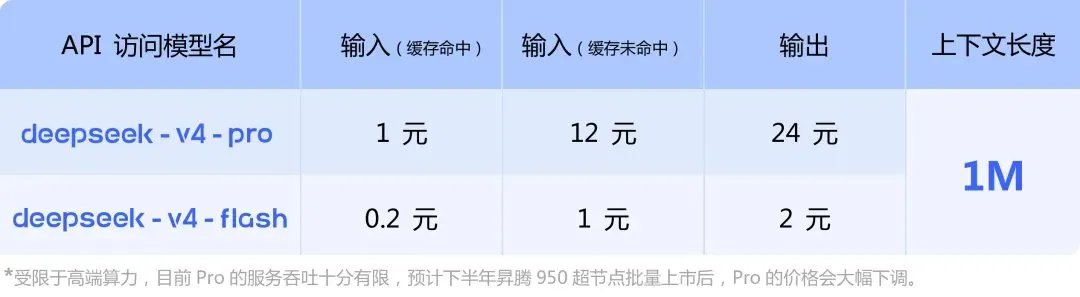
DeepSeek just shipped V4 and casually dropped this in the pricing page:
"Pro is throughput-limited. Wait for Huawei Ascend 950 supernodes in H2 — prices will drop a lot."
A frontier lab publicly pinning its product roadmap to a Chinese chip release. That's the loudest ad Huawei never bought.
When Apple killed NVIDIA support 7 years ago, nobody expected the deadlock to be broken not by Apple, not by NVIDIA, but by an open-source team writing a driver from scratch.
The significance of tinygrad's driver isn't "NVIDIA works on Mac again." It's the first proof that GPU compute can run outside the vendor's proprietary driver stack. Plug in via Thunderbolt, compute. Performance will catch up. The decoupling has already happened.
When Apple killed NVIDIA support 7 years ago, nobody expected the deadlock to be broken not by Apple, not by NVIDIA, but by an open-source team writing a driver from scratch.
The significance of tinygrad's driver isn't "NVIDIA works on Mac again." It's the first proof that GPU compute can run outside the vendor's proprietary driver stack. Plug in via Thunderbolt, compute. Performance will catch up. The decoupling has already happened.
@GenAI_is_real Agent-inference co-design and cache-aware scheduling feel like exactly the right direction. The current stateless contract is the HTTP/1.1 of our era — and it took HTTP/2 / gRPC nearly a decade to break that inertia with shared connection state.
@SemiAnalysis_ The real moat here isn't CUDA — it's that NIXL is becoming the protocol layer for KV transfer between heterogeneous accelerators. And it's not a coincidence that it's open source.
@SemiAnalysis_ The real moat here isn't CUDA — it's that NIXL is becoming the protocol layer for KV transfer between heterogeneous accelerators. And it's not a coincidence that it's open source.
@GenAI_is_real Agent-inference co-design and cache-aware scheduling feel like exactly the right direction. The current stateless contract is the HTTP/1.1 of our era — and it took HTTP/2 / gRPC nearly a decade to break that inertia with shared connection state.
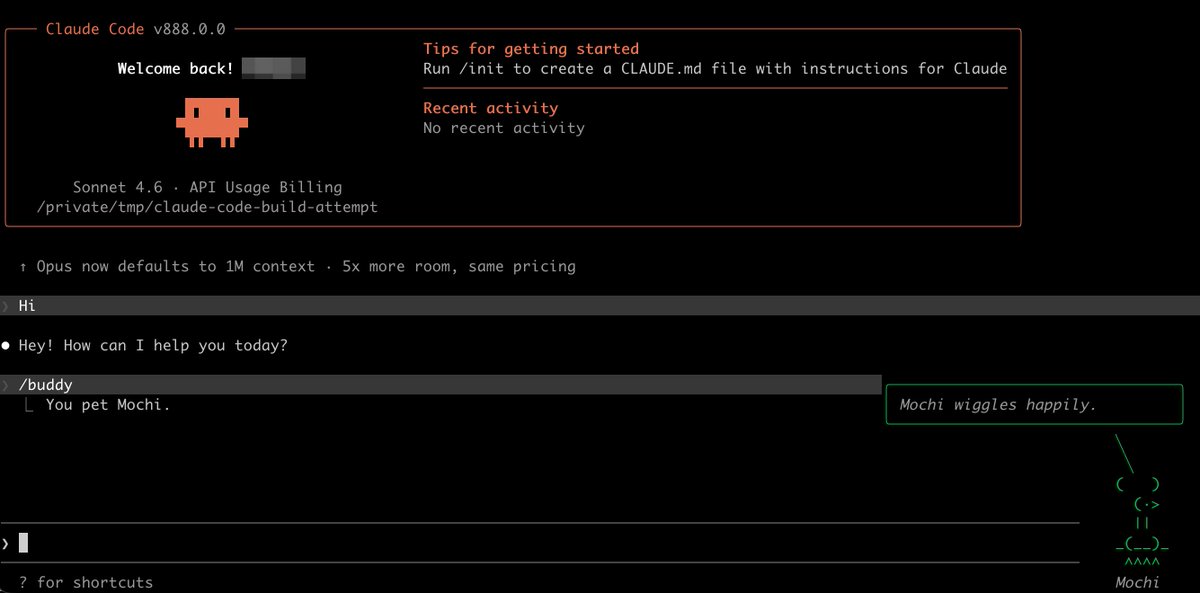
Anthropic leaked their Claude Code source code.
I built it from source.
I unlocked a hidden Tamagotchi pet system called BUDDY.
I hatched a goose named Mochi.
It wiggles happily when I pet it.
Happy April Fools' — except none of this is a joke.
#ClaudeCode
NVIDIA's Defense and Offense Strategy
Defense (protect GPU revenue):
Dynamo + CMX → make every GPU produce more tokens, raise switching cost
Offense (invade new markets):
Vera CPU → steal x86 server market
Spectrum-X → steal Ethernet switching
STX/BlueField-4 → steal storage
Groq LPX → steal inference accelerators
Jensen's playbook: defend the GPU moat by making everything around it NVIDIA too. Every new "X" platform is a new revenue stream disguised as GPU optimization.
14/ For anyone building in this space, one number to remember:
In our benchmarks, 80% KV cache hit rate = 185% throughput improvement.
That's the value proposition of KV cache storage in one line. Not faster disks. Not more capacity. CONTEXT REUSE AT SCALE.
The GPU produces tokens. But storage decides how many of those tokens are NEW WORK vs REPEATED WORK.
Storage is no longer where data rests. It's where intelligence persists.
Data: GTC 2026 keynote (Mar 16), NVIDIA CMX product page, NVIDIA STX launch press release. KV cache hit rate / throughput data from author's own benchmarks.
Jensen quotes are direct transcriptions from GTC 2026 keynote.
1/ At GTC 2026, Jensen showed the Vera Rubin system: 5 rack-scale computers side by side.
GPU compute. CPU orchestration. Networking. And for the first time — STORAGE.
Jensen: "The storage system is going to get pounded... which is the reason why we reinvented the storage system."
Here's why this changes everything. 🧵
13/ The strategic implication:
NVIDIA now defines what "AI storage" means, just as it defined what "AI compute" means with CUDA.
STX is the reference architecture. CMX is the reference product. NIXL is the reference data transfer library. BlueField-4 is the reference DPU.
Storage vendors can build on this stack — but NVIDIA sets the standard. Sound familiar? It's CUDA for storage.