Top Tweets for #MathVISTA

lol at everyone shilling AGI bags when GPT still gets rugged by geometry homework, wake me up when it can run a backtest in Excel without hallucinating commas #MathVISTA
$VioletAI #Solana #Memecoin


🚀 o1 is now released by @OpenAI! It's trained to think slowly with a long chain of thought. It works impressively and may unlock hard tasks in science and math, setting a new SOTA with 73.2% on #MathVista!
Leaderboard: https://t.co/odcmmezNth
Blog: https://t.co/bfjHTNCsbX


We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond.
These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math. https://t.co/peKzzKX1bu

Dijelaskan bahwa Grok-2 dan Grok-2 mini sekarang langsung memegang dua tempat teratas di #MathVista melalui situs web (https://t.co/clPFIXfbpK)!
Apa yang ingin disampaikan adalah tentang mengesankannya dorongan cepat oleh team xAI, meningkatkan skor seri Grok dari 52,8% menjadi 69% hanya dalam waktu 4 bulan saja.🥶
🚀 Ini benar-benar terkesan dengan kemajuan yang luar biasa dari @xai Respect.
—NOTE
Sentimen ini tercermin dalam beberapa posting dari pengguna yang berbeda, menunjukkan penerimaan umum atas pencapaian ini dalam komunitas yang membahas AI dan pembelajaran mesin di platform.
Namun, sementara posting ini menyarankan tingkat kinerja yang tinggi untuk Grok-2 dan Grok-2 mini dalam tugas matematika dan visual sebagai tolok ukur oleh MathVista.
#XAI #MathAI #GenAI #ElonMusk #GROK2


@lupantech @xai Absolutely amazing progress from @xai! The Grok series' rapid rise to the top of the #MathVista leaderboard is truly impressive. Kudos to the team for their hard work and dedication.
🚀 Truly impressed by the remarkable progress from @xai! Grok-2 and Grok-2 mini now hold the top two spots on #MathVista (https://t.co/odcmmezNth)!
Even more impressive is the rapid boost by @xai, raising the Grok series' scores from 52.8% to 69% in just 4 months. Respect! 👏
#XAI #MathAI #GenAI #ElonMusk

🚀 Excited to see Claude 3.5 Sonnet by @AnthropicAI achieve a new SOTA on #MathVista with 67.7%, a 19.8% improvement over Claude 3 Sonnet! 📈🎉
Learn more:
📝 Blog: https://t.co/rXjPn6d77t
🔢 MathVista: https://t.co/kf2dU6ATDn



Introducing Claude 3.5 Sonnet—our most intelligent model yet.
This is the first release in our 3.5 model family.
Sonnet now outperforms competitor models on key evaluations, at twice the speed of Claude 3 Opus and one-fifth the cost.
Try it for free: https://t.co/uLbS2JMEK9

🧵 3/N We conducted extensive experiments on 7 vision-language benchmarks, including #ScienceQA, #TextVQA, #ChartQA, LLaVA-Bench, #MMBench, MM-Vet, and #MathVista.
STIC achieves consistent and significant performance improvements, with an average accuracy gain of 4.0% over the base LVLM and a notable gain of 6.4% on ScienceQA.


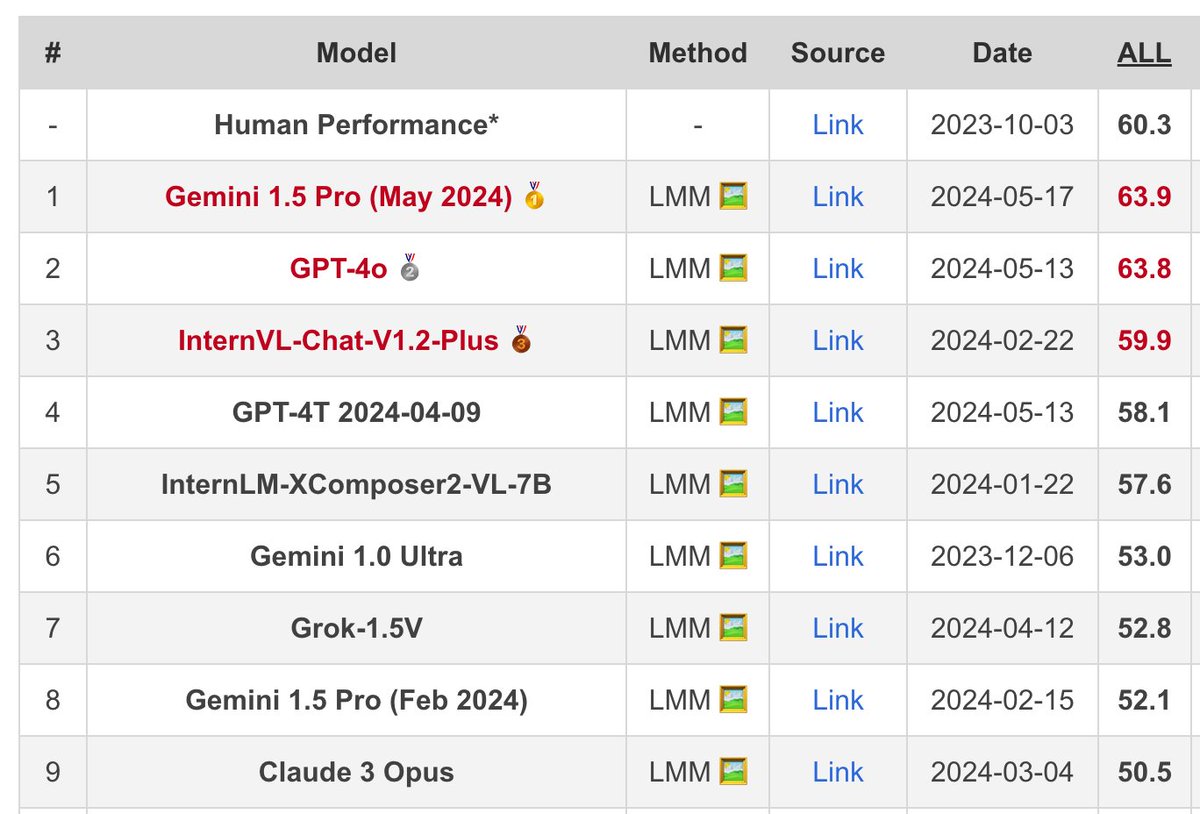
Congrats, @JeffDean @GoogleDeepMind! Gemini 1.5 Pro has shown substantial improvements from Feb to May, scoring 63.9% on our #MathVista (https://t.co/kf2dU6ATDn), outperforming humans and GPT-4o, which was out 4 days ago!🚀
AI Progress has never been this rapid and impressive!🌟

Gemini 1.5 Model Family: Technical Report updates now published
In the report we present the latest models of the Gemini family – Gemini 1.5 Pro and Gemini 1.5 Flash, two highly compute-efficient multimodal models capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio.
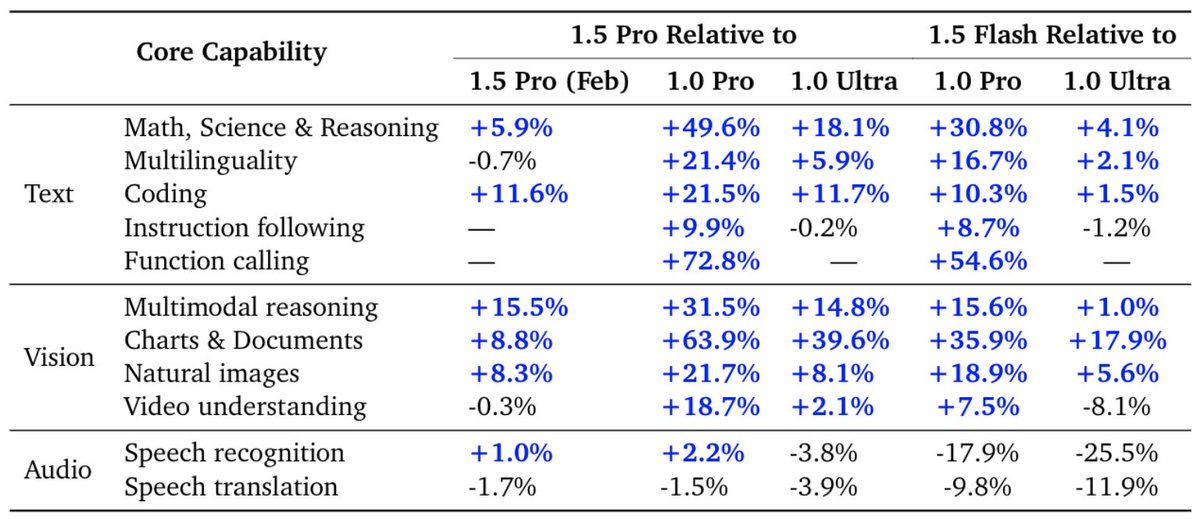
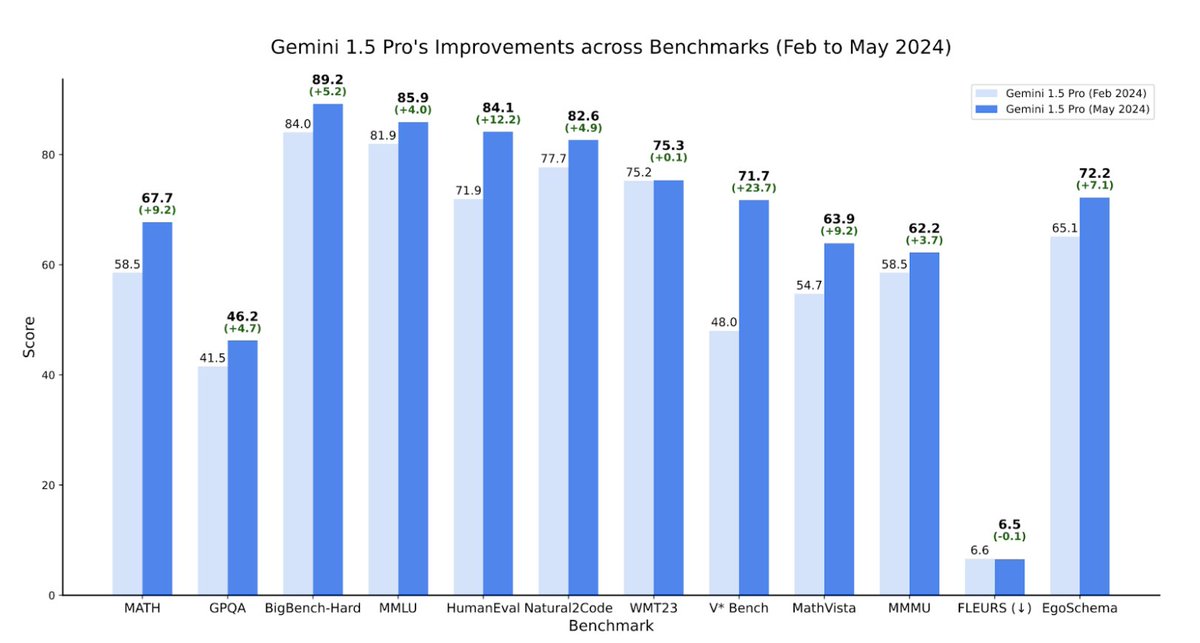
Our latest report details notable improvements in Gemini 1.5 Pro within the last four months.
Our May release demonstrates significant improvement in math, coding, and multimodal benchmarks compared to our initial release in February.
Furthermore, the 1.5 Pro Model is now stronger than 1.0 Ultra.
The latest Gemini 1.5 Pro is now our most capable model for text and vision understanding tasks, surpassing 1.0 Ultra on 16 of 19 text benchmarks and 18 of 21 of the vision understanding benchmarks. The table below highlights the improvement in average benchmark performance for different categories in 1.5 Pro since Feb, and also shows the strength of the model relative to the 1.0 Pro and 1.0 Ultra models. The 1.5 Flash model also compares very well against the 1.0 Pro and 1.0 Ultra models.
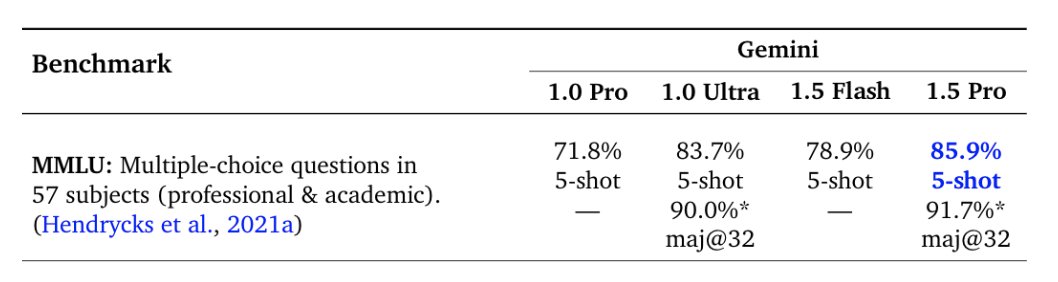
One clear example of this can be seen on MMLU
On MMLU we find that 1.5 Pro surpasses 1.0 Ultra in the regular 5-shot setting scoring 85.9% versus 83.7%. However with additional inference compute, via majority voting on top of multiple language model samples, we can get a performance of 91.7% versus Ultra’s 90.0%, which extends the known performance ceiling of this task.
@OriolVinyalsML and I are very proud of the whole Gemini team, and it’s fantastic to see this progress and to share these highlights from our Gemini Model Family.
Read the updated report here: https://t.co/CTzTHND4nQ

A fitting wrap-up to my @iclr_conf ✨
@OpenAI GPT-4o benchmarked and made significant advancements on our #MathVista dataset, achieving a whopping score of 63.8%!
@lupantech @kaiwei_chang @uclanlp
https://t.co/B1lJQPnH3L
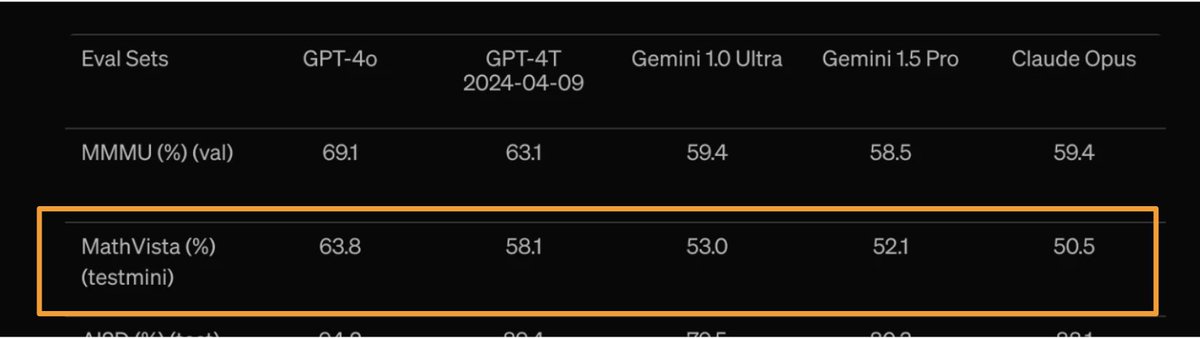
Today, we presented our #MathVista (https://t.co/kf2dU6ATDn) at #ICLR2024 in Vienna! 🌟
We are thrilled by the tremendous progress in math reasoning in the era of LLMs and VLMs. MathVista has become one of the most reliable benchmarks for probing their abilities in visual math reasoning. 📊🧠 With 10K downloads in the last month and features in LLaVA, Gemini, Claude 3, MM1, Grok-1.5V, etc., it's making waves! 🚀
Thanks to Hritik @hbXNov for the engaging talk. 👏
This massive, collaborative effort wouldn't be possible without the invaluable contributions from @uclanlp, @uwnlp, and @MSFTResearch: @hbXNov, Tony Xia, @liujc1998, @ChunyuanLi, @HannaHajishirzi, @kelvinih, @kaiwei_chang, Michel Galley, and @JianfengGao021. 🙌🎉

Today, we presented our #MathVista (https://t.co/kf2dU6ATDn) at #ICLR2024 in Vienna! 🌟
We are thrilled by the tremendous progress in math reasoning in the era of LLMs and VLMs. MathVista has become one of the most reliable benchmarks for probing their abilities in visual math reasoning. 📊🧠 With 10K downloads in the last month and features in LLaVA, Gemini, Claude 3, MM1, Grok-1.5V, etc., it's making waves! 🚀
Thanks to Hritik @hbXNov for the engaging talk. 👏
This massive, collaborative effort wouldn't be possible without the invaluable contributions from @uclanlp, @uwnlp, and @MSFTResearch: @hbXNov, Tony Xia, @liujc1998, @ChunyuanLi, @HannaHajishirzi, @kelvinih, @kaiwei_chang, Michel Galley, and @JianfengGao021. 🙌🎉
🚀Excited to release our 112-page study on math reasoning in visual contexts via #MathVista. For the first time, we provide both quantitative and qualitative evaluations of #GPT4V, #Bard, & 10 other models.
📄✨Full paper: https://t.co/O0pT4pmn12
🔗Proj: https://t.co/kf2dU6ATDn
🔍 Key Insights:
1️�� #GPT4V achieves a 49.9% accuracy, notably surpassing #Bard by 15.1%. However, it's still 10.4% behind human performance.
2️⃣ #GPT4V exhibits an emergent ability of self-verification, enabling it to autonomously check and refine its outcomes in a single inference – a feature absent in other models.
3️⃣ #GPT4V highlights its potential through self-consistency and multi-turn human-AI dialogues.
📜 Arxiv: https://t.co/yikZNtGqMr (updated soon)
🛠️ Code: https://t.co/uXzDybmxgU
📊 @huggingface Data: https://t.co/99qRsen5kJ
🔍 Visualization: https://t.co/dkbrICA2CX
🏆 Leaderboard: https://t.co/odcmmezNth
A massive shoutout to our outstanding team from @uclanlp, @uwnlp, and @MSFTResearch:
@hbXNov, Tony Xia, @liujc1998, @ChunyuanLi, @HannaHajishirzi, @kelvinih, @kaiwei_chang, Michel Galley, and @JianfengGao0217 🧵1/N

I will present #MathVista on Tuesday, Oral1C, Halle A2, 10:15am-10:30am local time.
I will also present the poster in Halle B#6 from 10:45am to 12:45pm local time.
🚀Excited to release our 112-page study on math reasoning in visual contexts via #MathVista. For the first time, we provide both quantitative and qualitative evaluations of #GPT4V, #Bard, & 10 other models.
📄✨Full paper: https://t.co/O0pT4pmn12
🔗Proj: https://t.co/kf2dU6ATDn
🔍 Key Insights:
1️�� #GPT4V achieves a 49.9% accuracy, notably surpassing #Bard by 15.1%. However, it's still 10.4% behind human performance.
2️⃣ #GPT4V exhibits an emergent ability of self-verification, enabling it to autonomously check and refine its outcomes in a single inference – a feature absent in other models.
3️⃣ #GPT4V highlights its potential through self-consistency and multi-turn human-AI dialogues.
📜 Arxiv: https://t.co/yikZNtGqMr (updated soon)
🛠️ Code: https://t.co/uXzDybmxgU
📊 @huggingface Data: https://t.co/99qRsen5kJ
🔍 Visualization: https://t.co/dkbrICA2CX
🏆 Leaderboard: https://t.co/odcmmezNth
A massive shoutout to our outstanding team from @uclanlp, @uwnlp, and @MSFTResearch:
@hbXNov, Tony Xia, @liujc1998, @ChunyuanLi, @HannaHajishirzi, @kelvinih, @kaiwei_chang, Michel Galley, and @JianfengGao0217 🧵1/N
🎉 Exciting news! Our #MathVista is excelling with the latest advances in vision-language models (VLMs). Grok-1.5V by @xai achieves a 52.8% score, surpassing leading models such as GPT-4V, Claude 3 Opus, and Gemini Pro 1.5!
🔗 Visit our project page: https://t.co/kf2dU6ATDn
👀 Explore our dataset on @huggingface: https://t.co/99qRsen5kJ
📝 Read more insights in our arxiv paper: https://t.co/yikZNtGqMr


👀
https://t.co/etua7Jqih8
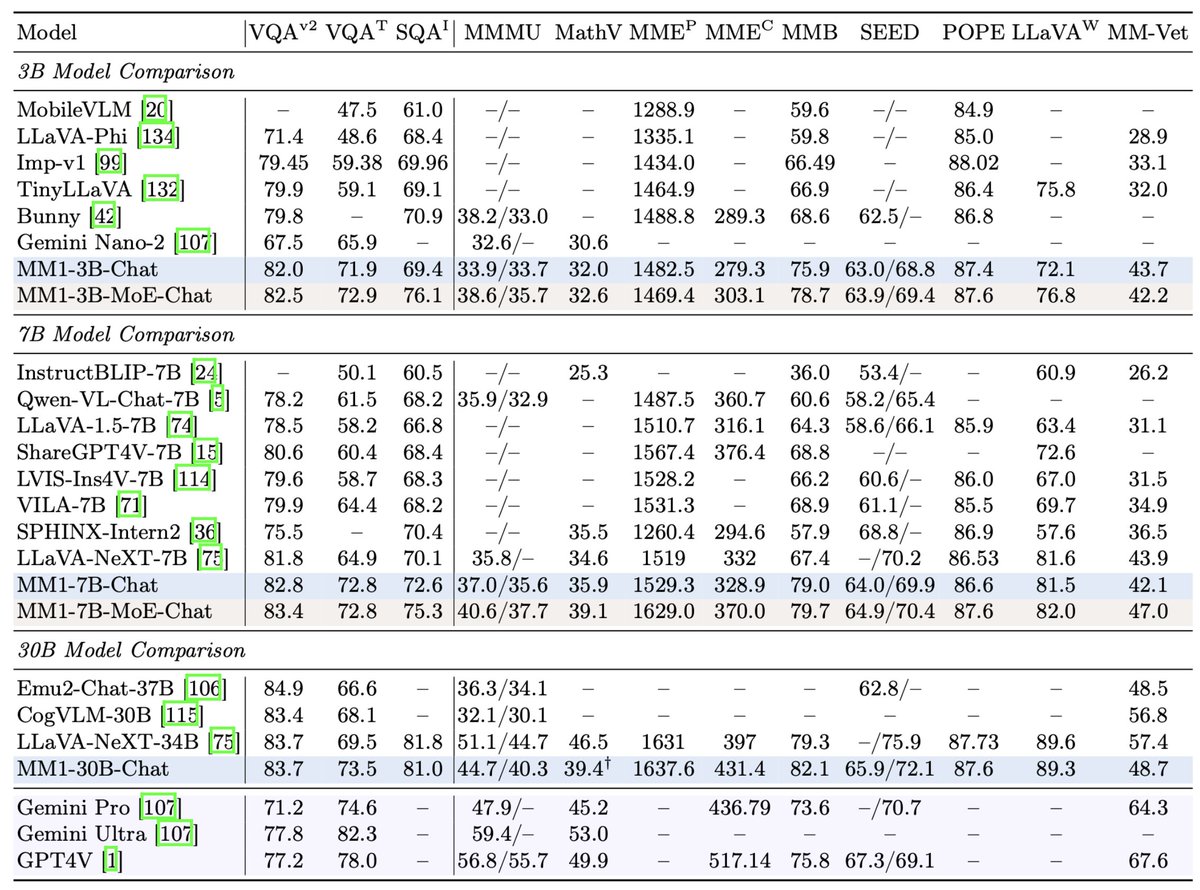
Excited to see the breakthrough achieved by @Apple's MM1 model, as evidenced by our #MathVista (https://t.co/oZsHNVrSTc), the comprehensive benchmark for math reasoning in visual contexts!

Few-shot mixed-resolution CoT: we can keep the strong few-shot capabilities learned from multimodal pre-training even after instruction-tuning: MM1-30B-Chat achieves 39.4 zero-shot on MathVista, but with eight-shot CoT mixed-resolution prompting we can achieve 44.4.
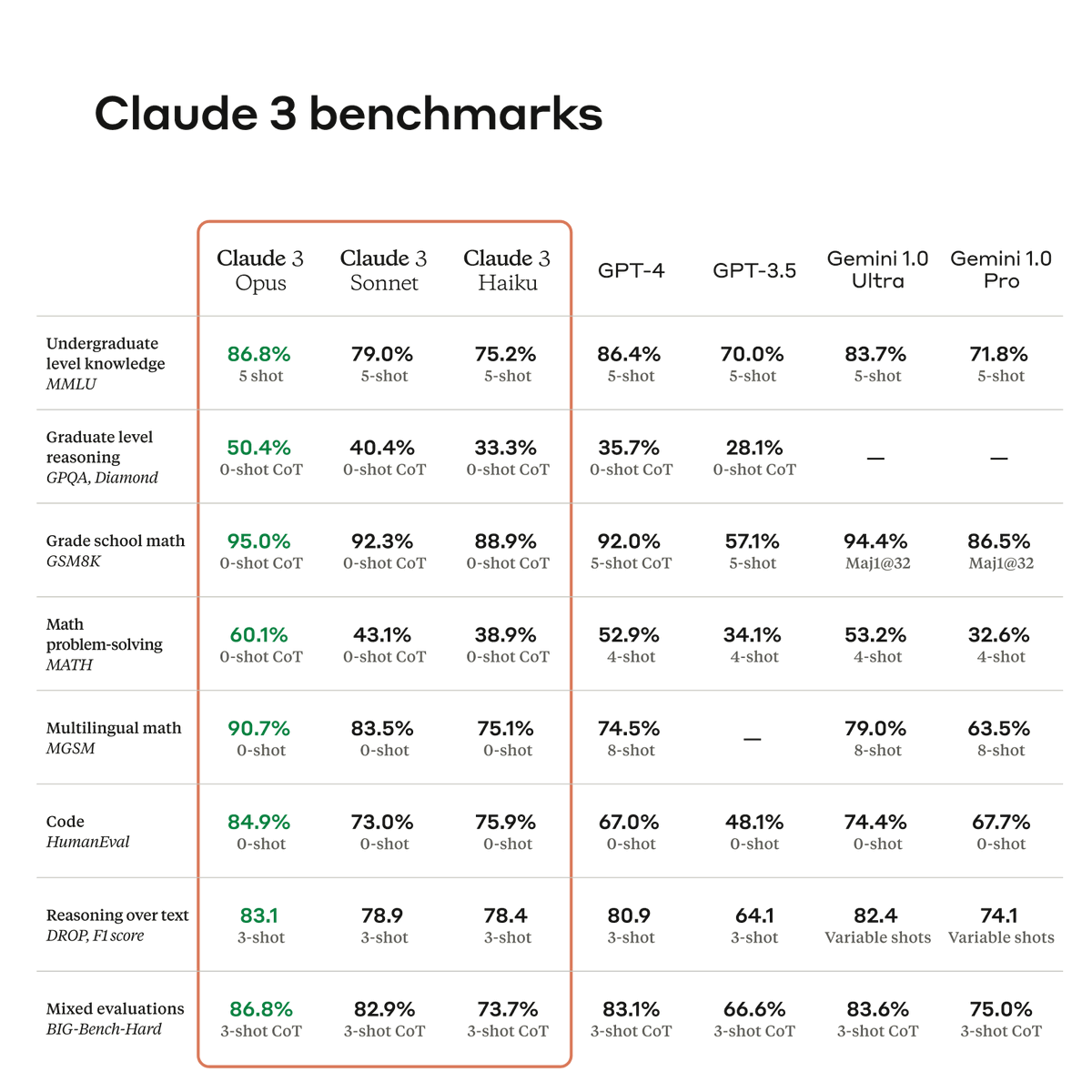
🤯So thrilled to have @AnthropicAI benchmark their latest, powerful Claude 3 models on our #MathVista for visual math reasoning!
It's encouraging to see the rapid progress in (multimodal) LLMs, especially in the math and science fields! 💥
🤗 Our @huggingface Data: https://t.co/99qRsen5kJ
🔗 Project: https://t.co/kf2dU6ATDn
��� Claude 3 blog: https://t.co/LhZoQhWCPb
🔍 Claude 3 report: https://t.co/Nh2IMcpczF

Today, we're announcing Claude 3, our next generation of AI models.
The three state-of-the-art models—Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku—set new industry benchmarks across reasoning, math, coding, multilingual understanding, and vision.

#Researchers from @UCLA, University of Washington @UW , & @Microsoft Introduce #MathVista: Evaluating Math Reasoning in Visual Contexts with #GPT4v, #BARD, and Other #LargeMultimodalModels
#LargeLanguageModel #LLMs #ArtificialIntelligence #AI
https://t.co/kvoEA99d7m


@lupantech @_akhaliq @huggingface Congratulations to Pan Lu and the team on getting MathVista presented at ICLR 2024! The blend of math and visual reasoning is a true innovation. Eager to see how this propels the field forward. 🚀 #ICLR2024 #MathVista #AIResearch #Innovation #TechCommunity
💥💥Update Alert! Radar graphs & leaderboard on #MathVista now feature detailed scores for the #Gemini family models. 🚀
🔍 Insight: Gemini Ultra leads the pack, outperforming GPT-4V by 3.1%! Yet, each model shines uniquely in various math reasoning & visual contexts.
🙏 Big thanks to @GoogleDeepMind's Gemini Team for these insights. Excited for future collaborations within the AI community!
Explore more:
🔗 Leaderboard: https://t.co/kf2dU6ATDn
👨💻 Github: https://t.co/uXzDybmxgU

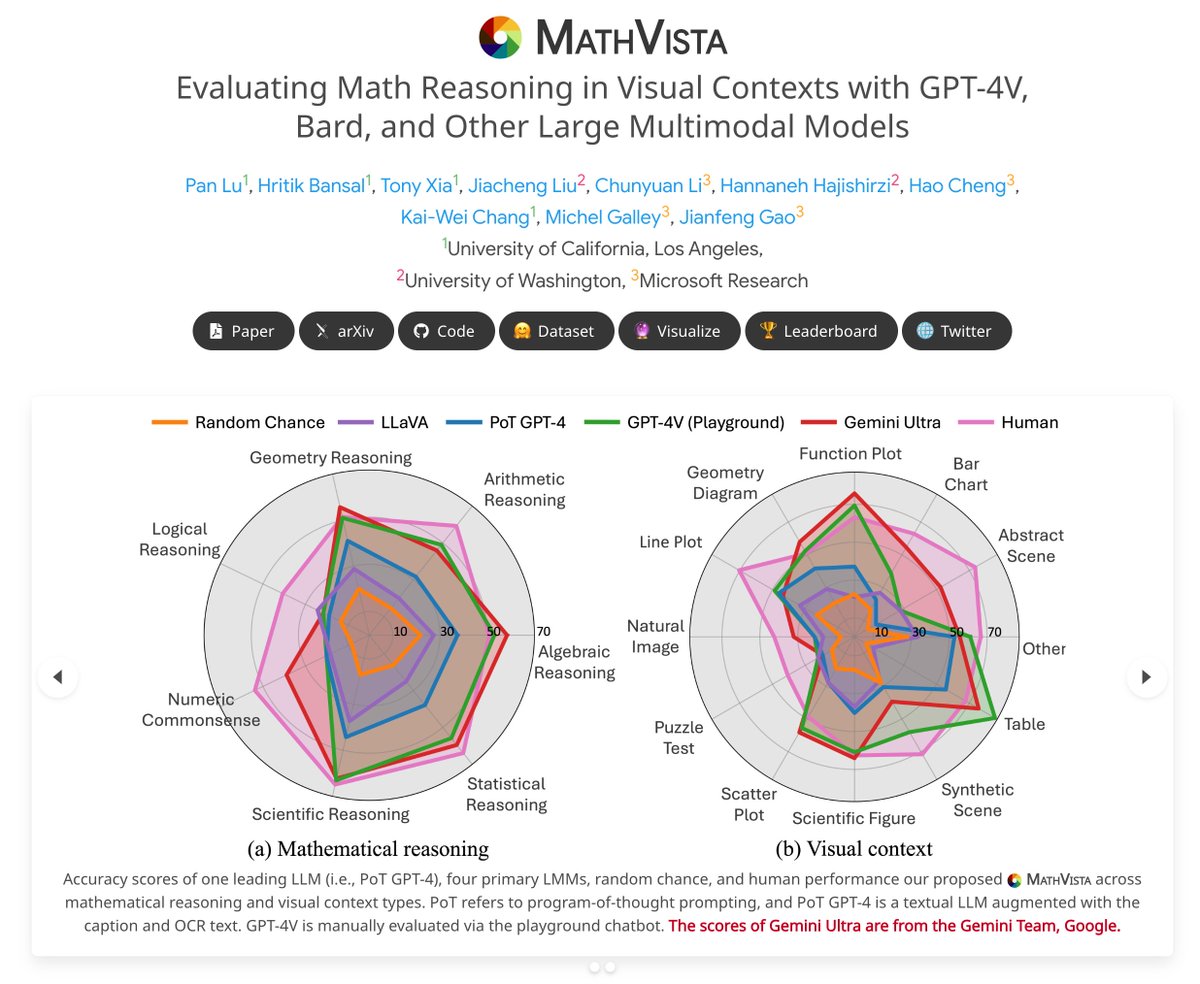
It is remarkable that Gemini achieves a new SOTA of 53.0% on MathVista (https://t.co/oZsHNVrSTc), a challenging benchmark for math reasoning in visual contexts. We are honored that our proposed #MathVista is advancing the development of the newest and most capable AI models.
In image understanding, Gemini performs well across all the benchmarks we examined, with the Ultra model setting new state-of-the-art results in every benchmark.

🚀 @google is introducing new updates to aid in learning math and science, especially in visual contexts: https://t.co/qrBsiXy0v8.
💥 We're proud to spotlight our commitment to math and science over the past years, with projects like #MathVista, #Chameleon, and #ScienceQA.
1️⃣ MathVista: A 112-page study of evaluating math reasoning in visual contexts, with 12 large models such as #GPT_4V and #Bard on our new benchmark. https://t.co/kf2dU6ATDn
2️⃣ Chameleon: A framework that integrates various tools for math and science problems. https://t.co/pzfCQvddAR
3️⃣ ScienceQA: A multimodal benchmark for science, featuring annotations of lectures and solutions. https://t.co/dfTC0EFU8l
4️⃣ SciBench: A college-level benchmark focusing on science. https://t.co/0CHtkxbZZa
5️⃣ TheoremQA: a college-level benchmark for math reasoning, emphasizing theorem applications. https://t.co/E6zTZck5ns
6️⃣ Geometry3K: A benchmark for geometry problems, complemented with parsing annotations of logical forms and our leading neuro-symbolic approach. https://t.co/Na9OpsqZpO
Dive deeper with:
7️⃣ PromptPG/TabMWP: https://t.co/bLetcMfWed
8️⃣ DL4Math: https://t.co/ywDiWaA6Yu
9️⃣ Lila: https://t.co/X2v8Rpjk0d
🔟 IconQA: https://t.co/PkDNYVFxkl
*️⃣ UniGeo: https://t.co/3kNXAEm5KP

🚀 Google is introducing new updates to aid in learning math and science, especially in visual contexts.
💥 We're proud to spotlight our commitment to math and science over the past years, with projects like #MathVista, #Chameleon, and #ScienceQA.
1️⃣ MathVista: A 112-page study of evaluating math reasoning in visual contexts, with 12 large models such as #GPT_4V and #Bard on our new benchmark. https://t.co/kf2dU6ATDn
2️⃣ Chameleon: A framework that integrates various tools for math and science problems. https://t.co/pzfCQvddAR
3️⃣ ScienceQA: A multimodal benchmark for science, featuring annotations of lectures and solutions. https://t.co/dfTC0EFU8l
4️⃣ SciBench: A college-level benchmark focusing on science. https://t.co/0CHtkxbZZa
5️⃣ TheoremQA: a college-level benchmark for math reasoning, emphasizing theorem applications. https://t.co/E6zTZck5ns
6️⃣ Geometry3K: A benchmark for geometry problems, complemented with parsing annotations of logical forms and our leading neuro-symbolic approach. https://t.co/Na9OpsqZpO
Dive deeper with:
7️⃣ PromptPG/TabMWP: https://t.co/bLetcMfWed
8️⃣ DL4Math: https://t.co/ywDiWaA6Yu
9️⃣ Lila: https://t.co/X2v8Rpjk0d
🔟 IconQA: https://t.co/PkDNYVFxkl
*️⃣ UniGeo: https://t.co/3kNXAEm5KP
@google https://t.co/qrBsiXy0v8
Last Seen Hashtags on Sotwe
每日大赛
Seen from France
cumonface
Seen from United Kingdom
douchehabillé
Seen from Algeria
몽댕이
Seen from United States
vanessabohórquez
Seen from Colombia
รับงานเดิมบาง
Seen from Thailand
DL
Seen from United Kingdom
Chuday
Seen from Germany
姊弟
Seen from Korea
nolimit()****** filter:videos
Seen from Pakistan
Most Popular Users

Elon Musk 
@elonmusk
240.6M followers

Barack Obama
@barackobama
119.2M followers

Donald J. Trump
@realdonaldtrump
111.7M followers

Cristiano Ronaldo
@cristiano
110.6M followers

Narendra Modi
@narendramodi
107M followers

Rihanna
@rihanna
97.7M followers

NASA
@nasa
92.2M followers

Justin Bieber
@justinbieber
90.9M followers

KATY PERRY
@katyperry
87.7M followers

Taylor Swift
@taylorswift13
81.5M followers

Lady Gaga
@ladygaga
73.1M followers

Virat Kohli
@imvkohli
69.9M followers

Kim Kardashian
@kimkardashian
69.8M followers

YouTube
@youtube
68.7M followers

Bill Gates
@billgates
63.9M followers

Neymar Jr
@neymarjr
62.7M followers

The Ellen Show
@theellenshow
62.4M followers

CNN
@cnn
61.9M followers

X
@x
60.8M followers

Selena Gomez
@selenagomez
60.8M followers