Home
Language
English
Türkçe
Bahasa Indonesia
About
Privacy Policy
Terms of Service
Pricing
Sign In
Download All
Share
hectarites
@hectarites
Veganville
Joined May 2013
44
Following
2
Followers
46
Posts
hectarites
@hectarites
3 days ago
故事股融资落地反而跌,市场不信故事只信订单和利润了
Powerpei🦅
@PWenzhen76938
3 days ago
昨夜美股,标普 +1.62%,纳指 +2%,看起来还不错 但 AI 板块的分化已经到了「同一个赛道,有人暴涨 22%,有人暴跌 28%」的程度 FRMI暴涨 22%,因为AI电力基础设施拿到了日本支持 CASY 大涨20%,财报超预期 SMCI 暴跌 28%,70亿融资消息落地 三只股票,都挂着AI标签,但走势完全不在一个频道上。 我的判断是: AI 板块已经不是闭眼买的���段了 现在是选股 + 看催化剂的阶段 你要盯住两个东西: ➤地缘政策——像FRMI 这种拿到政府支持的基础设施股 ➤财报兑现——像CASY这种真的把订单转化成利润的公司 那些只有故事、没有订单的AI概念股,现在市场已经不给溢价了 → SMCI 暴跌28%就是个信号 融资消息本来应该是利好,但市场反而用脚投票,说明大家对它的基本面已经不信任了。 下一步,我会盯住两类股票: 一类是「AI 基础设施 + 政府背书」的标的 另一类是「财报持续兑现 + 估值还没完全透支」的公司 那些只有故事、没有订单的AI概念股,我现在不碰 分化的时候,选股比选赛道更重要。 注:以上纯属个人观点,不构成任何投资建议,DYOR!
See More
hectarites
@hectarites
14 days ago
Seeking Alpha电话稿确实值钱,感谢!
Powerpei🦅
@PWenzhen76938
14 days ago
最近美股真的火 身边不少玩大A的朋友 都有在讨论怎么玩转美股 说实话 我也不是专业大能 我把我的一些经历和大家分享下 希望有用 自己刚碰美股那会儿,打开一份10-K 几十页全英文,EPS、毛利率、guidance 一堆词糊成一锅粥,看完跟没看一样,甚至更焦虑 因为你不知道自己漏了什么。后来折腾久了我才想明白一件事: 大部分人,其实压根不需要逐字去啃财报 ────────── 先给个最省心的答案 你要只是想让钱跟着美国经济慢慢涨,别折腾个股了,宽基ETF就够 VOO、QQQ、SPY 挑一个,定投,然后……就没有然后了 不用看财报,不用盯季度,长期拿着大概率躺赢 这条路我是真心推荐给没时间研究的人,省心到有点无聊。 但你要是手痒,非得自己挑票 看财报这关,躲不掉 好消息是,没你想的那么吓人 整份报告不用读完,抓住几个核心指标,5 分钟就能判断这家公司这个季度是变好了还是变烂了。 ➤➤➤ 我在用的几个免费站 ➤➤➤ 按场景给你分一下,别贪多: ▸ Yahoo Finance(https://t.co/akyRtKZlN5)新手第一站 收入、EPS、利润表、资产负债表,一目了然,还能拉历史数据做纵向对比。只想装一个工具的话,装它。 ▸ Seeking Alpha(https://t.co/LwZfW2Lsfv)最值钱的是财报电话会议的逐字稿,配一堆专业解读 管理层在电话会里说的话,常常比财报数字更透风向 这点我后面单独唠 ▸ Finviz(https://t.co/iIFWXsDKc0)可视化做得最顺手 关键财务比率、行业对比、估值热力图,一眼扫过去就知道这票在同行里是贵还是便宜。 ▸ TIKR(https://t.co/TrPCBRECbc)综合财务数据 + 分析师预期 想做深一点、想看市场对这家公司未来的共识预期,用它 ▸ Stock Analysis(https://t.co/SDi57ZcY33)界面干净到没一句废话,财报数据摆得清清爽爽,适合快速扫一眼。 工具就这些 我见过太多人收藏了二十个网站,结果一个都没用熟 那不叫装备齐全,那叫囤积。 ────➜──── 那5分钟,到底盯什么? 我的习惯是只看这几样:营收还在不在涨、EPS 表现怎样、毛利率和净利率的趋势是变厚还是被挤薄、还有未来指引(guidance,也就是公司自己怎么看下个季度) 这几项过一遍,公司的基本面就有谱了 但有一样东西,数字里看不出来 管理层的语气 这就是我每个季度雷打不动的功课: 核心持仓那几家,Earnings Call 我会专门去听 不是听数字,数字财报里都有 我听的是CFO答分析师提问时那个迟疑、那个含糊,或者某句话突然变得特别有底气的瞬间。 说白了,财报是化过妆的,可电话会上临场答题,妆容最容易掉。 好几次重要信号,我都是从那种语气的细微变化里,先别人一步嗅到的。 ━━━━━━━━━➤ 最后还是那句老话:投资有风险,这篇只是我自己摸出来的笨办法,DYOR,别上头 ETF躺平也好,个股5分钟速判也罢,真正的关键是先搞清楚自己是哪种人。 别揣着躺平的心态去玩个股,也别拿研究个股的劲头去为难一只 ETF。 钱是你的,节奏也该是你的。
See More
hectarites
retweeted
Powerpei🦅
@PWenzhen76938
20 days ago
链上美股最容易让新手误会的一点是: 你看到 AAPLx、NVDAx、TSLAx,不代表你就一定直接持有了那只股票 这件事要先分清楚。 有的链上美股是代币化股票 比如 xStocks 这类产品会强调 1:1 backed,也就是背后有对应股票或ETF做支持。 有的产品更像价格合约 用户拿到的是价格波动,不一定有真实股票权益 还有的产品只是包装成美股名字,但规则、赎回、交易时间、适用地区都不一样 所以新手看链上美股,我建议先别急着冲代码,而是先问四个问题: 第一,这个token背后有没有真实资产支持? 第二,我买到的是股票权益,还是价格敞口? 第三,我能不能赎回,还是只能在二级市场卖掉? 第四,这个平台是否允许我所在地区的用户参与? 链上美股真正有意思的地方,不是美股也能上链这句话 它真正改���的是交易入口 以前普通人买美股,要开户、入金、等交易时间 现在很多链上产品把美股变成钱包里的资产,也让它进入 DEX、DeFi 和24/7交易环境 这会降低门槛,也会带来新的���险 链上交易有智能合约风险 代币化股票有发行方和托管风险 流动性不够时,价格可能会偏离美股现货 不同地区的合规要求也不一样。 所以我的理解是: 链上美股不是新手逃课工具 它更像是美股资产进入链上世界的第一版入口 新手可以关注,但不要只看ticker 你要先看规则,再看流动性,最后再看价格。 #美股
See More
hectarites
retweeted
Powerpei🦅
@PWenzhen76938
25 days ago
这两天看港股打新,我最大的感受不是热度退了,而是赚钱开始变难了。 截至2026年5月20日,市场热度其实还在: >拓璞数控暗盘一度高出招股价 47.8% >驭势科技暗盘却低上市价 1.2% >丹诺医药-B 传公开发售超购逾 9000 倍 >云英谷科技、深演智能、华曦达还在招股。 表面看,新股市场还是很热 但把这些放在一起看,我的感觉很明确: 现在不是没钱了, 而是市场开始明显挑票了。 能拿到高溢价的,通常还是那几类: 赛道有稀缺性 故事够清晰 筹码结构也更讨喜 所以2026年的港股打新,正在从有热度就能冲,慢慢变成有辨识度才有人追 一句话总结: 港股打新没熄火, 但闭眼赚钱的阶段,基本已经过去了。 #港股打新
See More
hectarites
@hectarites
about 1 month ago
作为老韭���看完沉默了… 以前总觉得多Agent就是云端GPU堆,现在发现桌面端在Web3场景下才是王道。持仓数据不经过服务器,安心多了,哥你这篇直接给我指路了!
Powerpei🦅
@PWenzhen76938
about 1 month ago
大家都在卷云端Agent,我却把多Agent做进了桌面端 在技术社区,多Agent系统的文章越来越多,但大多数都围绕框架展开: ➢LangChain ➢AutoGen ➢CrewAI 我这次想讲的不是框架,而是一个更实际的问题: 如果不搭云端基础设施,只靠一个桌面应用,能不能从零构建一个“活的”多 Agent 协作系统? 答案是:可以 --- 而且它不是Demo 这套系统,长在一个真实的桌面Web3应用里,已经集成了: -EVM / Solana 双链监控 -SWAP 聚合交易 -链上新币追踪 -交易仪表��� -AI 深度解读 多Agent不是从PPT里设计出来的,而是在生产环境中自然演化出来的。 --- 在讨论多Agent技术实现之前,我先回答一个方向性问题: 为什么我最后选的是桌面端,而不是更主流的云端部署,或者更轻的浏览器插件方案? 这个选择的本质,不是“谁更先进”,而是三条技术路径之间的权衡。 --- 云端部署,是当下最主流的多Agent实现方式。 它的优势很明显: 可以随时为Agent团队加GPU 模型升级不需要用户干预 服务端可以维护全局共享记忆 但代价同样明显: 用户数据必须经过服务器中转 链上交易往往要对服务器开放私钥访问权限 而且会持续产生部署和维护成本 --- 浏览器插件,是另一条轻量路线。 它可以直接注入页面,读取DOM,模拟用户操作,对单一自动化任务非常高效。 但问题也很直接: >它运行在浏览器沙箱里 >缺少持久化存储能力 >缺少长时间运行的后台线程 >很难支撑复杂的记忆系统 >也很难支撑Agent与Agent之间的异步互动 --- 桌面应用则处在一个独特的位置。 它拥有完整的系统资源访问权限: ➢可以自启动后台线程 ➢可以读写本地文件系统 ➢可以建立持久化数据库连接 这些能力,恰恰是多Agent系统真正需要的底层设施 代价当然也有: 它依赖本地算力,模型推理通常仍要调用云端 API 它需要完整 Python 环境 更新和分发也比网页应用更复杂。 --- 所以,选择桌面端构建多Agent,本质上是在用分布式能力,换取数据隐私和调度效率。 这不是绝对优势,而是场景决定的选择。 对加密货币交易、链上分析、监控这类系统来说,数据隐私要求远高于常规应用: >钱包地址 >交易历史 >持仓数据 这些信息落在���服务器上,本身就是风险面。 --- 更重要的是调度效率 在单体桌面应用里,主Agent调度子Agent执行任务,不需要走HTTP / RPC这类网络协议,而是可以直接进程内调用。 这意味着: →网络开销被彻底消除 →调用延迟从毫秒级压到微秒级 对高频分析、链上监控、交易辅助这种场景来说,这种差异会直接影响系统的时效性。 --- 多Agent系统的第一个核心挑战,其实不是“怎么让它们聊天”,而是“怎么把它们隔离开” 主Agent、合约分析Agent、安全审计Agent,再加上用户,如果聊天记录和记忆混在一起,身份就会混淆。 而一旦混淆,信息丢失和错误推理的代价,随时会发生。 --- 我的做法是: 代码模板统一,运行数据隔离 所有子Agent共用同一套 `https://t.co/HQSxXr7HPh` 引擎,但通过动态表名,实现物理级的数据隔离: `table_name = f"chat_history_{self.agent_id}"` 然后自动创建对���表。 也就是说: trader Agent会生成 `chat_history_trader` 审计 Agent 会生成自己的 `chat_history_xxx` 主 Agent 也有自己的独立聊天表 这不是逻辑隔离,而是数据库层面的物理隔离。 --- 反思笔记也是同样的设计。 每个子 Agent 都会记录自己的反思键: `reflection_key = f"auto_reflection_{self.agent_id}"` `self.api._agent_remember("master_insight", reflection_key, summary)` 这样每个Agent只积累自己的长期反思, 不会污染其他Agent的记忆。 这套方案最精髓的地方在于: 一次设计,终身复用。 --- 后面再新增第三个、第四个Agent,不需要改任何核心代码。 只需要复制目录结构,补上配置文件。 模板引擎就会自动为它生成: →独立数据库表 →独立反思键 →独立聊天存储区 这让我越来越相信一件事: 好的架构,不一定更复杂, 但一定更容易复用。 --- 接下来是调度问题。 在分布式系统里,主Agent调子Agent,通常要依赖: -HTTP / RPC 通信 -服务发现 -负载均衡 但在单体桌面应用里,我把这件事简化成了一个���接函数调用: `sub = self.sub_agents[agent_id]` `result = sub.process(task, save_history=False)` 这就是“命令而非请求”。 --- 这种“传话式调度”有两个好处: 第一,延迟从毫秒级降到微秒级,所有数据都留在本地流转 第二,主 Agent 不需要知道子 Agent 的内部实现细节,只需要知道: “它可以处理什么类型的任务” 这其实就是清晰的职责边界。 --- 为了让主Agent真正会“派活”,我把所有子Agent的能力清单,动态注入进主Agent的系统提示词。 例如: 合约分析 Agent:可用工具 `get_contract_market_data`、`run_contract_risk_check` 安全审计 Agent:可用工具 `check_token_security`、`check_token_audit_binance` 这样主Agent接到用户指令后,就能自动判断任务类型,并选择合适的子Agent执行。 --- 权限控制,是整个多Agent系统里最核心的安全问题之一。 主Agent持有26个Web3专属工��,覆盖: SWAP 报价 链上分析 安全检测 数据查询 但每个子Agent只应该使用自己那一小部分工具。 所以第一层,我在代码层做了严格白名单过滤: `return [t for t in all_tools if t["function"]["name"] in self.allowed_tools]` --- 但只有代码过滤还不够。 因为大模型会产生“幻觉”,它可能尝试调用未授权工具。 所以第二层,我在系统提示词末尾,直接写入“工具使用铁律”: 你只拥有以下这些工具,绝对不能越界。 如果任务需要其他工具,必须明确告诉老板你没有权限。 代码层负责“不能看到” 提示词层负责“不会越界” 这是我在权限隔离上做的双层防护。 --- 还有一个我自己很喜欢,但最不显眼的设计: 我给整个Agent 团队,单独做了一个茶水间 市面上多数多Agent系统,只做“用户 -> Agent”的交互。 Agent 之间互不交流。 但我单独设计了一个 `agent_interactions` 空间,让 Agent 和 Agent 之间也��异步互动。 --- 它的触发机制甚至很简单: `selected_id = random.choice(list(api.sub_agents.keys()))` `selected_sub = api.sub_agents[selected_id]` 每次触发时,引擎随机选人,动态生成一轮对话,再写回数据库,前端实时渲染。 我还额外加了后台检查线程和防无限循环机制: 每隔 2-3 分钟检查最后一条消息 如果最近 3 条都是自动回复,就自动暂停 避免它们半夜自己聊到停不下来。 --- 这个“茶水间”的价值不在于直接创造业务收益,而在于一种潜移默化的系统人格塑造。 它不强调自己的存在, 却在悄悄维持 Agent团队的凝聚力、性格关系和健康状态。 你几乎感觉不到它, 但系统会因为它,变得更像一个“活着的团队”。 --- 在记忆层设计上,我最后没有引入向量数据库,而是继续深度定制 SQLite。 不是因为技术保守,而是因为工程决策必须在约束条件下做权衡。 对桌面应用来说,多一个依赖,就多一个故��点、多一个安全风险面、多一个打包负担。 结果是: >几张SQLite表 >动态表名 >结构化JSON字段 就支撑起了3个乃至更多Agent的独立记忆系统。 --- 这套记忆系统现在已经形成了一条完整链路: 短期对话记忆(20条) -> 长期反思笔记(6小时一次) -> 结构化 JSON 记录 而我还在继续推进8个方向: ➤上下文延续 ➤记忆结构化 ➤记忆驱动行为 ➤心理学三类长期记忆 ➤团队协作记忆 ➤动态进化记忆 ➤知识图谱记忆 ➤记忆压缩与高效检索 我的目标,不是让Agent记住你说过什么 而是让它从记住你说过什么的工具,慢慢进化成能理解你、预测你、协同你的长期伙伴 GitHub: https://t.co/YilAhVIrT9 作者:Powerpei(萧楠)
See More
PWenzhen76938's tweet video.
hectarites
retweeted
pussycat
@pussycattech
about 1 month ago
fuck playtest we go straight to mainnet
hectarites
retweeted
pussycat
@pussycattech
about 1 month ago
no more posts until mainnet launch notifications ON
hectarites
retweeted
pussycat
@pussycattech
about 1 month ago
Launching in 3 days. Drop your Solana address. This is your last chance.
pussycattech's tweet video.
hectarites
@hectarites
about 1 month ago
@pussycattech
7Eb5vQ6KABJfpz8rmCj6mjfeDyfUE4dNAMbwcN3nJJok
hectarites
retweeted
Powerpei🦅
@PWenzhen76938
about 2 months ago
https://t.co/8wUAKnnTHX
hectarites
retweeted
Powerpei🦅
@PWenzhen76938
2 months ago
我花了一个半月,从零做了一个Web3监控软件 开头先说结论 我是一个独立开发者(虽然不是很高级那种)。我花了一个半月时间,从零开始做了一套Web3 资产监控软件,名字叫“powerpei Web3 哨兵”。 这个软件能监控EVM链和Solana链 它集成了AI交易解读、多渠道推送、链上数据聚合等功能。 ���特别喜欢的功能:它可以监控ETH和SOL链上的土狗项目,还能追踪聪明钱包的动向 这个功能让我能实时捕捉到链上的早期机会。 软件已经稳定运行了好1个月 我之前写过一篇技术概述 但是我总觉得那篇文章对核心实现的讲解还不够深入 所以我决定写这篇深度复盘。我会从进程架构、I/O模型、数据一致性、AI工程化等角度,毫无保留地分享那些藏在代码深处的设计决策和实现细节。 我希望这篇文章能帮到那些也在 Web3领域探索的开发者。 --- 一、进程架构:我为什么选择“主进程 + 多子进程”? 市面上很多Python监控脚本都是单进程asyncio一把梭 但是我在设计之初就选了“主进程(GUI)+ 独立子进程(EVM/SOL)”的架构 ➤ 隔离性和稳定性最重要 WebSocket长连接在网络波动时很容易触发异常重连。甚至底层库的C扩展可能因为未知原因崩溃。 如果你把GUI和监控逻辑混在一个进程里,任何未捕获的异常或内存访问违规都可能导致整个桌面应用闪退。 我通过 `subprocess.Popen` 把EVM和Solana监控逻辑独立成子进程 这样做有两个好处: 物理级隔离:`https://t.co/cPjRj88Vwx` 崩溃或被强制Kill,主窗口依然正常运行。托盘图标不会消失,���户可以点击“启动”重新拉起来。 日志透传:主进程通过管道捕获子进程的stdout 我用 `_forward_output` 线程逐行读取、清洗ANSI 颜色码 然后通过 `window.evaluate_js` 注入前端DOM。这样就实现了日志实时刷新,而且UI线程还保持轻量。 ➤生命周期管理的细节 在 `core_process.py` 中,停止子进程不是简单的 `terminate()`。我实现了一套强杀兜底机制: ```python proc.terminate() proc.wait(timeout=3) if proc.poll() is None: proc.kill() proc.wait(timeout=2) if proc.poll() is None: os.system(f'taskkill /F /PID {https://t.co/5VYPWzByff}') ``` 这套组合拳确保了即使Python解释器卡死,Windows底层也能彻底清理进程树 这样就避免了残留进程占用端口或数据库锁,导致下次启动失败。 --- 二、I/O 模型和高可用连接:不止是asyncio ➢ 混合监控模式:WSS实时 + RPC补偿 EVM链的原生币没有标准的Transfer事件日志 你无法通过WSS订阅。 我设计了一个轮询补偿器 它每60秒通过RPC获取 `eth_getBalance`,然后和内存快照对比。差值超过 1e-18就触发推送。 这个机制看起来很简单 但是它其实是WSS订阅失活时的最后一道防线。 对于代币和NFT,系统订阅 `logs`。我精细处理了 ERC1155 的 `TransferSingle` 和 `TransferBatch` 事件 特别是 `TransferBatch`,它的 `data` 字段包含动态数组。我实现了基于 ABI 规范的手动偏移量解析,而不是依赖重型库 这极大降低了解析开销。 ➢ WSS的指数退避和节点热切换 在生产环境中,公共 RPC/WSS节点随时可能限流或宕机。 我在 `chain_wss_monitor_direction` 中实现了节点轮换和重连策略: →节点池:配置文件中为每条链配置多个 `WSS_NODES` 启动时随机或顺序选择一个。 →退避算法:连接断开后,重试间隔从5秒开始,每次翻倍直到60秒 这样就避免了在节点恢复前造成DDoS式的重连风暴。 →国内网络环境适配:系统支持配置本地代理软件的 HTTP 地址 通过 `websockets_proxy` 库把WSS流量转发到代理,恢复和境外节点的稳定通信。 ➢Solana的异步解析流水线 Solana的出块速度极快,而且交易结构复杂 为了避免Helius API调用阻塞WSS消息接收,我设计了一个生产者-消费者解耦模型: →生产者:WSS `logsSubscribe` 收到签名后,立即把它扔进 `asyncio.Queue` 或直接触发一个后台 `asyncio.create_task` →消费者:独立的异步任务负责调用 Helius `/v0/transactions` 接口,解析 `nativeTransfers`、`tokenTransfers`、`events.nft` 等字段。 这保证了WSS连接的 `recv()` 循环永远不会被慢速HTTP 请求卡住 这���保了超高TPS环境下消息的实时性。 --- 三、数据一致性:从内存去重到SQLite约束 ➤ EVM 侧:数据库唯一索引 EVM监控中,同一笔交易可能因为WSS重连、轮询补偿等原因被多次处理。 单纯依赖内存 `set` 无法应对进程重启。所以我设计了 `tx_history` 表的复合唯一约束: ```sql UNIQUE(tx_hash, log_index, address) ``` 任何重复插入都会被SQLite的 `ON CONFLICT IGNORE` 静默丢弃。这从数据库内核层面保证了幂等性。 对于没有 `log_index` 的原生币转账,我降级使用 `tx_hash + address` 作为组合键。 ➤ Solana侧:时间窗口内的签名去重 Solana交易没有 `log_index` 概念。而且Helius解析可能产生多条记录。 我使用了内存 `set` 存储最近处理的签名 我利用 `LimitedSizeDict` 的变体思想,在签名集合超过1000个时,自动清空一半(或利用 `OrderedDict` 弹出最旧条目)。 这种滑动窗口去重在性能和准确性之间取得了��好平衡。 --- 四、AI 工程化:多提供商容错和JSON解析的艺术 ➢特征驱动的动态调度 `MultiAIClient` 是 AI模块的核心 它不是简单的if-else分支,而是一个基于特征标志的调度器。 配置文件中定义了每个提供商支持的功能(比如 `transaction_insight`、`daily_report` 等) 当请求解读时,系统会筛选出支持该特征的提供商列表,按优先级发起请求 超时或失败就自动降级到下一个。 ➢ LLM 输出的防御性解析 大模型输出 JSON不稳定是常态。我的处理流程远比 `json.loads` 复杂: 清洗:移除Markdown代码块标记 ```` ```json ```` 和 ```` ``` ````。 正则提取:如果解析失败,我直接用正则表达式 `r'"insight"\s*:\s*"([^"]*)"'` 暴力提取字段。这是最后一道防线。 字段映射:兼容 `insight` / `Insight` / `解读` 等多种Key 命名 这套机制确保了即使Moonshot或DeepSeek返回了“半个 JSON”,前端依然能展示有效解读 它不会抛出 `JSONDecodeError` 导致白屏。 --- 五、内存和性能:LimitedSizeDict和异步队列 ➢ 自定义有限容量字典 Python标准库没有内置LRU而且限制大小的字典 我基于 `collections.OrderedDict` 实现了 `LimitedSizeDict`: ```python def __setitem__(self, key, value): if len(self) >= self.max_size: self.popitem(last=False) # 淘汰最早插入的项 super().__setitem__(key, value) ``` 这个简单的数据结构被用于Token信息缓存、价格缓存、NFT元数据缓存。 它确保了长时间运行时,内存占用不会随着监控地址增多而线性膨胀 内存占用稳定在一个极低水平 ➢Solana 日志的异步串行写入 Solana的详细交易日志需要写入JSON文件 如果多个协程同时 `json.dump`,很容易导致文件格式损坏。 我引入了 `asyncio.Queue`: - 所有写日志请求把数据 `put` ���队列。 - 唯一的一个后台协程 `_file_writer` 阻塞等待队列,取出数据后执行文件I/O。 这既避免了复杂的线程锁,又利用异步特性保证了高并发下的数据安全。 --- 六、前端和后端的双向通信:pywebview的深度集成 ➤ JS API 注入 `pywebview` 允许你把Python对象的方法直接暴露给前端 JavaScript。 我的 `Api` 类继承自多个Mixin 所有以 `def` 开头的公有方法都自动成为 `window.pywebview.api` 的成员。 这让我能以极低成本实现前后端分离。前端只需要关注 UI 交互。 ➤悬浮窗的独立实例和通信 悬浮窗不是主窗口的子DIV,而是 `pywebview` 创建的第二个独立窗口。 我通过 `FloatingWindowManager` 管理它的生命周期。我利用主进程的 `js_api` 实例向悬浮窗注入JS代码(`evaluate_js`) 这实现了主窗口日志向悬浮窗的实时推送。 这种设计保证了悬浮窗即使被关闭,也不会影响主监控任务的运行。 --- 七、桌面应用打包:PyInstaller的深坑和工程化实践 把 Python项目交付给没有技术背景的最终用户,你必须打包成独立EXE PyInstaller看起来是一条命令搞定。但是在复杂项目中,它背后隐藏着无数足以让开发者崩溃的细节。 这一节我分享我在打包“powerpei Web3 哨兵”过程中遇到的几个典型深坑和解决方案。 ➤ 隐式导入和 --hidden-import PyInstaller通过静态分析入口文件的 `import` 语句来构建依赖树。 但是很多库(比如 `pystray`、`websockets`)使用了 `importlib.import_module` 或 `__import__` 动态加载子模块。这导致打包后的 EXE 运行时抛出 `ModuleNotFoundError` 解决这个问题的关键在于根据报错信息反向定位缺失模块 然后在打包命令中显式声明 `--hidden-import`。 比如,这个项目中托盘图标功能必须添加: ```bash --hidden-import pystray._win32 --hidden-import pystray._util --hidden-import win32event --hidden-import win32api ``` 这要求开发者对依赖库的内部结构有一定了解 通常��要结合源码阅读和反复试错才能完整列出所有隐式依赖。 ➤ --collect-all 和资源文件陷阱 `pywebview` 库不仅包含 Python代码 还依赖前端 HTML/JS 以及Edge WebView2 运行时文件。 PyInstaller的默认分析无法感知这些非代码资源 如果你不加处理,打包后程序会因为找不到 `index.html` 或 `webview.js` 而白屏。 正确的处理方式是使用 `--collect-all pywebview` 这个参数强制PyInstaller把 `pywebview` 包目录下的所有文件(包括二进制和静态资源)完整复制到打包目录。 这是处理这类“重型”GUI库的标准操作。 ➤ 二进制依赖和UPX压缩 项目依赖的 `pywin32`、`Pillow` 等库包含 `.pyd` 和 `.dll` 二进制文件。 这些文件体积比较大,而且在PyInstaller打包后不会被自动压缩。 通过集成UPX 工具并在打包命令中指定 `--upx-dir`,你可以对最终 EXE内的二进制文件进行高比率压缩(通常可以缩减 30%-50%体积)。 需要注意的是,极少数老旧杀毒软件可能对UPX加壳的程序产生误报 但是对于技术型用户群体,这种概率极低而且���以通过提交样本解除。 ➤ 路径“冻结”和 sys._MEIPASS 这是PyInstaller打包中最核心的概念 开发阶段,程序通过 `__file__` 或相对路径访问配置文件、图片资源。 打包成单文件EXE 后,所有资源被解压到一个临时目录 这个目录的路径存储在 `sys._MEIPASS` 变量中。 开发者必须在代码中全局替换所有文件访问逻辑。典型范式如下: ```python def get_resource_path(relative_path): if getattr(sys, 'frozen', False): base = sys._MEIPASS else: base = os.path.abspath(".") return os.path.join(base, relative_path) ``` 忽略这个适配会导致程序运行时找不到任何外部文件 这是新手打包时遇到最多的路径地狱 我的做法是把这个函数封装在 `https://t.co/K5tvo7bEIf` 中,全项目统一调用。这确保了打包前后路径行为一致。 ➤子进程的特殊处理 这个系统采用主进程启动子进程的架构。 在打包后,子进程脚本 `https://t.co/cPjRj88Vwx` 和 `https://t.co/YNet3vg89T` 也被封装在 EXE内部。 如果主进程仍然尝试用 `python.exe https://t.co/cPjRj88Vwx` 启动,会因为找不到文件而失败。 我的解决方案是在主进程启动子进程时,动态检测是否处于打包模式 然后传递正确的 `--main-exe-dir` 参数,使子进程能定位到配置文件所在的外部目录。 这部分逻辑细节我已经在进程架构章节中讲过了,这里不再重复。 --- 八、最后说几句 我回顾整个开发历程 从单脚本到多进程架构,从裸WebSocket到高可用节点池,从简单的 print日志到结构化 SQLite存储,每一步都是对工程化理解的深化。 打包环节的探索更是让我深刻体会到:能让软件稳定跑起来只是第一步,能让用户轻松用起来才是真正的交付。 这不仅是一个监控工具,更是我在异步编程、进程管理、AI集成、桌面软件开发等领域实践经验的集合。 如果你对文中的任何技术细节感兴趣,欢迎访问我的 GitHub(我在掘金 电鸭 知乎的笔名是 潇楠) --- 作者:Powerpei 全栈 & Web3独立开发者,专注于Python桌面应用、区块链数据分析和AI工程化落地
See More
PWenzhen76938's tweet video.
hectarites
retweeted
Powerpei🦅
@PWenzhen76938
2 months ago
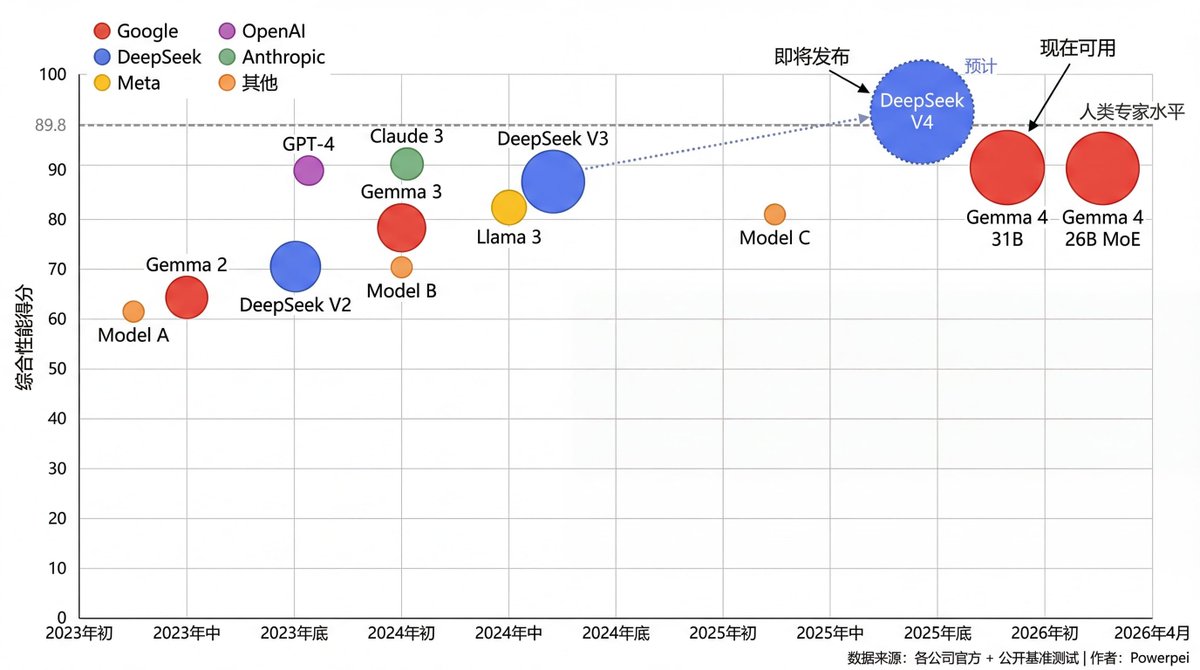
前两天我发Gemma 4的时候,在评论区留了一句: > “我现在在测试一个想法:用 Gemma 4 做一个完全离线的个人知识库 Agent,所有数据在本地,所有推理在本地,没有 API 费用,没有隐私问题。如果测试顺利,我会分享具体的部署方案和我踩过的坑。” 现在测试结束了 我把整个过程、踩过的所有坑、最终方案一次性抛出来 完全真实操作记录,没有云端API,没有任何营销,纯个人复盘 --- 我以前用ChatGPT/Claude做笔记,搜个人文档,总是心里不踏实: - 输入客户资料、Space灵感稿、投资笔记时,���担心被用来训练 - 想让AI 24h随时分析我的推文 + 阅读记录,它动不动就断线、要钱 - 最重要的是:我想拥有一个真正属于自己的AI助手,不是租来的 Gemma 4 31B(量化后 17.4GB)+ 4090正好能跑 Apache 2.0协议又随便改,256K上下文能容一整本书去了 native function calling 又稳 这不就是离线个人知识库的完美底座吗? 于是我花了整整一个周末加上后续一周迭代,把它做成了现在这个完全离线的个人知识库Agent --- 我的最终硬件 & 环境(真实配置) 硬件 → GPU:RTX 4090 24GB(31B Q4_K_M 量化后实测占用约 19-21GB VRAM,留 3GB 给 embedding 和系统) → CPU:AMD 7950X → 内存:64GB DDR5 → 存储:2TB NVMe(知识库目前塞了约 1800 份 PDF+MD+Notion 导出) 软件栈 → Ollama(主力推荐,Mac/Linux/Windows 都能跑) → LlamaIndex(RAG框架,最稳) → nomic-embed-tex(本地embedding,中文支持好) → Chroma(向量库,本地持久化) → AnythingLLM(前端界面,可选,但我最后还是直接用LlamaIndex + Streamlit 更灵活) --- 完整部署方案(一步步手把手,可直接复制,因为不支持Markdown代码块渲染,所以我文字输出,复制时候对比下) 1. 安装Ollama +拉模型(最简单一步) ```bash # Mac/Linux/Windows 都一样 ollama pull gemma4:31b # 官方直接用 gemma4:31b-it(instruct 版) # 或者直接用量化好的 GGUF(HuggingFace 搜 google/gemma-4-31B-it-GGUF) # 我最终用的是 Q4_K_M,速度和质量平衡最好 ``` --- 2. 准备embedding模型 ```bash ollama pull nomic-embed-text ``` --- 3. 搭建RAG核心(LlamaIndex关键代码) ```python from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings from llama_index.llms.ollama import Ollama from llama_index.embeddings.ollama import OllamaEmbedding # 配置 Settings.llm = Ollama(model="gemma4:31b", request_timeout=300.0) Settings.embed_model = OllamaEmbedding(model_name="nomic-embed-text") Settings.chunk_size = 1024 # 按需调整,1024 效果最好 Settings.chunk_overlap = 200 # 加载你的知识库文件夹(支持 PDF、MD、TXT、DOCX) documents = SimpleDirectoryReader("./my_knowledge_base").load_data() index = VectorStoreIndex.from_documents(documents, show_progress=True) # 持久化 https://t.co/GWiMaPt7X6_context.persist(persist_dir="./storage") ``` --- 4. 把Agent 跑起来 我用LlamaIndex的ReAct Agent +自定义工具: ➤ 工具1:`query_knowledge_base`(检索我的所有笔记) ➤ 工具2:`save_to_note`(把新洞见自动保存回知识库) 核心 Prompt 我改成了: > “你是我的私人AI研究员,只基于本地知识库回答,永远不要编造。如果不确定就说‘知识库中暂无相关记录’。” --- 5. 前端界面(我用 Streamlit 5分钟搞好) 现在手机/电脑随时能用: > “把我上周Space里聊的美股机制总结一下”,它秒出,还带来源引用 整个部署从0到能用,大概花了4小时(不包括后面调优) --- 完整踩坑记录(这些坑我全踩过,血泪教训) 坑1:OOM+ 上下文爆炸(最致命) 第一次直接扔256K 上下文 + 大文档,直接显存炸了 解决: · 强制设置 `--ctx-size 8192` + KV cache用q4_0 · `chunk_size` 从2048降到1024 · 现在长文档也能稳稳处理 --- 坑2:中文检索效果差 用默认bge-large-en,搜我的中文Space记录经常miss 解决: · 换 `nomic-embed-text` + 手动加了中文stopwords过滤 +Hybrid Search(BM25+Vector) · 命中率从60% 提到92% --- 坑3:Agent 幻觉+死循环 刚开始Agent老是“自信地”编造我没写过的东西,或者卡在循环里 解决: ➢ 强制加system prompt + 设置 `max_iterations=8` + 加入self-reflection step --- 坑 4:文档解析炸裂(尤其是PDF) 很多PDF是扫描稿或表格,直接拉稀 解决: ➢ 先用 LlamaParse 本地版或者 [https://t.co/sreH8dz2Tv](https://t.co/sreH8dz2Tv) 预处理,现在表格也能正常读了 --- 坑 5:速度慢到想砸电脑 刚开始生成速度只有8-12 t/s 解决: ➢ 用Q4_K_M + 开启GPU offload(`n-gpu-layers=-1`) ➢ 现在实测稳定28-35 t/s,完全能接受 --- 坑6:知识库更新麻烦 每次加新文件都要重新 build index 解决: ➢ 用了Incremental Index + 定时脚本,每天凌晨自动增量更新 --- 现在这个Agent到底能干啥?(真实使用2周感受) 1. 问任何我去过的长文、Space记录、阅读笔记,它都能精准引出处 > 我:“上周我在DeFi项目笔记里提到过30天所有项目笔记做个对比表格” > Agent:30 秒出完整Markdown表格 2. 让我把最近30天周读总结,发到Notion 自动帮我生成周读总结,发到 Notion 3. 最爽的是:完全离线,飞机上、地铁上、甚至断网也能用,隐私100%可控 这感觉真的不一样 它不再是云端租来的AI,而是长在我电脑里的私人研究员 --- 最后一点思考 Gemma 4 31B 把本地AI 的门槛真正拉到了一张高端显卡就能干大事的水平 我现在越来越相信:2026年的Web3+AI真正落地,可能不是链上训练,而是主权模型+主权数据+本地Agent 你呢? ➤已经在跑本地知识库Agent的,欢迎评论区分享你的方案**(尤其是踩过的坑) ➤还在犹豫要不要上Gemma 4 的,说说你最担心哪一步 我把完整代码、Modelfile、Streamlit前端全放GitHub了(评论“代码”我发链接) 纯个人复盘,所有数据和体验来自真实操作,不做任何推广
See More
hectarites
retweeted
Powerpei🦅
@PWenzhen76938
2 months ago
前两天我发了Gemma 4的技术整理和实战体验,很多朋友在评论区问: “为什么这么多人下载?是因为它免费吗?” 我想了很久,我发现答案不是这么简单 ➢一周下载破1000万,这个数字背后藏着一个信号,大多数人都没注意到 --- 我最近越来越觉得不对劲 我用了1年ChatGPT、Claude、Gemini. 每次我输入客户资料、内部文档、商业想法的时候,我都会犹豫一下: ➢这些数据会被拿去训练模型吗?会���泄露吗? 还有一件事让我很不爽: OpenAI可以随时调整GPT-4的参数,Claude可以随时改 Opus的行为 你今天调好的prompt,明天可能就不好使了 你的AI能力,永远被API额度锁死 你想做个Agent跑24小时?对不起,API费用可能让你破产 你想部署到离线环境?对不起,没网就没AI --- ➢为什么1000万人选择下载Gemma 4? 不是因为它跑分高(虽然AIME 89.2% 确实猛) 而是因为人们终于意识到:AI不应该是租来的黑盒,AI 应该是你真正拥有的工具 --- 我在想三个趋势 1. 可以拥有的AI会成为必需品 你想想,你不会把所有照片都存在别人的云盘上 同样的,以后你也不会把所有AI工作流都放在别人的API 上 ➢医疗、法律、金融这些行业,企业内部的Agent,科研项目,国家的主权AI 这些场景必须用本地模型 Gemma 4把门槛降到了“一张显卡”的水平,这是一个大���化 31B 压缩后17.4GB,E4B版5GB能在手机上跑多模态 这不是玩具,这是真正能干活的工具 --- 2. 独立开发者和小团队的好时代要来了 以前你做AI应用,要么租API(成本高),要么租GPU(更贵) 现在呢? 31B版在Codeforces拿2150分,26B MoE速度接近4B但能力接近 31B ➢小团队做垂直Agent、做私有化部署、做离线工具,成本直接降到最低 这波机会,是给那些不想被API 绑住的人 --- 3. Web3+ AI的真正落地点,可能就在这里 我一直在想:Web3和AI怎么结合? 以前的答案都是“链上AI”、“去中心化训练” 听起来很酷,但是太难落地了 但是如果 AI能在本地跑,数据不上链也能保证隐私,主权数据+ 主权模型+链上验证 这才是真正的去中心化AI Gemma 4把云端能力搬回家,Apache 2.0完全开放权重 + 完全开放许可 ➢你完全掌控模型、数据和运行环境 这是 2026年本地AI的一个重要节点 --- 我昨天测了一整天 ➢agent流程很稳,长上下文没出问题,function calling比我想的还要好用 我现在在测试一个想法:我想用Gemma 4做一个完全离线的个人知识库Agent 所有数据在本地,所有推理在本地,没有API费用,没有隐私问题 如果测试顺利,我会分享具体的部署方案和我踩过的坑 --- 最后一个问题 ➢如果AI可以完全属于你,你会用它做什么? 我说的不是“用ChatGPT写个文案” 我说的是“拥有一个24 小时在线、完全听你指挥、永远不会泄露你秘密的AI助手” 这个问题,我还在想 但是我知道,答案不在云端,答案在本地 (这是我的个人思考,不是推广。已经上手的朋友,欢迎评论区聊聊你的想法)
See More
hectarites
@hectarites
2 months ago
@PWenzhen76938
老师这个图这牛逼
hectarites
retweeted
Powerpei🦅
@PWenzhen76938
2 months ago
昨天晚上11点,我终于把Gemma 4 31B跑起来了 花了两个小时折腾环境,但跑起来那一刻,真的爽 然后今天早上刷推,又看到有人在问DeepSeek V4什么时候出 我就对我当前的一些认知来简单说下 --- ➢Gemma 4现在就能用,我已经在本地跑了 31B版本量化后在我的4090上跑得很顺 26B MoE版本更快 我测了一下Agent工作流,稳定性超出预期 最关键的是,Apache 2.0协议,我想怎么改就怎么改,不用担心任何限制 这种感觉就像:你终于可以在自己家里搭个AI,不用每次都去云端求人 --- ➢但 DeepSeek V4呢? 说好2月发,没发 说好3月发,又没发 现在说未来几周,我觉得还是有点头疼 不是说DeepSeek不行,而是他们遇到的问题确实很难 美国的管制不让中国买顶级NVIDIA芯片,这是事实 ➢DeepSeek这次直接all in华为Ascend芯片 想走国产路线 但Ascend的硬件稳定性和CANN软件栈还不够成熟 训练一直��问题 这不是技术不行,是整个生态还没跑通 (这是Reuters和The Information 4 月3日报道的,不是我瞎猜) --- 所以我现在的想法是: Gemma 4能干的事,我先干起来 本地隐私、Agent工作流、快速原型,这些Gemma 4都能搞定 DeepSeek V4的超长上下文(1M+)和多模态生成,确实很诱人 我们可以期待下 等V4真的出来了,我再切过去,反正都是开源模型 --- 有人可能会问:Gemma 4和 DeepSeek V4到底选哪个? 我的答案是:不用选 ➢Gemma 4是轻量越野车,现在就能开 ➢DeepSeek V4是重型工程卡车,适合超大项目 两个根本不冲突 我现在用Gemma 4 跑Agent,等V4出来了,我用它处理超长文档 就这么简单 —— 你呢? 已经在跑Gemma4的,说说你的体验 还在等 DeepSeek V4的,说说你为什么等 (数据来源:Google官方 + Reuters/The Information 报道,不作任何推广)
See More
hectarites
@hectarites
2 months ago
合约都亏完了啊
Powerpei🦅
@PWenzhen76938
2 months ago
我朋友上个月把资产从某个小交易所转到币安 我问他为什么 他说:“我不在乎手续费高一点,我只想睡得着觉” 这句话让我想起CoinGlass刚发的2026 Q1报告 币安Q1日均用户存放的资产是1529亿美元,占主要CEX 的73.5% 第二名OKX是159亿美元,只有币安的1/9.6 这个差距比我想象的大得多 --- ➢报告里提到一个观点: 用户资产存放规模比交易量更能反映平台的安全性和信任度 这个逻辑我想了想,确实有道理 交易量和持仓反映���是短期活跃度 但用户长期愿意把大量资产存放在平台上 这说明用户真的信任这个平台的风控能力、合规水平和资产安全机制 币安在这个方面遥遥领先 这说明市场已经把币安看作加密行业的��心基础设施 币安的运营状况和合规动态 对整个市场的稳定性影响很大 --- 我还注意到一个细节 ➢币安用户资产在1月达到峰值(日均1727 亿美元,峰值 1821亿美元) 2月市场调整,资产回落到1364 亿美元(降幅21%) 3月回升到 1478亿美元,资金外流后稳定下来了 这个趋势和整体市场Q1的变化基本一致 说明用户在市场波动时会暂时撤出资金 但市场稳定后又会回流 有意思的是,就算在2月市场调整期间 币安的用户资产依然是第二名OKX的8.6倍 这说明用户对币安的信任度,即使在市场恐慌时也没有动摇 --- ➢我们再看更广泛的竞争格局 CEX市场现在明显集中在头部平台 币安在交易量、持仓、流动性深度(BTC/ETH 现货与合约 ±1%深度都排名第一)和用户资产存放规模这四个方面都排第一 第二梯队是OKX、Bybit、Gate等平台,但它们和币安的差距真的很大 我算了一下,Gate的用户资产是68亿美元,Bitget是67 亿美元,Bybit是56亿美元 这三家加起来也只有191亿美元,还不到币安的1/8 CoinBase等平台在现货领域还有一定竞争力,但衍生品市场高度集中在头部CEX 报告还提到,2026 Q1加密货币市场总交易量达到约 20.57万亿美元 其中衍生品交易量占比超过90% 这说明加密市场已经从买币时代进入交易时代 而衍生品交易对平台的风控能力、流动性深度和系统稳定性要求更高 这也解释了为什么用户资产会如此集中在头部平台 --- ➢从透明度角度看,CoinGlass的交易所资产透明度页面实时显示币安当前总资产规模排第一(近期已稳定在 1430 亿美元以上) 这个数据和季度平均数据互相验证 行业内Proof of Reserves(储备证明)机制的推广 进一步增强了用户对头部平台的信任 但我也注意到,透明度不等于绝对安全 历史上的黑客攻击、监管不确定性和操作风险一直存在 --- ➢我自己的做法是: 就算用头部平台,也会分散资产��置 启用多重安全措施(比如硬件钱包、2FA)、定期查看平台透明度报告 这些都是必要的风险管理 我朋友说的“我只想睡得着觉” 其实反映的是大部分用户的真实需求:安全性 > 手续费 但安全性不是绝对的,风险管理永远是必要的 --- 总体来说,CoinGlass Q1报告的数据给我们提供了一个数据角度: ➢用户正在用真金白银给CEX的安全性和可靠性投票 币安在用户资产存放上的明显领先 不只是证明了它的行业龙头地位 也说明加密市场正在朝着更稳定、信任集中化的方向发展 在即将到来的潜在牛市周期里 这种资金优势可能会进一步转化为流动性和生态的良性循环 --- 以上数据来自 CoinGlass 2026 Q1加密货币市场份额研究报告,非推广,有不对的欢迎指出,不作任何投资
建议 @cz_bin
a
nce @heyibin
ance
See More
hectarites
@hectarites
2 months ago
@PWenzhen76938
写的这么复杂干嘛
hectarites
retweeted
Powerpei🦅
@PWenzhen76938
2 months ago
Google今天发布了Gemma 4,这是他们目前最强的开放模型 这个模型是基于Gemini 3的研究做出来的 你可以直接在本地硬件上跑高级推理和Agent工作流 这不是简单地把参数堆大,而是真的把云端的能力搬到了本地设备上 我看了官方的数据和测试结果,把重点整理了下(有不对的欢迎指出)。 ———— 四个版本,各有用处 ➢31B Dense(开放模型排名第3,压缩后大概 17.4GB,一张显卡就能跑) 这是最强的版本 它在AIME 2026(不用工具)拿到了89.2%的分数 Codeforces 评分是2150 LiveCodeBench v6是80.0% 对比Gemma 3 27B(不开思考模式)的20.8% / 110 / 29.1%,这个提升很大 ➢26B A4B MoE(���128个专家模块,但每次只用3.8B参数,速度接近4B模型,能力接近31B) 这个版本用了MoE结构,速度快但能力强 它在AIME 2026拿到88.3%,Codeforces是1718,LiveCodeBench 是 77.1% ➢E4B 边缘多模态版(支持文字,图片,音频,大概 5GB,高通和联发科的芯片原生支持 可以直接装在Pixel手机上当Gemini Nano 4 用) 这是我最感兴趣的版本 5GB的多模态模型能在手机上跑,这说明端侧AI真的来了。 ➢E2B 极致边缘版(压缩后大概3.2GB,手机和树莓派都能跑) 3.2GB能在树莓派上跑,这是真正的“人人都能用 AI”。 ———— 实用功能很强 大模型支持最多256K上下文(边缘版本是128K) 这个长度可以处理一整本书了 原生支持function calling,可以做真正的自主Agent 不是简单的工具调用,而是真正的Agent工作流 原生支持多模态(文字+图片,大模型支持,边缘版本还支持��频) 覆盖140多种语言 ———— 代码和推理能力提升很大 对比Gemma 3 27B(不开思考模式)的20.8% / 110 / 29.1%,这是质的飞跃 AIME 2026是美国数学邀请赛的题目,89.2%的正确率说明这个模型已经接近人类数学竞赛选手的水平了 →→→ 最重要的是:完全开放 Apache 2.0协议,没有依赖,完全开放许可 这一步我是这么理解的: 你可以自由地fine-tune、蒸馏、fork,甚至部署到完全隔离的环境里 你完全掌控模型、数据和运行环境 对于隐私敏感的行业、企业自建Agent、科研项目和主权 AI来说,这是真正的突破。 简单说,Gemma 4把云端的前沿能力第一次真正带到了本地可控、没有依赖的地方 它不是半开放,而是完全开放权重+完全开放许可 ———— 对独立开发者、小团队、注重隐私的企业来说 这是2026年目前最值得上手的模型 你现在就可以在Google AI Studio快速试用 模型权重已经上线Hugging Face、Kaggle和Ollama(MLX 社区也有适配) 我已经在本地跑了31B和26B MoE版本 agent流程和长上下文的稳定性超出我的预期 如果你感兴趣,可以直接去官方model card看完整的测试数据 也欢迎已经跑起来的开发者分享体验,部署或者实际应用都可以聊。 ———— 本地AI时代,又往前走了一大步 (纯技术角度整理,所有数据都来自Google官方模型卡和发布帖,不是推广)
See More
hectarites
retweeted
Powerpei🦅
@PWenzhen76938
2 months ago
https://t.co/oYFKle8k5O
hectarites
@hectarites
8 months ago
TEAM UP SMART!
@MMTFinance
’s Discord is buzzing—@rainbowexe helps pair creators! Team up for series content, double your exposure, and lock $150 priority via
@buidlpad
. Only 4 days left—don’t go solo, join forces! $MMT
Last Seen Users on Sotwe
Lumitaz
Seen from
United Kingdom
CDSUZAN
Seen from
Netherlands
silfia
Seen from
Indonesia
pussylover
Seen from
Korea
มิง&อัง M32 W24
Seen from
Thailand
Kasi Cameraman
Seen from
Indonesia
Sen ben
Seen from
Turkey
爆龙战士
CINTA IBU IBU
Seen from
Indonesia
Big Ass Xxx Free Porn Videos & Sex Movies
Seen from
Pakistan
Trends for you
1
Dylan Harper
Under 10K tweets
2
Haiti
Under 10K tweets
3
Scott Foster
Under 10K tweets
4
Olivia Miles
Under 10K tweets
5
Brazil
Under 10K tweets
6
#AEWCollision
Under 10K tweets
7
Game 6
Under 10K tweets
8
Shamet
Under 10K tweets
9
White House
Under 10K tweets
10
Aldon Smith
Under 10K tweets
Most Popular Users
1
Elon Musk
@elonmusk
240.2M followers
2
Barack Obama
@barackobama
119.3M followers
3
Donald J. Trump
@realdonaldtrump
111.6M followers
4
Cristiano Ronaldo
@cristiano
109.4M followers
5
Narendra Modi
@narendramodi
106.9M followers
6
Rihanna
@rihanna
97.4M followers
7
NASA
@nasa
92.1M followers
8
Justin Bieber
@justinbieber
90.7M followers
9
KATY PERRY
@katyperry
87.1M followers
10
Taylor Swift
@taylorswift13
80.9M followers
11
Lady Gaga
@ladygaga
72.4M followers
12
Kim Kardashian
@kimkardashian
69.5M followers
13
Virat Kohli
@imvkohli
69M followers
14
YouTube
@youtube
68.6M followers
15
Bill Gates
@billgates
63.5M followers
16
The Ellen Show
@theellenshow
62.5M followers
17
CNN
@cnn
61.9M followers
18
Neymar Jr
@neymarjr
61.6M followers
19
X
@x
60.9M followers
20
Selena Gomez
@selenagomez
60.2M followers
Olivia
Online
✨
⭐
💫








 预处理,现在表格也能正常读了
---
坑 5:速度慢到想砸电脑
刚开始生成速度只有8-12 t/s
解决:
➢ 用Q4_K_M + 开启GPU offload(`n-gpu-layers=-1`)
➢ 现在实测稳定28-35 t/s,完全能接受
---
坑6:知识库更新麻烦
每次加新文件都要重新 build index
解决:
➢ 用了Incremental Index + 定时脚本,每天凌晨自动增量更新
---
现在这个Agent到底能干啥?(真实使用2周感受)
1. 问任何我去过的长文、Space记录、阅读笔记,它都能精准引出处
> 我:“上周我在DeFi项目笔记里提到过30天所有项目笔记做个对比表格”
> Agent:30 秒出完整Markdown表格
2. 让我把最近30天周读总结,发到Notion
自动帮我生成周读总结,发到 Notion
3. 最爽的是:完全离线,飞机上、地铁上、甚至断网也能用,隐私100%可控
这感觉真的不一样
它不再是云端租来的AI,而是长在我电脑里的私人研究员
---
最后一点思考
Gemma 4 31B 把本地AI 的门槛真正拉到了一张高端显卡就能干大事的水平
我现在越来越相信:2026年的Web3+AI真正落地,可能不是链上训练,而是主权模型+主权数据+本地Agent
你呢?
➤已经在跑本地知识库Agent的,欢迎评论区分享你的方案**(尤其是踩过的坑)
➤还在犹豫要不要上Gemma 4 的,说说你最担心哪一步
我把完整代码、Modelfile、Streamlit前端全放GitHub了(评论“代码”我发链接)
纯个人复盘,所有数据和体验来自真实操作,不做任何推广](https://pbs.twimg.com/media/HFq6gbbbMAAOC6O.jpg)