HARPO (AKA Carlos A. Catania). A Nerdo with decent social skills? #DataScience#Algorithms. English, Spanish and Français. From Mendoza Republic. South America
Since Mixture of Expert (MoE) LLMs are all the rage as of this weekend, thanks to the Mixtral-8x-7B release, here's a quick explainer. The figure below shows the architecture behind the Switch Transformer (https://t.co/6jowgQx0DV), a great intro to MoEs.
The model depicted in this figure uses 1 expert per token with 4 experts in total. Mixtral-8x-7B, on the other hand, consists of 8 experts and uses 2 experts per token.
Why MoEs? Combined, the 8 experts in a 7B model like Mixtral are still ~56B parameters. (Actually, it's less than 56B, because the MoE approach is only applied to the MoE layers, not the self-attention weight matrices. So, it's likely closer to 40-50B parameters.)
However, since the router reroutes the tokens such that only 7B parameters (instead of all 56B) are used at a time for the forward pass, the training (and especially inference) will be much faster compared to the traditional non-MoE approach.
If you read my AI and Open Source in 2023 article (https://t.co/C8SGseRHNZ) approx. 2 months ago, I mentioned that "It will be interesting to see if MoE approaches can lift open-source models to new heights in 2024". It looks like Mixtral started this trend early, and I am sure that this is just the beginning :).
🚨New Paper Alert! In our latest research we used LLMs as reinforcement learning red team agents: "Out of the Cage: How Stochastic Parrots Win in Cyber Security Environments" https://t.co/LmMHoUlHYh with @ondrej_lukas@harpolabs@eldraco#AI#LLM#ML#infosec
It’s time to admit that we were all overly optimistic during COVID, thinking that organizations will finally understand the “remote work” culture. Not only is back to office, but also back to paper and physical meets. We thought we could make a change and we lost. #fail
Desde el nuevo Media Lab de la @UNCUYO acabamos de lanzar un podcast dedicado a la inteligencia artificial. Se llama "Inteligencia natural" y acá están los primeros 3 episodios. https://t.co/0HAtJ6CcHV
Join us in Las Vegas for our @BlackHatEvents
hands-on Advanced Malware Traffic Analysis training with @verovaleros! Learn how to detect botnets, ransomware, lateral movement, and more! Learn to detect attacks w/machine learning tools! #BlackHat#BHUSA https://t.co/LmYEnqG9Dz
Our paper w/@MasarahClouston "On the dynamics behind profit-driven cybercrime from contextual factors to perceived group structures, and the workforce at the periphery" was finally published! I'm so proud and happy for this collaboration! #cybercrime https://t.co/oWrgygd6Ky
Let's gooo! 🔥
We're happy to introduce two new official Space Templates in collaboration with @posit_pbc: Build and share your R and Python Shiny apps directly on the Hub! 🥳
I believe we need open-source alternatives to ChatGPT for more transparency, inclusivity, accountability and distribution of power.
Excited to introduce HuggingChat, an open-source early prototype interface, powered by OpenAssistant, a model that was released a few weeks ago.
¡El #SAHTI2023 de las #52JAIIO@jaiio_oficial se prepara!
@bmassare desde CABA, Karina Bianculli desde MdP y yo desde Cba, armando un Simposio de Historias, Tecnología e Informática que va a estar muy bueno.
¡Hasta el 1 de mayo tenés tiempo de presentar el resúmen!
Te esperamos.
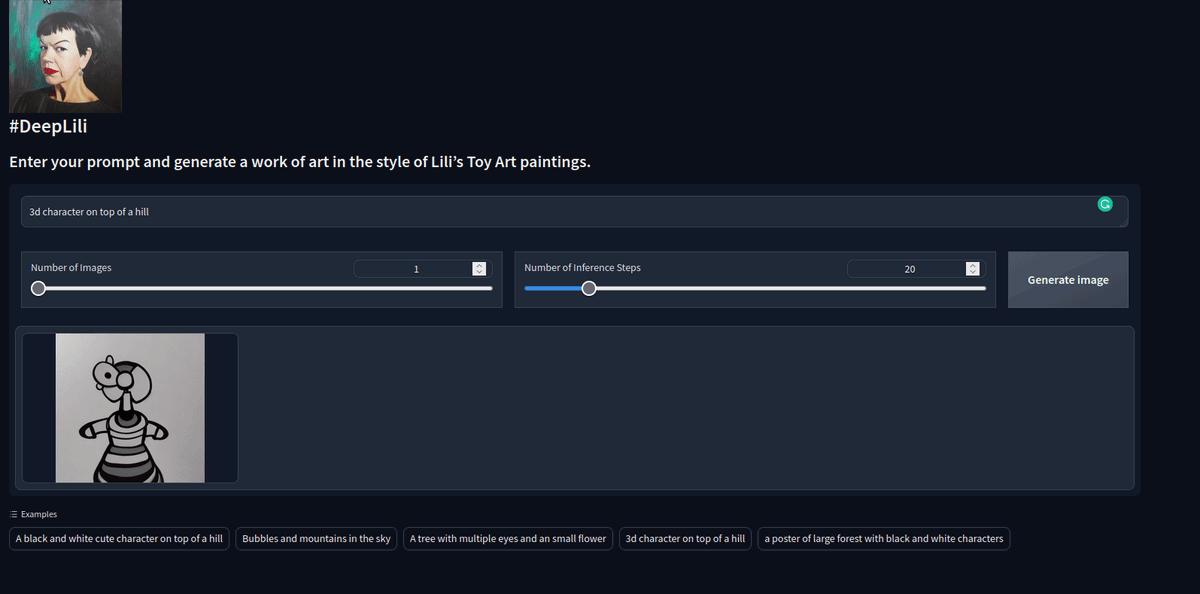
Another collaboration with visual artist Lili Fiallo. Using #dreambooth we fine tuned #stablediffusion to incorporate Lili's toy art style. incredibly simple using diffusers and gradio libraries.
https://t.co/7TK1n6tTDj
https://t.co/1TXvs5iQop