Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
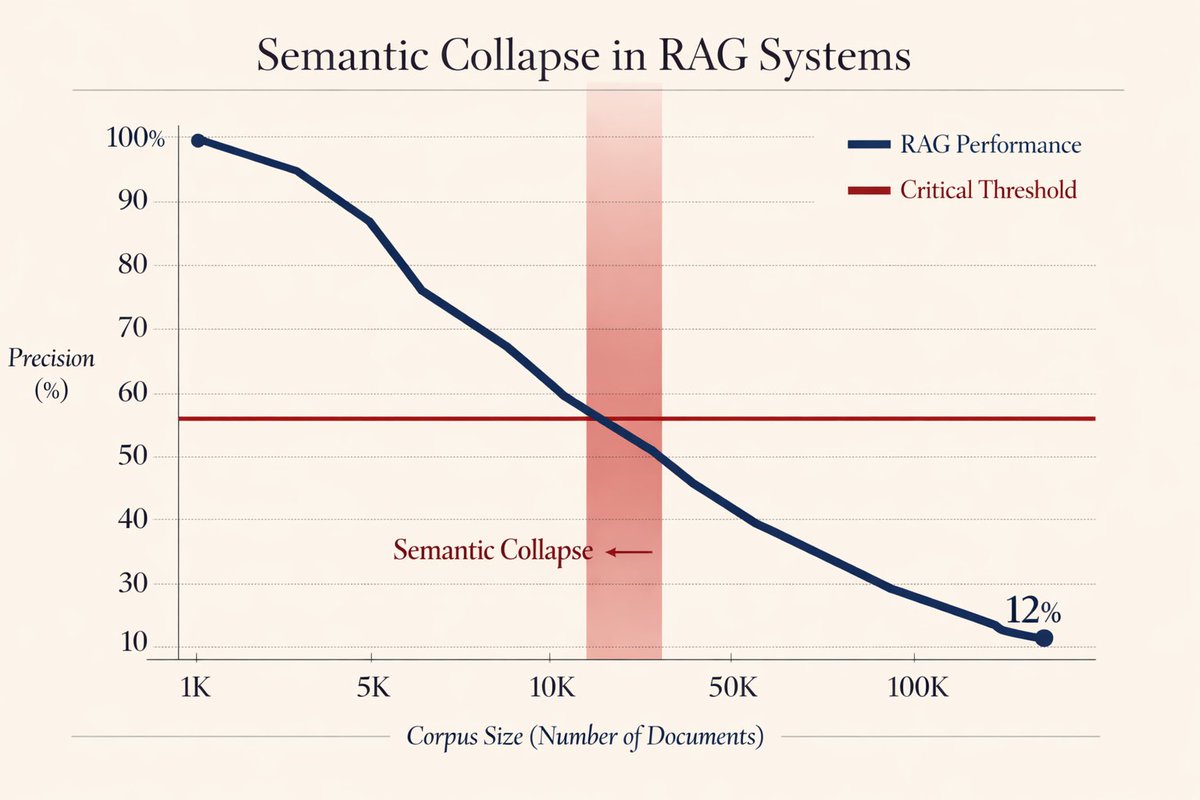
🚨 RAG is broken and nobody's talking about it.
Stanford just exposed the fatal flaw killing every "AI that reads your docs" product.
It's called "Semantic Collapse", and it happens the moment your knowledge base hits critical mass.
Here's the brutal math (and why your RAG system is already dying):