Top Tweets for #30DaysOfMachineLearning

Day 6 of #30DaysOfMachineLearning 🔥
• CNNs + Conv layers
• Built image classifier w/ augmentations
• Training loop & evaluation
Getting hands-on with vision models that actually see
🔗 https://t.co/THiV0s6cVo
#PyTorch #DeepLearning #LearnInPublic @OpenAI @GoogleDeepMind
Day 5 of #30DaysOfMachineLearning 🔥
• Revisited vanishing/exploding gradients
• Compared ReLU vs. ELU activation
• Explored batch normalization
Building deeper, more stable networks step by step
🔗 https://t.co/THiV0s6KKW
#PyTorch #DeepLearning #LearnInPublic @OpenAI @Google
Day 4 of #30DaysOfMachineLearning 🚀
• OOP PyTorch: Dataset, DataLoader, Model
• Optimizers + Training Loop
• Model evaluation metrics
Gaining confidence in building robust deep learning
🔗 https://t.co/THiV0s6cVo
#PyTorch #DeepLearning @OpenAI @huggingface #LearnInPublic
Day 3 of #30DaysOfMachineLearning
• Evaluation loop
• Accuracy with torchmetrics
• Dropout & overfitting insights
• Fine-tuning + layer freezing
• Random search for performance boost Exploring the art of smarter training!
🔗 https://t.co/THiV0s6KKW #PyTorch #DeepLearning

Starting a #30DaysOfMachineLearning challenge today 💪
Here's a Kaggle notebook I threw together with the Fast AI library ->
https://t.co/wF4j9VSGp8

Kernel bandwidth in Kernel Density Estimation - balancing detail and smoothness.
Smaller bandwidth - more variability but may overfit
Larger one - smoother estimates but can oversmooth.
🔧Cross-validation & Silverman's rule aid bias-variance trade-off.
#30daysofMachineLearning
Nonparametric Density Estimation - a powerful statistical tool for estimating probability density functions without assuming specific distributions.
Kernel Density Estimation, Histogram methods help unveil complex data patterns (informed decision-making). #30daysofMachineLearning
📈Evaluating grouping of data points within clusters & separated across clusters is key in assessing clustering quality.
Fowlkes-Mallows index, quantify effectiveness of clustering by examining relationships in data points based on clustering assignments.
#30daysofMachineLearning
📊Pairwise measures in clustering evaluation analyze similarity of cluster assignments by comparing pairs of data points within and across clusters.
Metrics, Jaccard coeff. & Rand index, offer insights between clustering outcomes & ground truth labels. #30daysofMachineLearning
Mutual Information in clustering evaluation assesses the dependency between observed and expected joint probabilities of clusters and ground truth.
#ClusteringEvaluation #30daysofMachineLearning
📊 Conditional Entropy in clustering evaluation measures the cluster-specific entropy, revealing how ground truth is distributed within each cluster. #ClusteringEvaluation #DataAnalysis #30daysofMachineLearning
📊 Maximum Matching in clustering evaluation ensures one cluster is matched to one partition, maximizing purity under the one-to-one matching constraint.
It is essential for assessing clustering performance effectively. #ClusteringEvaluation #30daysofMachineLearning
📊 Purity in clustering quantifies the extent to which a cluster contains points exclusively from one ground truth partition. It is a crucial measure for evaluating the quality of clustering results accurately. #ClusteringEvaluation #DataAnalysis #30daysofMachineLearning
🤖 Exploring clustering evaluation in #30daysofMachineLearning!
Did you know there are two main categories of measures?
External measures rely on external ground-truth, while internal measures derive goodness from the data itself. 💡
The Davies-Bouldin Index is critical in cluster evaluation, it captures trade-off between cluster compactness & separation.
A lower index value : more cohesive and well-separated clusters, showcasing its significance in optimizing clustering algorithms. #30daysofMachineLearning
Epsilon (eps) plays a pivotal role in density-based clustering, the Elbow effect shedding light on its impact.
🔧 Manipulating epsilon values, we can observe clusters merging or outliers emerging, offering valuable insights into data patterns.
#30daysofMachineLearning
A cluster in density-based clustering revolves around density-connected points forming dense regions.
Identifying maximal sets of points with density-reachable relationships, we pinpoint clusters amidst varying densities -> precise clustering analysis. #30daysofMachineLearning
Direct density reachability in DBSCAN highlights the direct connection between core objects, essential for clustering and outlier detection.
The path of direct density reachability, unveils intricate relationships within dense regions in the data space. #30daysofMachineLearning
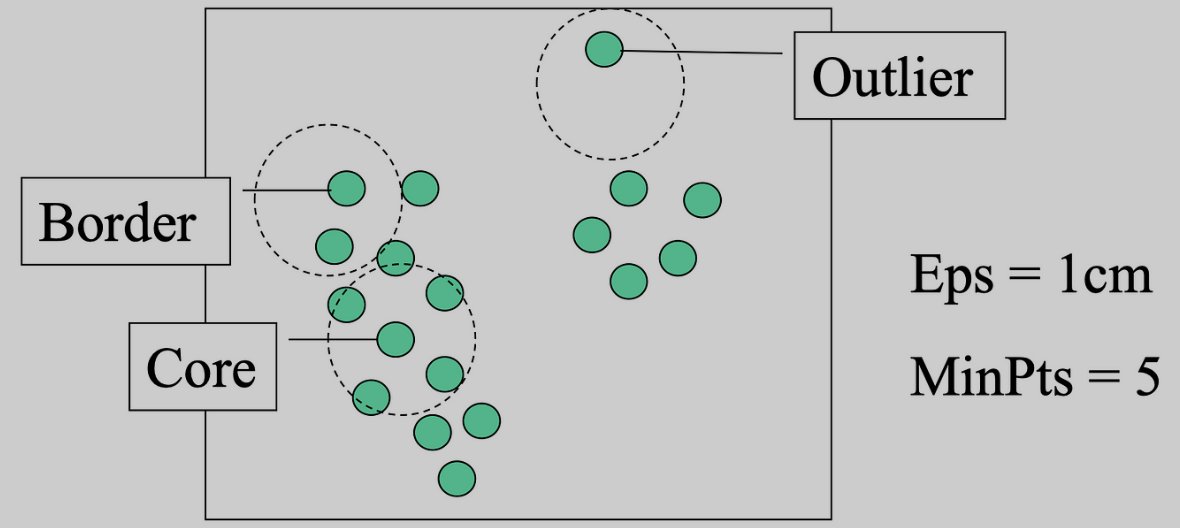
Epsilon and minPts are the dynamic duo in density-based clustering algorithms like DBSCAN.
🪩Epsilon controls the reachability distance,
🪩minPts determines the density threshold for defining clusters.
These parameters enable accurate clustering. #30daysofMachineLearning
Understanding core points, border points, and outliers is crucial in density-based clustering like DBSCAN. Core points form the heart of clusters, while border points lie on the edges, and outliers stand alone.
#30daysofMachineLearning
Trends for you
Most Popular Users

Elon Musk 
@elonmusk
240.1M followers

Barack Obama
@barackobama
119.3M followers

Donald J. Trump
@realdonaldtrump
111.6M followers

Cristiano Ronaldo
@cristiano
108.8M followers

Narendra Modi
@narendramodi
107M followers

Rihanna
@rihanna
97.2M followers

NASA
@nasa
92.1M followers

Justin Bieber
@justinbieber
90.5M followers

KATY PERRY
@katyperry
86.7M followers

Taylor Swift
@taylorswift13
80.5M followers

Lady Gaga
@ladygaga
72.1M followers

Kim Kardashian
@kimkardashian
69.4M followers

YouTube
@youtube
68.6M followers

Virat Kohli
@imvkohli
68.5M followers

Bill Gates
@billgates
63.4M followers

The Ellen Show
@theellenshow
62.5M followers

CNN
@cnn
61.9M followers

Neymar Jr
@neymarjr
61M followers

X
@x
60.9M followers

CNN Breaking News
@cnnbrk
59.9M followers