Hooded six PhD students yesterday, my very first cohort at Princeton: Zexuan Zhong (@ZexuanZhong, 2024), Dan Friedman (@danfriedman0, 2025), Howard Chen (@__howardchen, 2025), Mengzhou Xia (@xiamengzhou, 2025), Tianyu Gao (@gaotianyu1350, 2025), and Alex Wettig (@_awettig, 2026)!
They started their PhD at the beginning of the pandemic and lived through one of the most revolutionary stretches our field has ever seen. Their work has shaped how we think about language models today. So proud of them, and can't wait to see what they do next!
📰 RL for LMs often relies on imperfect proxy rewards, which can lead to reward hacking. But are incorrect rewards necessarily harmful?
Turns out, they can also be benign or even beneficial!
This has implications for reward model evaluation and verifiable reward design.
🧵
We let agents accumulate its context freely assuming little or no side-effects. This may not be the case!
Sometimes they answer political or moral questions differently and even act differently after reading or conducting research. More analysis in the thread!
We use LLMs for everyday tasks—research, writing, coding, decision-making. They remember our conversations, adapt to our needs and preferences. Naturally, we trust them more with repeated use.
But this growing trust might be masking a hidden risk: what if their beliefs are shifting and we don't notice?
We study the question "Do LM assistants change their beliefs as context accumulates?" in our new preprint: 👇
(1/n)
Tired to go back to the original papers again and again? Our monograph: a systematic and fundamental recipe you can rely on!
📘 We’re excited to release 《The Principles of Diffusion Models》— with @DrYangSong, @gimdong58085414, @mittu1204, and @StefanoErmon.
It traces the core ideas that shaped diffusion modeling and explains how today’s models work, why they work, and where they’re heading.
🧵You’ll find the link and a few highlights in the thread.
We’d love to hear your thoughts and join some discussions!
⚡ Stay tuned for our markdown version, where you can drop your comments!
We’re announcing a major advance in the study of fluid dynamics with AI 💧 in a joint paper with researchers from @BrownUniversity, @nyuniversity and @Stanford.
@DimitrisPapail Essentially an updated version of the Shakespeare-typing monkey? But now the monkey gets rewarded and learns (slowly from scratch).
Though conceptually it feels more like "inverse RL" where the reward func is simply the exact match against the expert demos and not a learned one.
Agents need a new type of learning in the era of experience (imagining 4.0). Not quite gradient descent and not exactly in-context learning. Experience never ends so you'd need metabolism. Many emerging ideas recently but none cracked it yet.
Andrej Karpathy: Software Is Changing (Again)
Key learning points from this brilliant lecture from yesterday.
🚀 The Shifting Software Map
For 70 years code flowed in one style, then neural networks arrived and rewrote large patches of logic.
Karpathy divides eras into software 1.0 for handwritten instructions, software 2.0 for trained weights, and software 3.0 for programmable large language models that obey plain-text prompts.
Each layer still matters, so future engineers must move smoothly among explicit code, dataset tuning, and prompt design.
I'm thrilled to share that I've moved to Pittsburgh and joined NeuLab at CMU as a research intern this summer, advised by @gneubig! I'll also start my PhD @LTIatCMU this fall. Feel free to reach out if you're interested in chatting about multi-agent systems, LLMs for scientific discovery, or cognitive science!
Special thanks to all the amazing people who've inspired and supported me throughout my master's journey at Princeton, especially my advisors @danqi_chen and Tom Griffiths (@cocosci_lab), and my mentor @__howardchen! I'm deeply grateful for their incredible guidance and encouragement!🐯🎓
Science is about inferring underlying rules/dynamics of a system. Can SoTA LLMs do it reliably? Despite all the progress in building AI scientists, we find it still nontrivial for models to reverse-engineer simple black-box systems. More insights/analysis in the thread!
Using LLMs to build AI scientists is all the rage now (e.g., Google’s AI co-scientist [1] and Sakana’s Fully Automated Scientist [2]), but how much do we understand about their core scientific abilities?
We know how LLMs can be vastly useful (solving complex math problems) yet unreliable (counting the number of "R"s in "strawberry" or calculating 9.9 - 9.11) at the same time. Similarly, despite recent advances in applying LLMs to science, are we confident that they can reliably uncover the underlying mechanism of a simple black-box system in a controlled setting?
We study this question in our new preprint: 📢👇
(1/n)
Rich's slogans for AI research (revised 2006):
1. Approximate the solution, not the problem (no special cases)
2. Drive from the problem
3. Take the agent’s point of view
4. Don’t ask the agent to achieve what it can’t measure
5. Don't ask the agent to know what it can't verify
6. Set measurable goals for subparts of the agent
7. Discriminative models are usually better than generative models
8. Work by orthogonal dimensions. Work issue by issue
9. Work on ideas, not software
10. Experience is the data of AI
https://t.co/UHpKNbatvZ
The success of RLHF depends heavily on the quality of the reward model (RM), but how should we measure this quality?
📰 We study what makes a good RM from an optimization perspective. Among other results, we formalize why more accurate RMs are not necessarily better teachers!
🧵
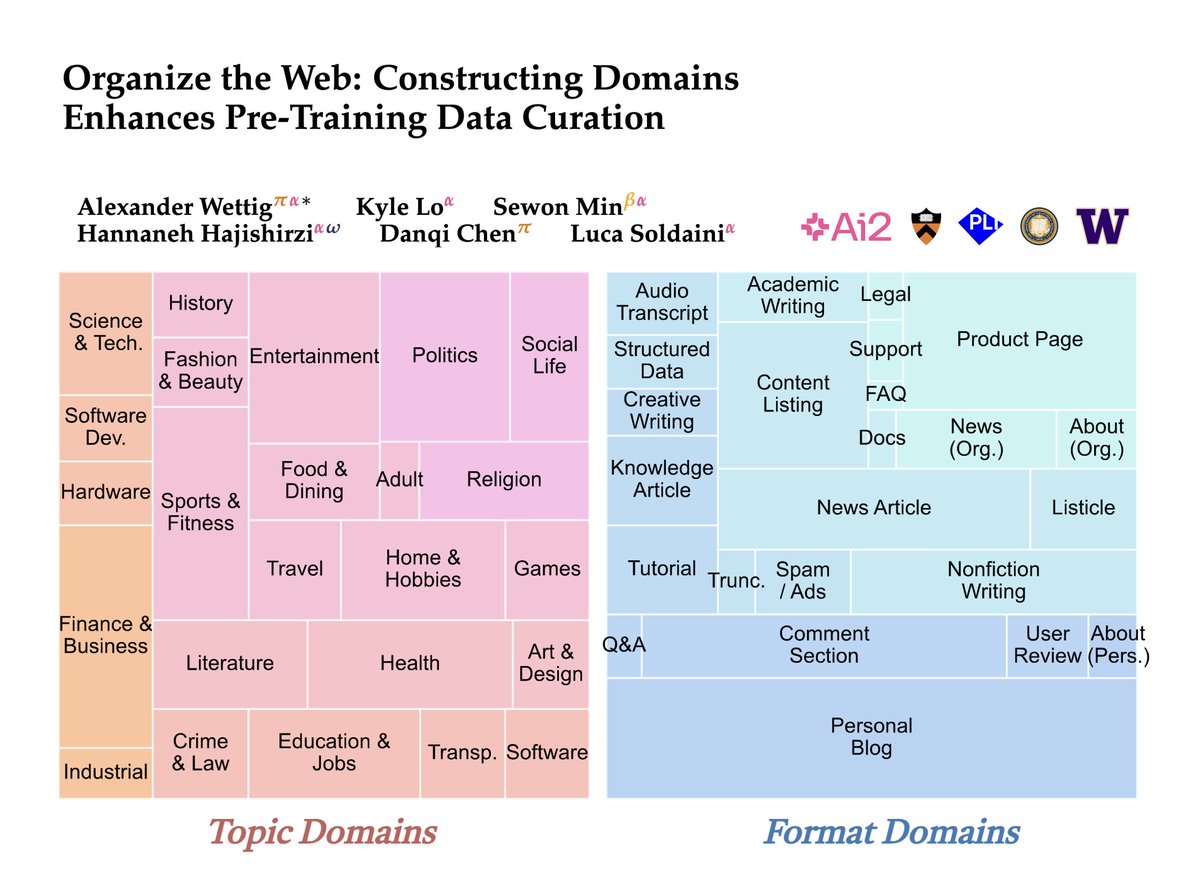
🤔 Ever wondered how prevalent some type of web content is during LM pre-training?
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N
@archit_sharma97 Not exactly though? I mean the KL is itself E_{y~\pi}[log \pi / \pi_0] so if you want to wrap the expectation outside then it should be log \pi/\pi_0 in the bracket?
The theoretical physics approach to neural nets was launched by @HopfieldJohn in this classic 1982 paper that introduced the "energy function" to associative memory models. https://t.co/HekdYdvvJc






















![JiayiiGeng's tweet photo. Using LLMs to build AI scientists is all the rage now (e.g., Google’s AI co-scientist [1] and Sakana’s Fully Automated Scientist [2]), but how much do we understand about their core scientific abilities?
We know how LLMs can be vastly useful (solving complex math problems) yet unreliable (counting the number of "R"s in "strawberry" or calculating 9.9 - 9.11) at the same time. Similarly, despite recent advances in applying LLMs to science, are we confident that they can reliably uncover the underlying mechanism of a simple black-box system in a controlled setting?
We study this question in our new preprint: 📢👇
(1/n)](https://pbs.twimg.com/media/Gr9RJv8W8AE8HWy.png)