Just set up EurekaClaw locally in 60 secs — open-source AI research agent that goes from conjecture to LaTeX paper. Here's what caught my eye:
• One curl command install, Python venv, done
• Plugs into Anthropic, OpenRouter, Ollama, or any OpenAI-compatible API
• 7-stage proof pipeline: plan → decompose → prove → verify → assemble
• Builds a memory + skills system that improves across sessions
• Outputs full LaTeX papers with theorem environments and citations
curl -fsSL https://t.co/N8JbA1jPpj | bash
Apache 2.0, local-first, privacy by design. This is what AI-for-science tooling should look like.
https://t.co/HUe7gizr4p
AI coding agents may be amazing for simple tasks:
+290% productivity gains for individual files.
But the product-level is a totally different story:
AI-created app releases have spiked but zero usage uptick and flat reviews.
Writing code is not the same as shipping software!
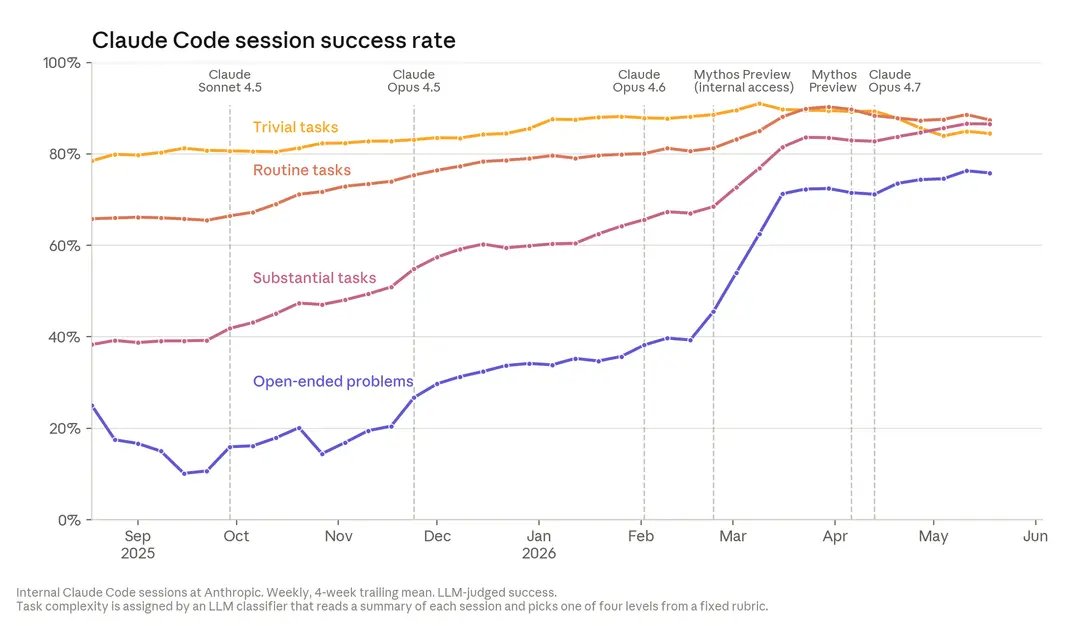
Open-ended coding work is where the curve matters: Claude went from struggling with ambiguity to solving roughly three quarters of these sessions in under a year.
When Claude starts building Claude: Anthropic's new Recursive Self-Improvement piece is worth reading closely:
• AI task horizons are reportedly doubling roughly every 4 months
• >80% of Anthropic’s merged production code is now Claude-authored
• Code output per engineer is up ~8x vs 2024
• Claude’s success rate on open-ended coding tasks hit 76% in May 2026
• In one benchmark, model optimisation jumped from ~3x to ~52x in under a year
• Human review is becoming the bottleneck: Amdahl’s law, but for organisations
• The key remaining gap is "research taste": choosing which problems matter and which results to trust
Recursive self-improvement does not mean magic. It means the AI lab becomes a loop: models write code, run experiments, evaluate results, and increasingly help build the next model. The question now is not whether AI can type faster than engineers. It is whether humans can still supervise a virtual lab running at compute speed.
https://t.co/squuglV7mG
🚨 Just found the cheapest always-on cloud VM on the market, and it's hiding inside a Mule 🫏 @mulerun_ai
MuleRun Computer hands every paid user a private, always-on virtual machine in the cloud, and the pricing is great:
The $16/mo Plus tier (billed yearly) gets you a 2-core / 4GB / 40GB box plus 2,000 monthly agent credits, the unit you spend to run tasks, priced at $1 = 100 credits. Super is $32/mo for 4 cores / 8GB and 4,500 credits; Pro is $160/mo for 8 cores / 16GB and 23,000 credits.
Now compare the bare metal: a 2-core/4GB instance runs $24/mo on DigitalOcean and $20/mo on Linode, with zero compute credits attached.
MuleRun undercuts both and throws in the agent on top. For an always-on personal agent, the VM is effectively a free add-on.
👉 https://t.co/PnSPEtdXkY
The Class of 2026 is the first cohort employers are hiring for their AI skills — and the first whose entry-level jobs AI is quietly deleting. 22% feel "very prepared," more than any older group; recent-grad unemployment sits at 5.6%.
The twist buried in the data: employers now rate critical thinking above AI literacy. One professor has students submit their chatlogs for grading — marking up the prompts, not just the output.
The skill isn't using the tool. It's knowing when it's wrong.
Qwen3.7-Max is a real milestone for Chinese AI.
On Code Arena, Alibaba's latest model is now being ranked in the same top coding tier as Claude and ahead of several frontier models from OpenAI, Google, Zhipu and Moonshot.
What matters is the method: blind human comparisons of real code outputs, not just synthetic benchmark flexing. You can see the live Code Arena coding leaderboard here: https://t.co/bpokNehKL0
LLM Stats coding leaderboard tracks performance across practical tasks like React apps, games, data viz, 3D scenes, SVGs and animation. That’s much closer to how developers actually use these models.
The takeaway: the US still leads the top of the AI coding stack, especially via Anthropic. But the gap is no longer uncontested. Qwen, DeepSeek, GLM and Kimi show that Chinese labs are now competing across the frontier — not as copycats, but as serious model builders.
For developers, that’s good news: more competition, more API options, and faster pressure on price/performance.
Code Arena updated its rankings today. Alibaba's Qwen3.7-Max scored 1541, placing it above GPT-5.5, Gemini-3.5-Flash, GLM-5.1, and Kimi-K2.6. Only Claude Opus 4.7 and 4.6 rank higher. By vendor, Alibaba now ranks #2 globally.
Two things worth noting.
First, Code Arena is not a traditional benchmark. Developers submit real tasks. Models generate full, interactive web applications from scratch. Users then blind-vote on the results. It is one of the more credible measures of vibe coding ability available today.
Second, Qwen3.7-Max is designed as an agent foundation model. Long-horizon task execution and tool calling are core to its architecture. Alibaba says the model can sustain over 1,000 tool calls across 35-hour task sessions. Code Arena's format, building complete apps rather than solving textbook problems, aligns with that design. The score and the product thesis match.
Claude has held the top of this leaderboard for months. Qwen3.7 is the first Chinese model to crack into that tier. A notable data point for anyone tracking the global coding model race.
Anthropic is reportedly paying SpaceX $1.25B/month for compute through May 2029 - roughly $45B in total.
Annualized, that one contract alone would rank SpaceX as roughly #5 cloud infrastructure provider in the world — ahead of Oracle, behind only AWS, Azure, Google, and Alibaba.
This is not a cloud bill. It's an industrial dependency.
https://t.co/bdEa2KXnHZ via @FT
European AI may still trail the US and China in scale, but the momentum is becoming hard to ignore.
Germany, France, the UK, Sweden and the Netherlands are now producing serious AI contenders across:
• foundation models
• defense AI
• developer tooling
• automation
• autonomous driving
• biotech
Europe is finally building an AI stack of its own. 🇪🇺
@ivylala Giving an AI agent real-time access to WeChat & RedNote’s high-signal AI/tech content sounds amazing. Would be interesting to run a comparative analysis. the claim that WeChat AI writing is better than for example Claude Opus 4.7 is a pretty bold claim!
Does the workplace AI revolution have a trust problem?
• 69% worry about AI-driven job losses
• 57% think AI will eliminate more jobs than it creates
• 65% say the gains will mainly flow to wealthy investors and big companies
The question is no longer whether AI will transform work.
It is who gets replaced, and who captures the upside.
👉https://t.co/mGqKk1ZpPa
AI video is not just a model race. It is a data race.
Chinese labs have vast short-video platforms feeding training data and feedback loops that US rivals struggle to match.
With Sora discontinued and Seedance/Kling climbing the rankings, the lesson is blunt:
Data rules.
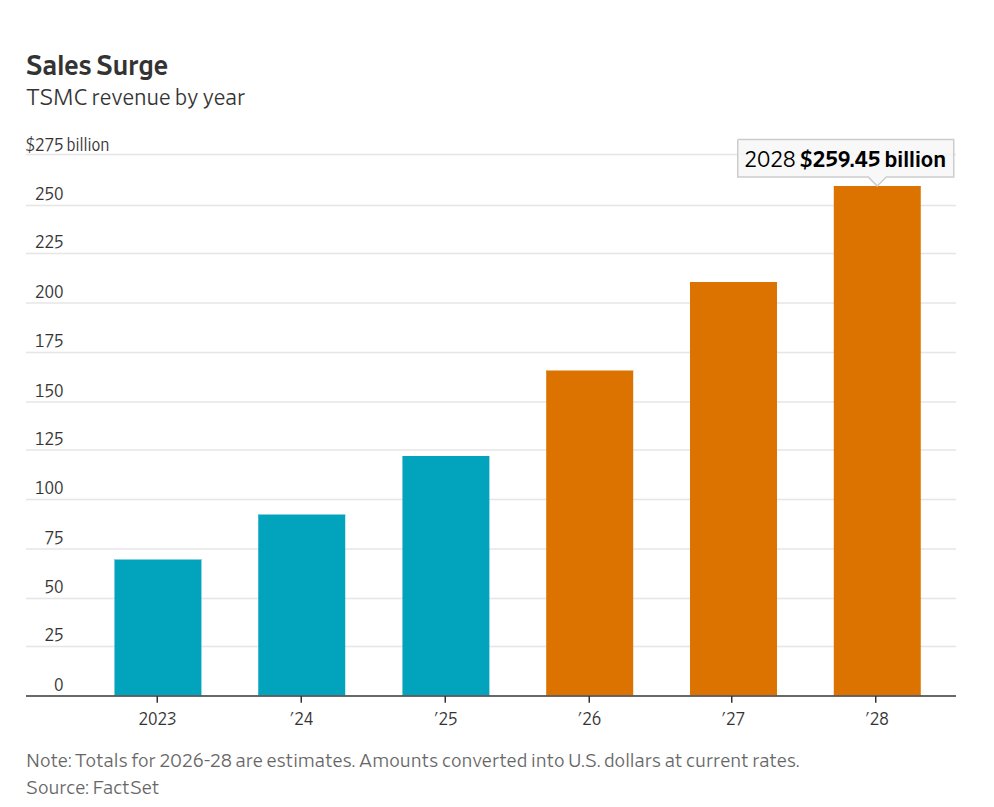
Be TSMC.
While everyone debates Nvidia, AMD, Intel and AI agents, TSMC quietly sits at the heart of the AI boom.
Microsoft, Meta, Alphabet & Amazon plan $725B in capex this year. Most of it eventually flows through TSMC's fabs.
→ Gross margins: 66% (up from 59% a year ago)
→ Revenue growth guide: 30%+ this year
→ Nvidia's chip commitments: $95B — up from $16B two years ago
→ Trades at 21x forward earnings vs. 26x for the sector
Not flashy, but pretty much indispensable.
👉https://t.co/wA26Sv1lQn via @WSJ