VLMs can compress text by rendering it as images, but accuracy collapses once images shrink below a certain resolution.
We introduce LensVLM: teach the model to scan compressed images, then selectively decompress what it needs.
Paper: https://t.co/D2ECVMH6C9
In a new blog post, @HowardYen1 and @xiye_nlp introduce HELMET and LongProc, two benchmarks from a recent effort to build a holistic test suite for evaluating long-context LMs.
Read now: https://t.co/8wfh1Qp2ES
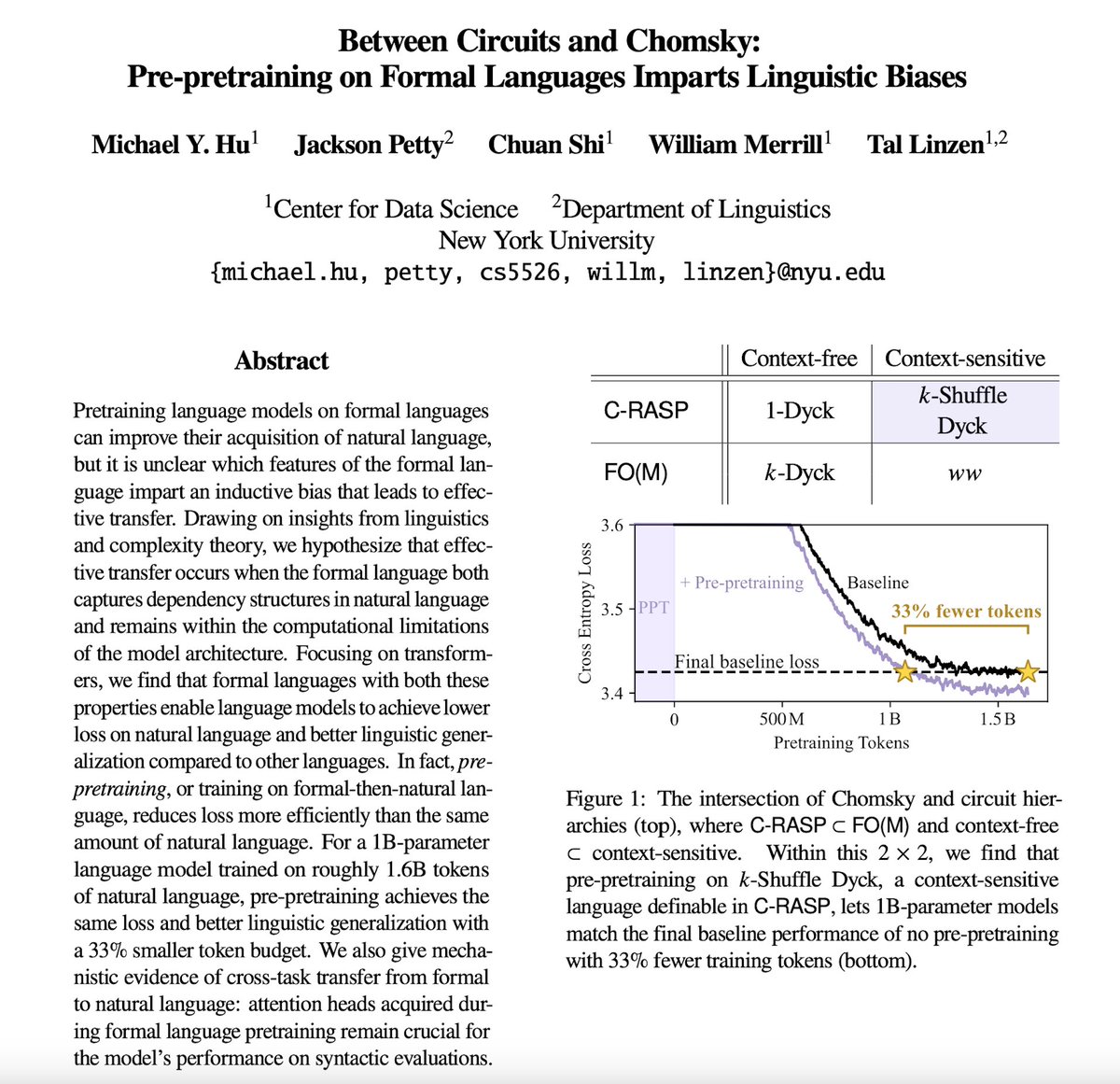
Training on a little 🤏 formal language BEFORE natural language can make pretraining more efficient!
How and why does this work? The answer lies…Between Circuits and Chomsky.
🧵1/6👇
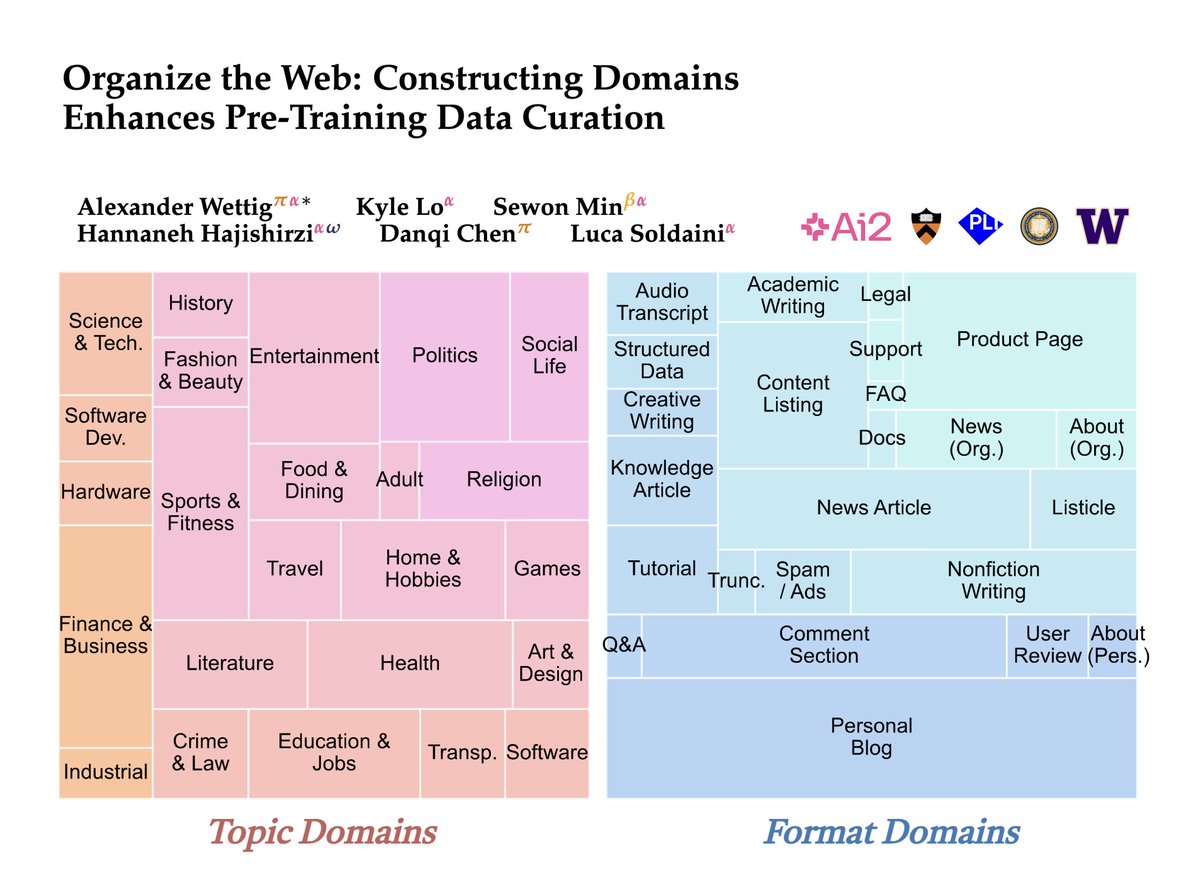
🤔 Ever wondered how prevalent some type of web content is during LM pre-training?
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N
Does all LLM reasoning transfer to VLM? In context of Simple-to-Hard generalization we show: NO! We also give ways to reduce this modality imbalance.
Paper https://t.co/S0HhYN7cvz
Code https://t.co/GJsgZof2k7
@Abhishek_034@chengyun01@dingli_yu@anirudhg9119@prfsanjeevarora
Introducing MeCo (metadata conditioning then cooldown), a remarkably simple method that accelerates LM pre-training by simply prepending source URLs to training documents.
https://t.co/46dtUUVb0P
I’m hiring PhD students in computer science at Columbia!
Our lab will tackle core challenges in understanding and controlling neural models that interact with language.
for example,
- methods for LLM control
- discoveries of LLM properties
- pretraining for understanding
🔔 I'm recruiting multiple fully funded MSc/PhD students @UAlberta for Fall 2025! Join my lab working on NLP, especially reasoning and interpretability (see my website for more details about my research).
Apply by December 15!
(1/5) Very excited to announce the publication of Bayesian Models of Cognition: Reverse Engineering the Mind. More than a decade in the making, it's a big (600+ pages) beautiful book covering both the basics and recent work: https://t.co/5dnLpcMQzu
🤖🧠 I'll be considering applications for postdocs & PhD students to start at Yale in Fall 2025!
If you are interested in the intersection of linguistics, cognitive science, & AI, I encourage you to apply!
Postdoc link: https://t.co/8Ds8X3OQf9
PhD link: https://t.co/HQWq47B7ss
I am recruiting PhD students for Fall 2025 at Cornell Tech! If you are interested in topics relating to machine learning fairness, algorithmic bias, or evaluation, apply and mention my name in your application: https://t.co/EU0Zu56Qo9
Also, go vote!
I'm recruiting PhD students for our new lab, coming to Boston University in Fall 2025!
Our lab aims to understand, improve, and precisely control how language is learned and used in natural language systems (such as language models).
Details below!
Progressive distillation, where a student model learns from multiple checkpoints of the teacher, has been shown to improve the student–but why? We show it induces an implicit curriculum that accelerates training.
Work w @BingbinL, @SadhikaMalladi, @risteski_a, @SurbhiGoel_
🤖🧠NOW OUT IN PNAS🧠🤖
Language models show many surprising behaviors. E.g., they can count 30 items more easily than 29
In Embers of Autoregression, we explain such effects by analyzing what LMs are trained to do
https://t.co/lJIWx89YpJ
Major updates since the preprint!
1/n
🤖 NEW PAPER 🤖
Chain-of-thought reasoning (CoT) can dramatically improve LLM performance
Q: But what *type* of reasoning do LLMs use when performing CoT? Is it genuine reasoning, or is it driven by shallow heuristics like memorization?
A: Both!
🔗 https://t.co/LR8VrBqxGk
1/n
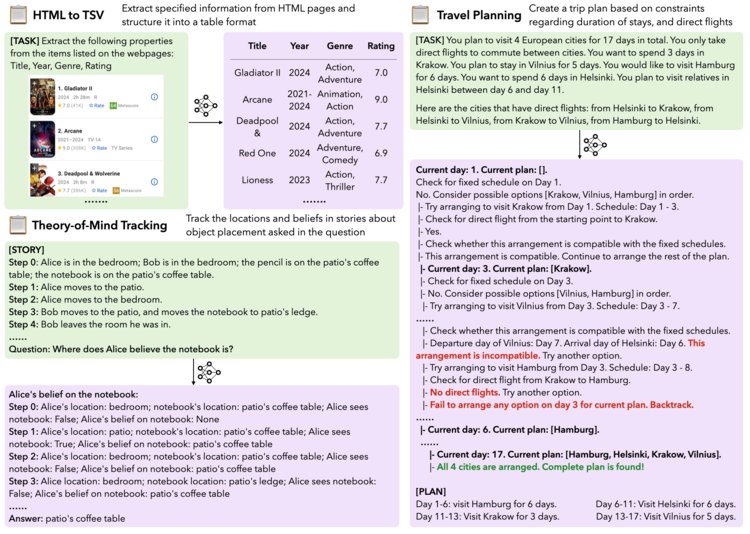
We're launching SWE-bench Multimodal to eval agents' ability to solve visual GitHub issues.
- 617 *brand new* tasks from 17 JavaScript repos
- Each task has an image!
Existing agents struggle here! We present SWE-agent Multimodal to remedy some issues
Led w/ @_carlosejimenez
🧵
Very proud to introduce two of our recent long-context works:
HELMET (best long-context benchmark imo): https://t.co/xF5MwlJORz
ProLong (a cont’d training & SFT recipe + a SoTA 512K 8B model): https://t.co/PmaVyRRa4X
Here is a story of how we arrived there
Meet ProLong, a Llama-3 based long-context chat model! https://t.co/zyZ0f5ucyI (64K here, 512K coming soon)
ProLong uses a simple recipe (short/long pre-training data + short UltraChat, no synthetic instructions) and achieves top performance on a series of long-context tasks.
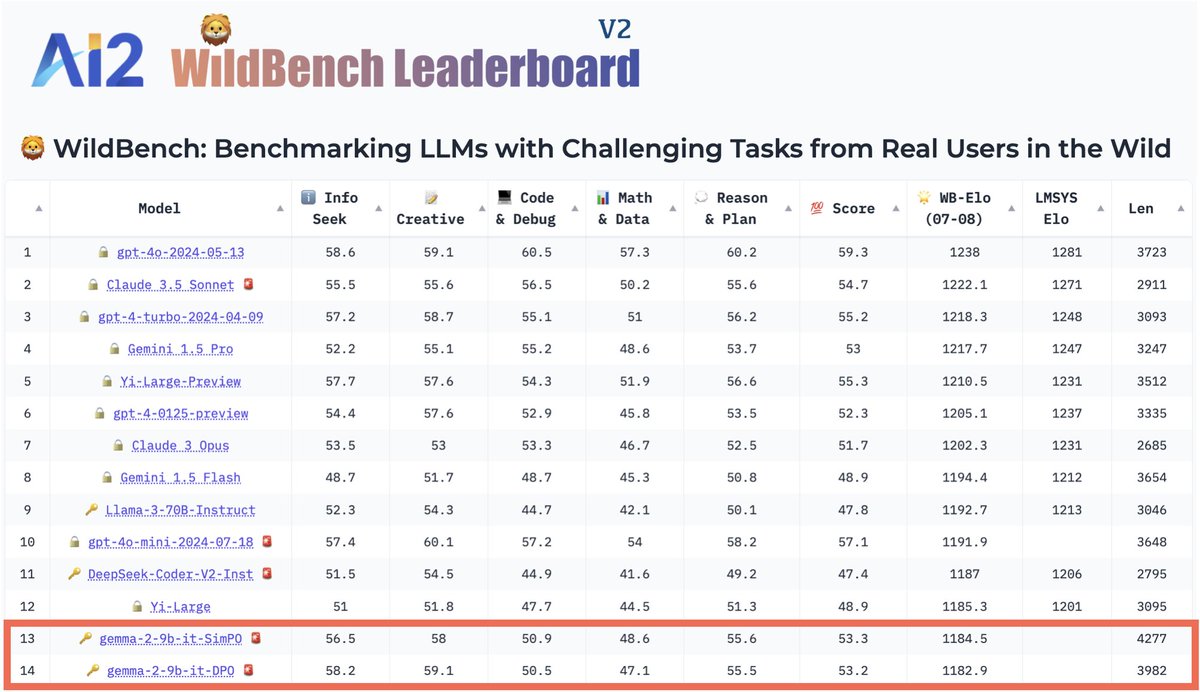
🌟 Exciting update! Gemma2-9b + SimPO ranks at the top of AlpacaEval 2 (❗LC 72.4) and leads the WildBench leaderboard among similar-sized models 🚀
SimPO is at least competitive as (and often outperforms) DPO across all benchmarks, despite its simplicity.
✨ Recipe: on-policy data annotated by a strong reward model + SimPO
💪 Strong performance on chat benchmarks (i.e., AlpacaEval 2, Arena-Hard and WildBench)
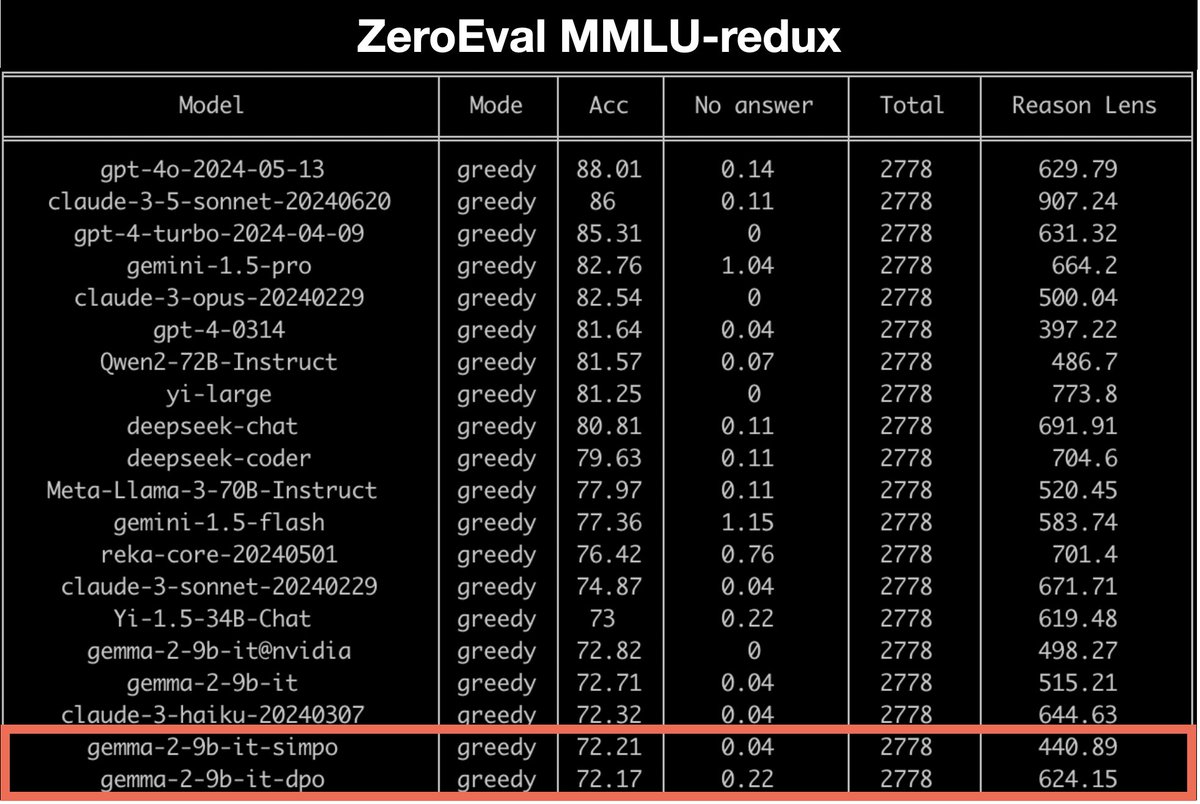
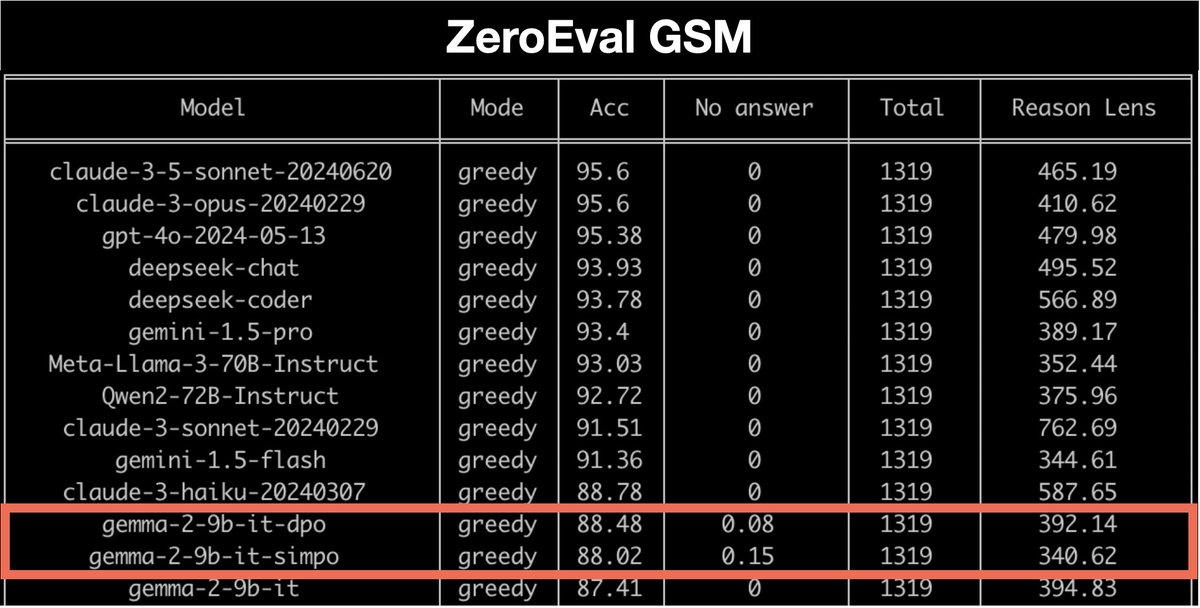
📈 Retains GSM8K and MMLU scores in ZeroEval
🔢 Understands that 9.11 is bigger than 9.8
🔗 More details at https://t.co/oMhhPespd7
🔬 Through extensive experiments, we find that
- gemma-2-9b-it exhibits significantly less catastrophic forgetting than Llama-3-8b-Instruct during fine-tuning and is more robust to different learning rates
- With a small learning rate, both DPO and SimPO can improve math domains
- SimPO has large gains over DPO when the SFT model is weaker, or the PO data is noisy. The gap is reduced when the model and data quality improve.
- We also made several major updates to our preprint, added more baselines (i.e., RRHF, SLiC-HF, and CPO), conducted KL divergence analysis since SimPO has no regularization, and investigated adding an additional SFT term.
🌟 More insights in our preprint: https://t.co/hok51xtACX. And we welcome feedback and look forward to discussions!
Joint work with @yumeng0818 and @danqi_chen. And Many thanks to @yanndubs@billyuchenlin@infwinston@LiTianleli for maintaining the amazing benchmarks!
If you are attending ICML this year, stop by our workshop on long-context foundation models!
Schedule: https://t.co/xROLEaxvVO
Also, RSVP for our social event with our sponsor @togethercompute on July 24: https://t.co/A53a7OxdBP 🥳