, multi-turn, and tool-augmented.
Introducing 👉🏻 AggAgent 👈🏻 — which treats parallel trajectories as an environment to interact with.
Can LLMs generate diverse outputs for open-ended questions? Is it helpful if we ensemble outputs from multiple models? We study 18 LLMs on 4 datasets and find that no single model is best at generating diverse outputs 👇/ 🧵
RLVR gives sparse supervision; On-Policy Self-Distillation often requires high-quality demonstrations. Our new method, ✨SD-Zero✨, gets the best of both worlds – we use model’s self-revision to turn binary rewards into dense token-level supervision. No external teacher. No curated demonstrations.
🚨 Introducing Self-Distillation Zero (SD-Zero), which trains one model to play two roles: (1) “Generator” that makes attempts, and (2) “Reviser” that conditions on the generator’s failed/successful attempt + binary reward to produce a better answer. ‼️Even WRONG attempts can become the training signal.‼️
🔗Paper: https://t.co/LwboIqHE11
🏆 SD-Zero brings 10%+ improvement over base models (Qwen3,4B; Olmo3,7B) on math & code reasoning, beating GRPO and vanilla On-Policy Self-Distillation under the same training budget. SD-Zero also enables iterative self-evolution.
Hi Keivan, thanks for sharing your work!
1. While we haven't experimented in the paper, we believe this could be naturally extended to other agentic tasks such as swe and web navigation. For long-context or long-horizon reasoning tasks, it is a bit trickier as we can not exploit the structure of agentic trajectory when designing the tools. One could explore more careful design of how aggagent should traverse the context, or use scaffold like RLM for parallel rollouts.
2. One potential reason could be agentic search and deep research being different from long-context QA. This also largely depends on how well the base models are consistent, well calibrated, etc. We find our findings align with prior works (Figure 4 in https://t.co/R5dB9vaiZP, Table 3 in https://t.co/Q8AmuJxZog).
How should we effectively aggregate long-horizon agent trajectories? 🧐
Unlike CoT reasoning, agentic tasks pose unique challenges: they are long, multi-turn, and tool-augmented.
Introducing 👉🏻 AggAgent 👈🏻 — which treats parallel trajectories as an environment to interact with.
@lihanc02@18jeffreyma Hi Hanchen, thanks for sharing your work. And yes, all these prompt optimization, parallel aggregation, sequential refinement, and harness engineering could be applied together at test time!
Nicely done. Mixture of Agents type of approach does work. And most importantly it works better than majority vote, which is one of the final bosses of test time scaling. We found something similar in https://t.co/qxkkEFGzTz!
Check out our paper for more analysis and discussion 📊
📄 Paper: https://t.co/0NnhMO78XW
💻 Code: https://t.co/hpMyxqnjyE
💾 PyPI: https://t.co/9fnRyuFxgQ
👾 Claude Code skill: https://t.co/2HDYwJzhJs
Thanks to amazing collaborators @HowardYen1@xiye_nlp@danqi_chen
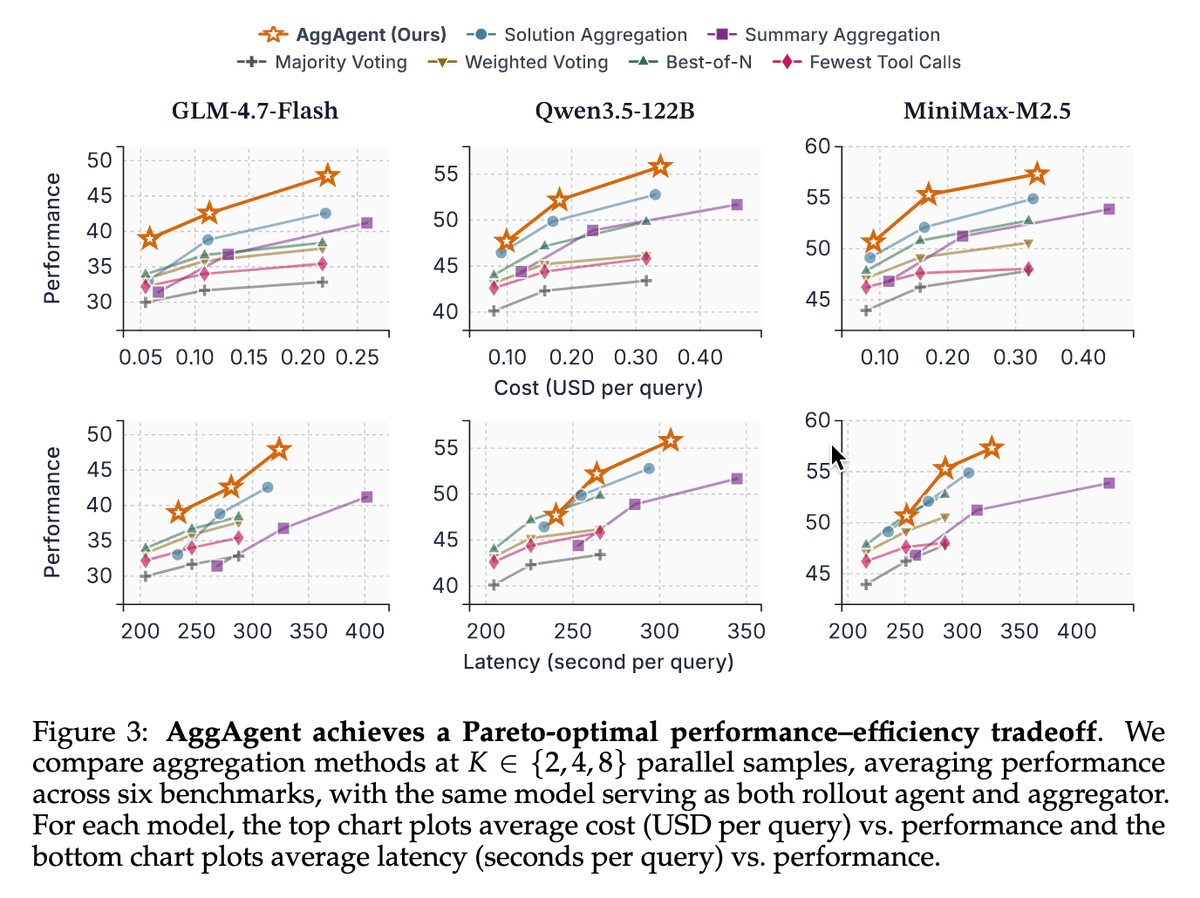
AggAgent also achieves Pareto-optimal cost and performance trade-offs✨
Together, our findings establish agentic aggregation as an effective and cost-efficient approach to parallel test-time scaling.
Do LLMs suffer from human-like cognitive biases? 🤔 Check out @arhjhaveri's new paper on how models navigate hypothesis spaces. We found that confirmation bias degrades LLM performance, and we explore strategies to mitigate it.
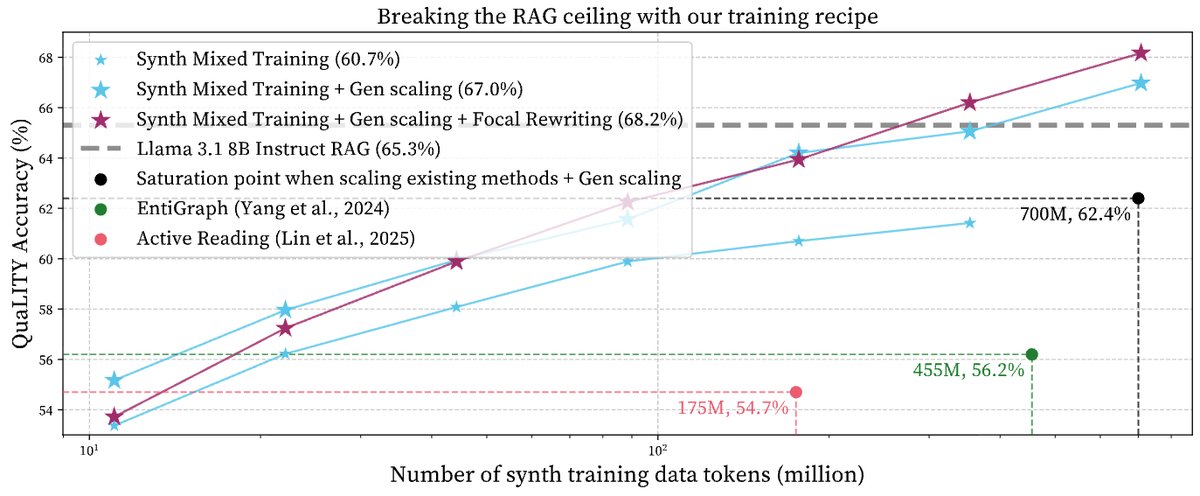
can synthetic training beat RAG in data-constrained domains?
we suggest a simple recipe for better synthetic training:
- Synth Mixed Training: train on both synth QAs and synth docs
- Focal Rewriting: rewrite docs with targeted topic prompts
results:
- beats RAG by +2.6% on QuaLITY
- improves to +4.4% with Focal Rewriting
- reaches +6.7% when combined with RAG
Paper: https://t.co/0rnfqUH5nE