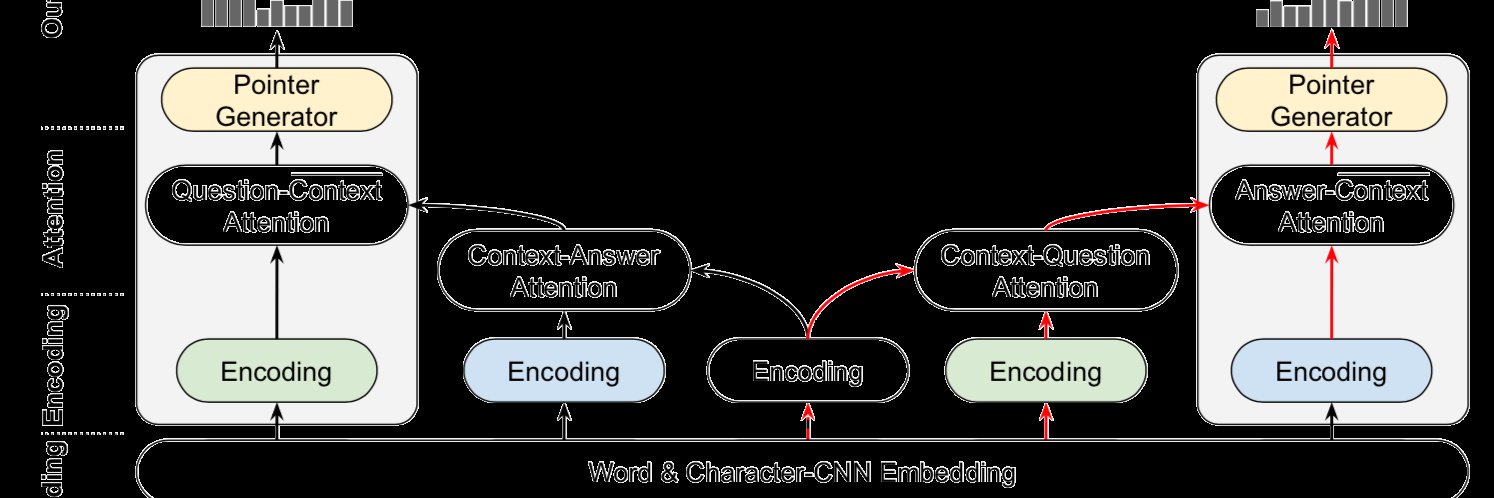
📌Our work on controllable video generation is being presented at the @CVPR 2026 AI for Creative Visual Content Workshop!
💡TLDR: ironically, minor deviations from control signals allow for better control adherence.
🧵(1/n)
#CVPR2026@cveu_workshop@RBCBorealis@UBC_CS
TRAINER SPOTLIGHT ✨✨✨ Meet Afolabi Abeeb, a seasoned Data Scientist & Machine Learning expert. His expertise in Phyton, R, and modern ML framework is helping shape the next generation of women in tech.
IndabaX Nigeria 2025 ✅
Grateful to @SummitUniOffa President of @Ansarudeenhq , our sponsors, and @DeepIndaba for powering this success. 🙌
Massive thanks to the @IndabaXNigeria LOC, participants, and the amazing staff & students of SUO. Together, we made it impactful! 🇳🇬
Hello world🔥🚀!
I am excited to announce the release of YarnGPT, YarnGPT is a family of open source text to speech models built for Nigerian🇳🇬 accented English (YarnGPT) and native languages (YarnGPT-local).
It was built on top of SmolLM2-360M by @huggingface
A thread🧵...
🎓 Excited to share my latest article on Medium! 📊 Dive into the fundamentals of Ordinary Least Squares (OLS) regression with me as we unpack its key insights and practical applications in predictive modeling.
https://t.co/cZR2ARwD71
#machine_learning#DataScientists
Twitter we up.
I’ll use the 20M to support the tech career of 166 people with 120k each. So let’s get the 5k likes.
If you’re earning less than 300k/month, and you want to transition into tech, fill this form and I’ll recommend a course for you and also assist with your school fees.
Link: https://t.co/hu64xFCHas
#MemoryMonday#NLProc
"Text Analysis in Python for Social Scientists – Discovery and Exploration" by Dirk Hovy offers basic analysis methods of natural language processing to social scientists for extracting information from abundant text.
https://t.co/x5KGIIcWes
Scikit-LLM: Sklearn Meets Large Language Models!
Seamlessly integrate powerful language models like ChatGPT into the scikit-learn ecosystem for enhanced text analysis tasks.
It aims to provide a convenient interface for leveraging LLMs in various machine learning pipelines, particularly those involving text data.
Here's what you can do with Scikit-LLM:
🔹Zero-Shot Text Classification:
It offers a `ZeroShotGPTClassifier` that allows text classification without re-training the model. The classifier works with descriptive labels.
🔸Few-Shot Text Classification
The `FewShotGPTClassifier` allows for few-shot classification, where training samples are added to the prompt and passed to the model.
🔹Dynamic Few-Shot Text Classification:
The `DynamicFewShotGPTClassifier` dynamically selects samples per class to include in the prompt, allowing the classifier to scale to larger datasets.
🔸Text Classification with Google PaLM 2:
It supports PaLM-based models like `ZeroShotPaLMClassifier`, `PaLMClassifier`, and `PaLM` for various text classification tasks.
🔹Text Vectorization:
The `GPTVectorizer` can be used for data preprocessing to embed text into fixed-dimensional vectors.
🔸LLM Fine-Tuning:
It supports fine-tuning scenarios for text classification and text-to-text tasks.
🔹Text Summarization:
The `GPTSummarizer` can be used as a stand-alone estimator or as a preprocessor for text summarization.
🔸Text Translation:
The `GPTTranslator` allows translating text into different languages.
I have linked the official GitHub repo in next tweet!
If you liked this content & are interested in:
- Python 🐍
- ML/MLOps 🛠
- CV/NLP 🗣
- LLMs 🧠
Find me → @akshay_pachaar ✔️
Everyday, I share tutorials on above topics!
Thanks for reading!🥂