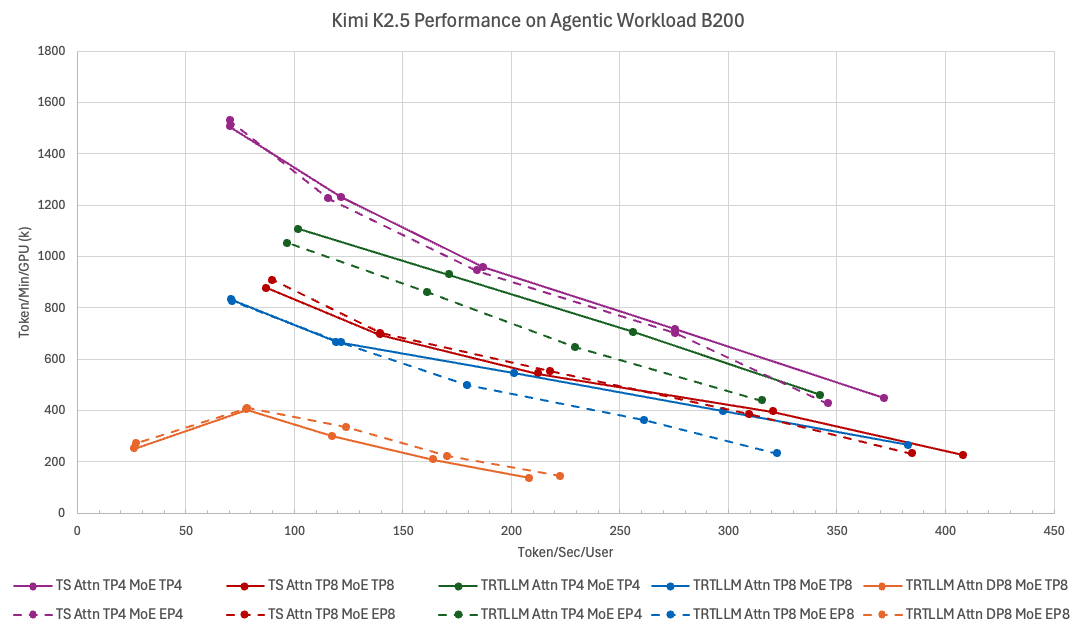
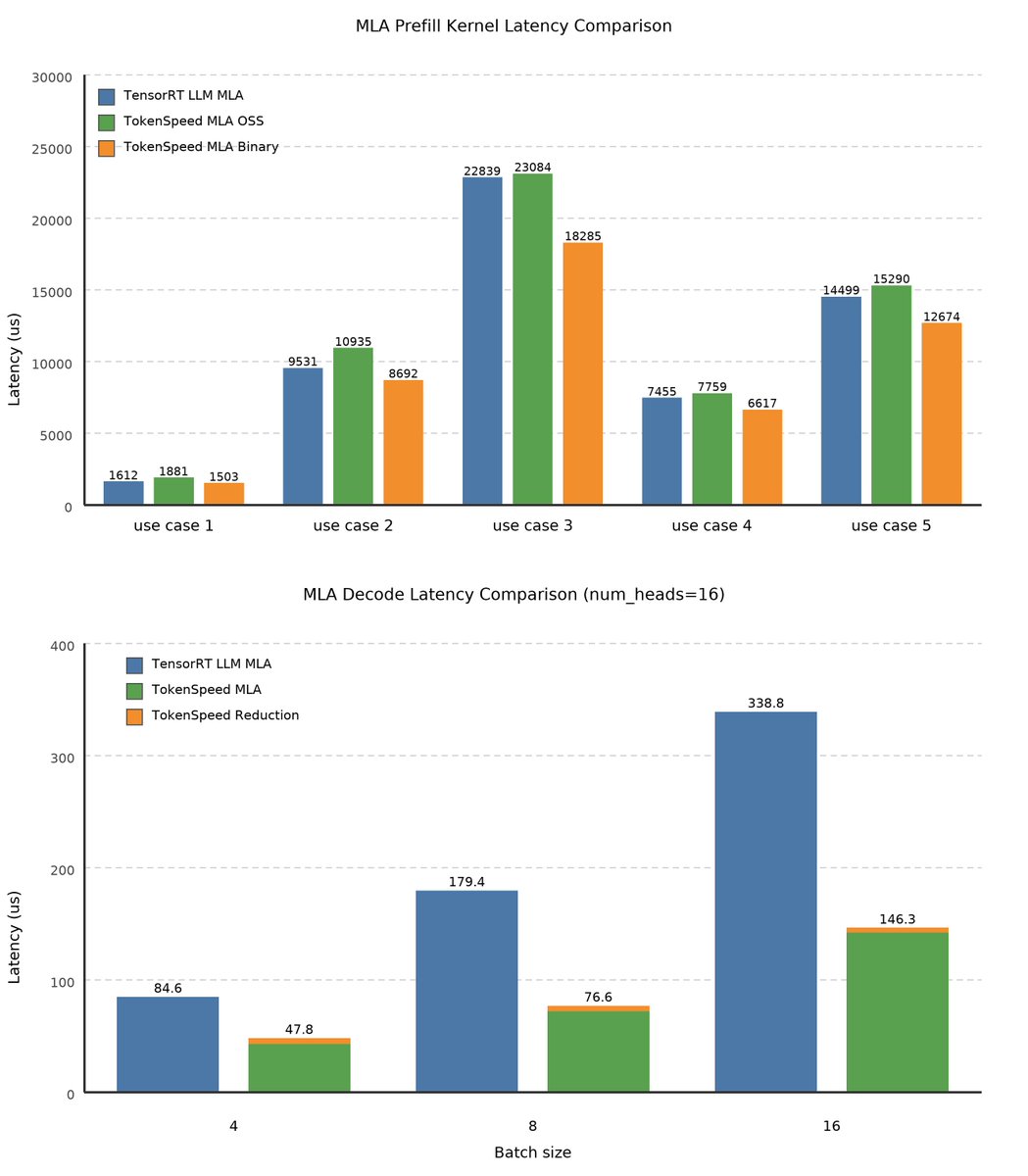
Introducing TokenSpeed, a speed-of-light LLM inference engine.
> TensorRT LLM level performance
> vLLM level usability
> Built by a lean and mission-driven team in two months
> MIT license, open-source
https://t.co/MJzhCEg7m8
https://t.co/anhoETwwS9
Today's dstack 0.19.38 release introduces Routers, enabling @sgl_project's new Model Gateway integration inside dstack Gateways.
Routers support routing policies like `cache_aware`, enabling KV-cache reuse for lower latency conversational and repeated-pattern workloads.
Release notes: https://t.co/PIvGsw4EUM
This sets the stage for disaggregated prefill/decode coming soon to dstack services.
Bigger announcement + roadmap for SGLang integration coming early next week!
⏳Waiting for your LLM to respond? SGLang Model Gateway v0.2.3 just dropped and it’s 20–30% faster, smarter with tool & function support, and PostgreSQL-ready. Here’s what’s new 👇
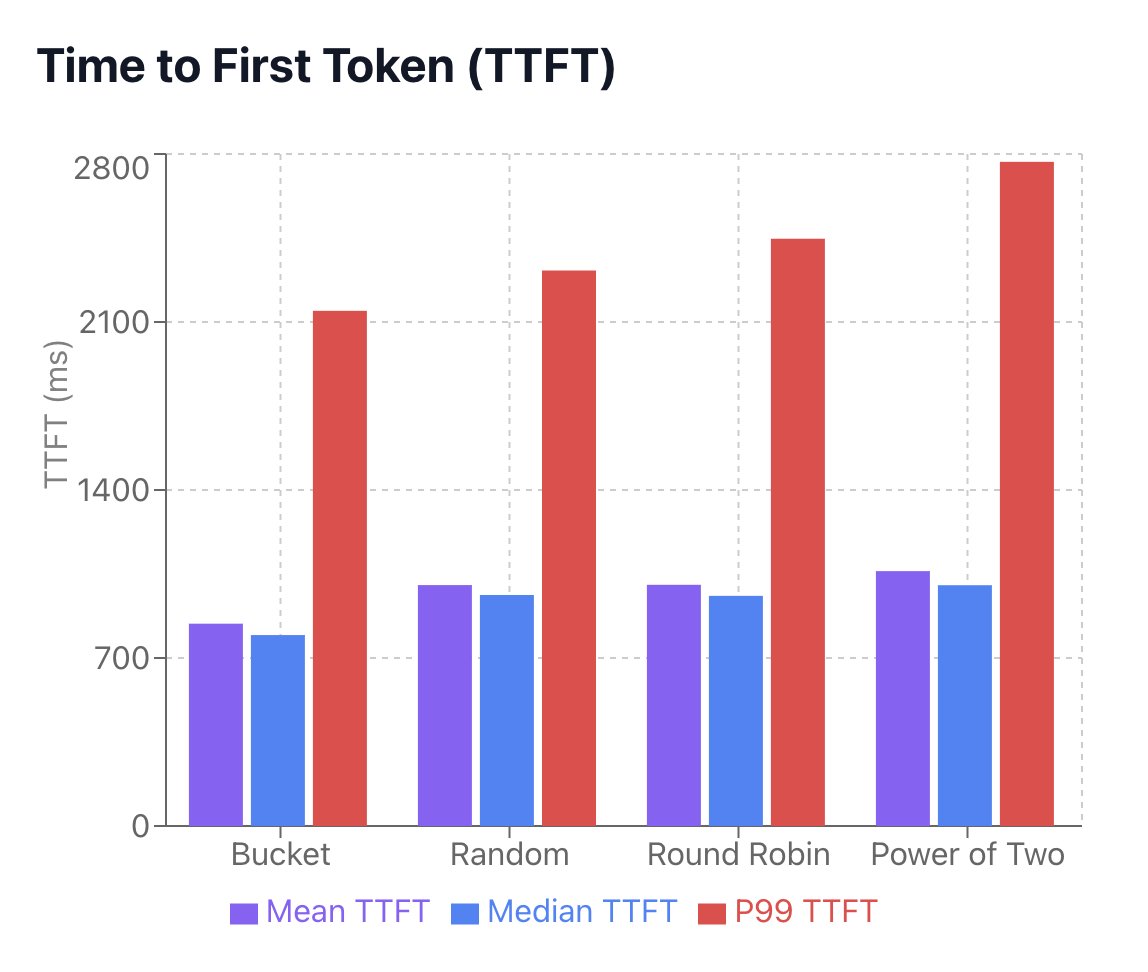
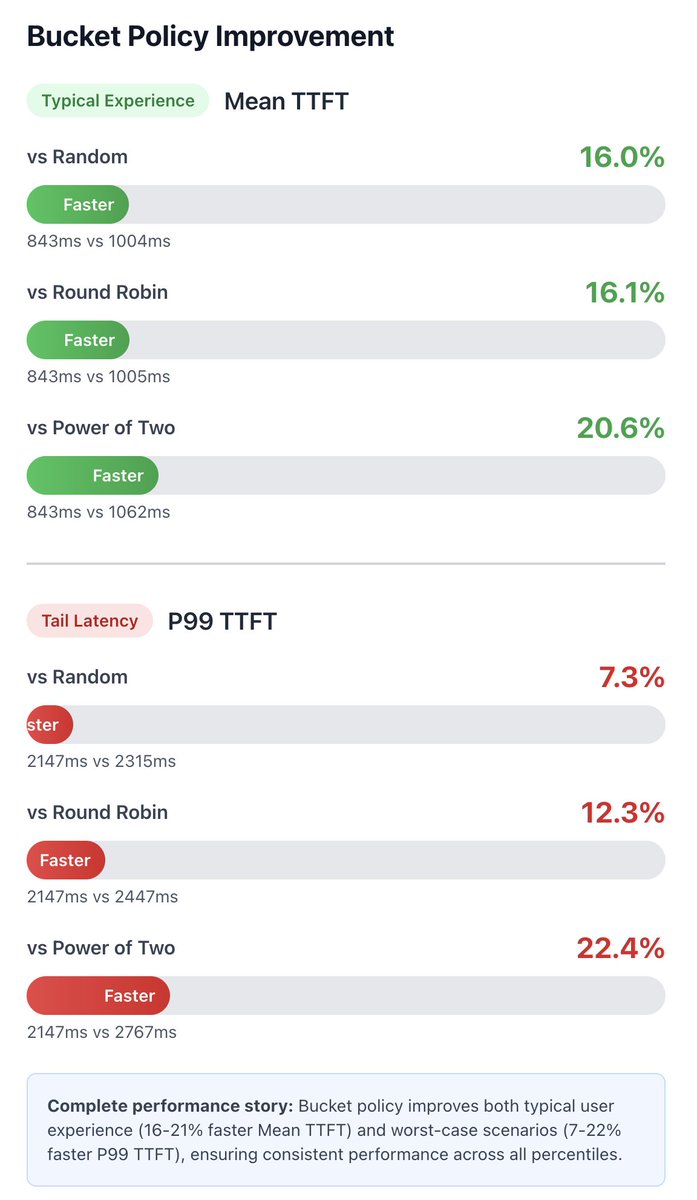
⚡️ Faster responses: New bucket-based routing brings up to 20-30% improvements in TTFT (Time To First Token) and overall throughput
🧠 Smarter function & tools: MinMax M2 function calls & reasoning; Streaming parsing with Tool Choice in chat completions API; Tool_choice support for Responses API
🚪 Better chat history management: Flexible chat history management with the storage backend you want (PostgreSQL, OracleDB, in-memory storage). Choose the database solution that best fits your infrastructure and scale requirements.
See more in the thread ⬇️
🚀 SGLang Model Gateway v0.2 Drops 🚪
SGL-Router pioneered cache-aware routing last year. Now, it is fully rebuilt and renamed as “SGLang Model Gateway” - with extreme performance and much more features.
Core upgrades:
- Multi-Model Inference Gateway (IGW) Mode: Run multi-model fleets under one gateway—custom policies, health checks, load balancing, and flexible prefill-decode disaggregation.
- Rust gRPC Powered: Bypass slow Python and HTTP runtime, extreme fast streaming, OpenAI-compatible APIs, cached tokenization! 🔥
- Pluggable Storage & MCP: Flexible history (memory/oracle) + seamless tool integration + response API.
- Reliability Boost: Retries, metrics, tracing—all in.
Your unified control plane for reasoning agents & enterprise LLMs. Backward compatible—easy migration!
This is a huge contribution from the @Oracle team, led by Simo @hello_slin, Chang @ccskookie, Keyang @key4ng.
Hi, vLLM team, please stop posting these misleading benchmark results. Both sglang and trtllm can achieve much better numbers than the ones in your post.
See the reproduced runs of sglang:
https://t.co/HKcaAZeR5f
This isn’t the first time you’ve shared misleading information, if you recall. You might consider deleting the post to protect your reputation.
Last time:
https://t.co/LXWln1xVE8
Your acknowledgment of last misleading argument:
https://t.co/OTgvn6d7vL