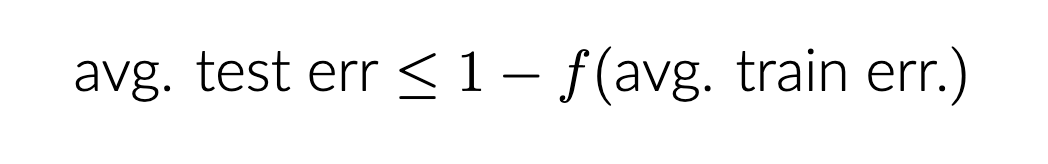The NeurIPS position paper track was flooded with submissions that substantially used AI. More than other tracks, and despite a requirement otherwise.
I appreciate the chairs' strong action. People are not entitled to reviewers' time, AI makes it exceptionally easy to waste it.
A Gaussian mechanism with ε = 6 can be less private than one with ε = 8. This points to a problem with how we report privacy guarantees in machine learning. A thread 🧵
Here's an example for a specific instantiation of DP-SGD in terms of f-DP trade-off curves (an equivalent operational version of privacy profiles). As we see, a non-asymptotic GDP trade-off curve fits the DP-SGD trade-off curve almost exactly.
We've built a new Python package gdpnum to compute non-asymptotic GDP guarantees and estimate their precision for many practical algorithms:
https://t.co/fYyG6gU8Yn
Many ML algorithms, especially those involving many compositions like DP-SGD, can be very precisely characterized with GDP. This is a *non-asymptotic* result, not just a central limit approximation!
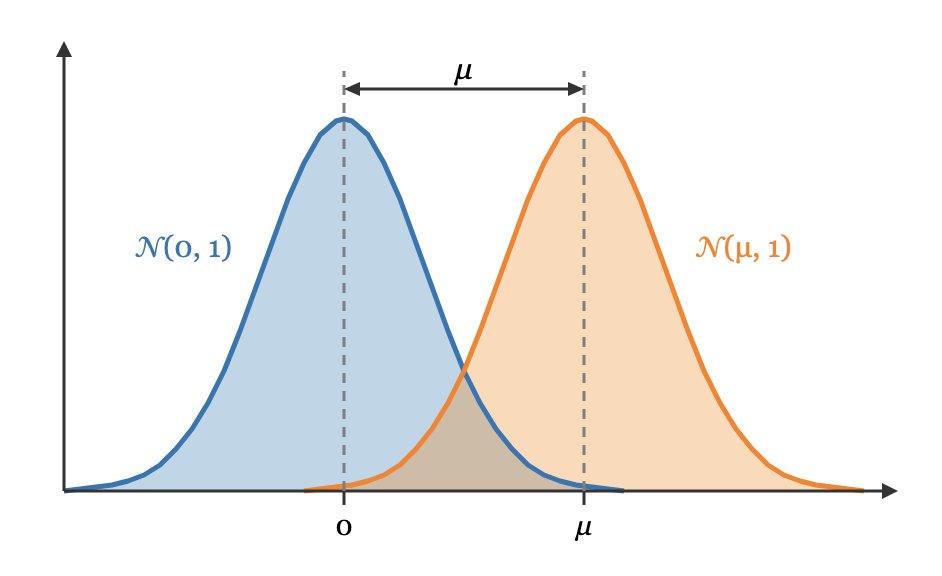
GDP characterizes the entire privacy profile ε(δ) of a Gaussian mechanism exactly using a single number μ. Interpretation: if a mechanism satisfies μ-GDP, then running membership inference against it is as hard as distinguishing N(0,1) from N(μ,1) based on a single observation.
A Gaussian mechanism with ε = 6 can be less private than one with ε = 8. This points to a problem with how we report privacy guarantees in machine learning. A thread 🧵
Issue 2: You can't properly compare two mechanisms by ε if their δ values differ. A Gaussian mechanism with ε = 6 at δ = 10⁻⁵ is less private than one with ε = 8 at δ = 10⁻⁹. This is because you cannot properly compare ε if δ is different.
No attacker in the universe can achieve that 98% rate: It's purely an artifact of compressing the entire privacy profile into one pair (ε, δ). My colleagues and I detailed on this problem in detail in this NeurIPS'24 paper:
https://t.co/LKeW48wMx1
Issue 1: A single (ε, δ) pair can massively overstate privacy risk. Example: DP-SGD with ε = 8 at δ = 10⁻⁵ suggests a worst-case membership inference accuracy of ~98% using standard conversions. But using the full privacy profile, the actual maximum is only ~68%.
The standard way is to report is to use a single (ε, δ) pair for a small δ. The community has developed informal conventions, e.g., ε < 10 is generally considered OK in privacy-preserving machine learning. But this convention has two big issues.
New paper at #NeurIPS2025!
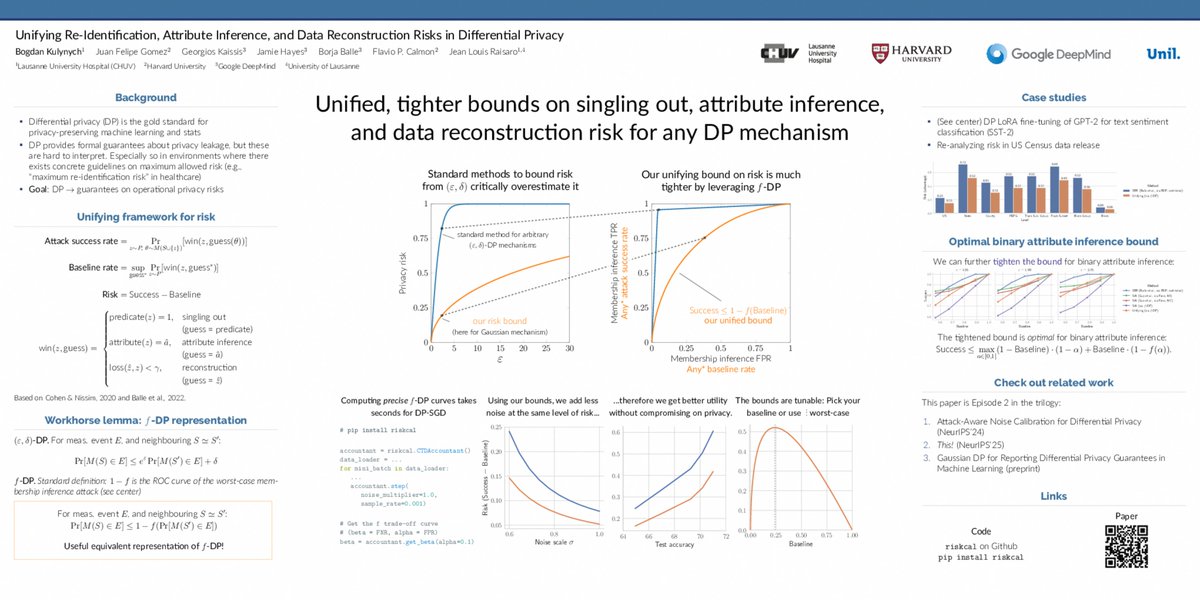
"Unifying Re-Identification, Attribute Inference, and Data Reconstruction Risks in Differential Privacy" in which we derive unified, tighter bounds on operational attack risks for any DP mechanisms, using f-DP.
Link: https://t.co/aWzFBHzhzC
Thread👇
Continuing the thread on "Unifying Re-Identification, Attribute Inference, and Data Reconstruction Risks in Differential Privacy", for some reason it got borked.
https://t.co/C2GVF57k6M
New paper at #NeurIPS2025!
"Unifying Re-Identification, Attribute Inference, and Data Reconstruction Risks in Differential Privacy" in which we derive unified, tighter bounds on operational attack risks for any DP mechanisms, using f-DP.
Link: https://t.co/aWzFBHzhzC
Thread👇
Very excited, and I think this will be quite useful for practical deployments of DP.
This is a joint work with great Felipe Gomez ( https://t.co/Gf5PzlyllA ), George Kaissis, Jamie Hayes, Borja Balle, @FlavioCalmon, JL Raisaro.
Continuing the thread on "Unifying Re-Identification, Attribute Inference, and Data Reconstruction Risks in Differential Privacy", for some reason it got borked.
https://t.co/C2GVF57k6M
New paper at #NeurIPS2025!
"Unifying Re-Identification, Attribute Inference, and Data Reconstruction Risks in Differential Privacy" in which we derive unified, tighter bounds on operational attack risks for any DP mechanisms, using f-DP.
Link: https://t.co/aWzFBHzhzC
Thread👇
Another (final) finding. The unified f-DP bound extends to a form of a generalization bound. Given that we can compute f-DP curves precisely, this is likely the tightest generalization bound applicable to deep learning, but it is only for on-average generalization unfortunately.