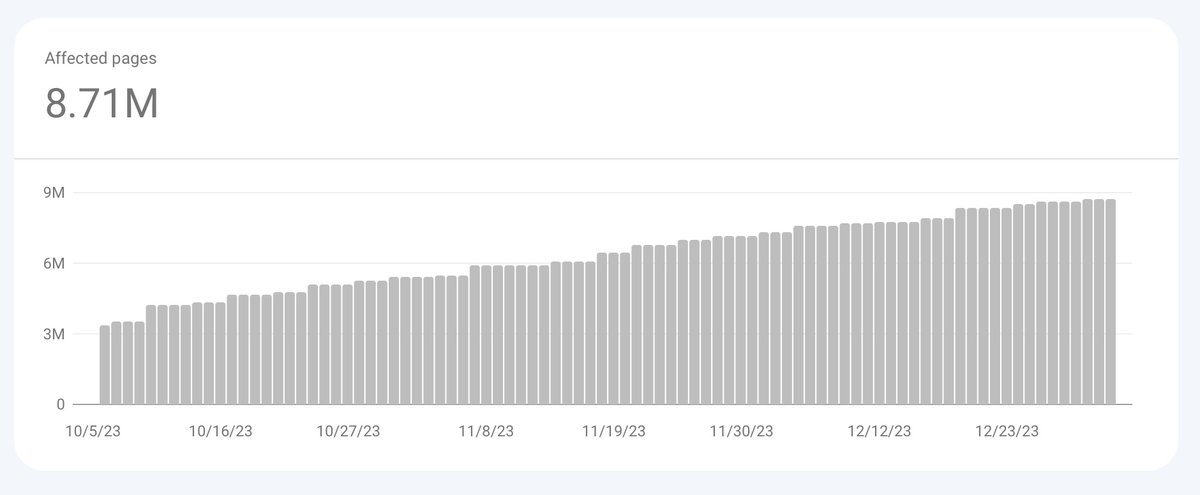
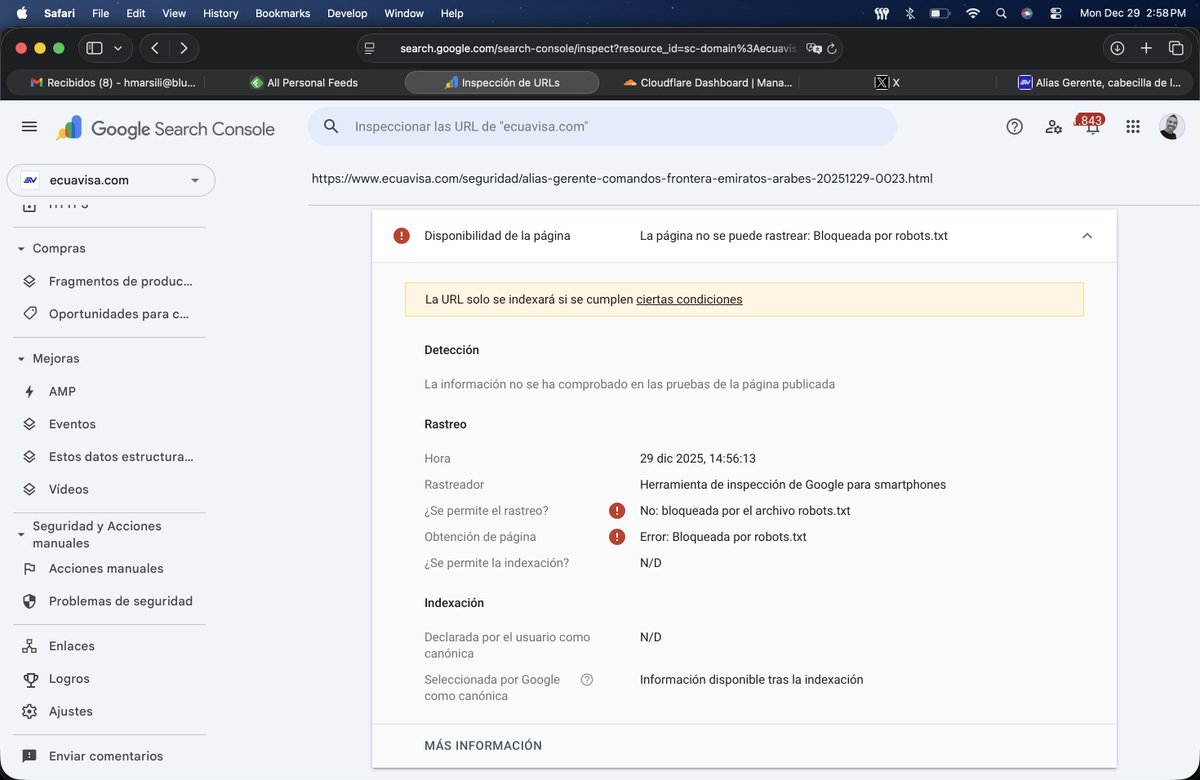
@searchliaison SITE NOT INDEXING. A couple of hours ago, we migrated a site. For 60 seconds the robots.txt had a DISALLOW but now is OK (it's been 6 hours) https://t.co/RYqz0Tl2az. SC says it's correct but no content is indexing due to a robots.txt BLOCK. Can you help?
Hi @googlesearchc@searchliaison Does blocking google-extended on robots.txt prevents a site from appearing on the IA overviews? I look it up on the newly published IA documents and did not found a definite answer. CC @JohnMu 😀
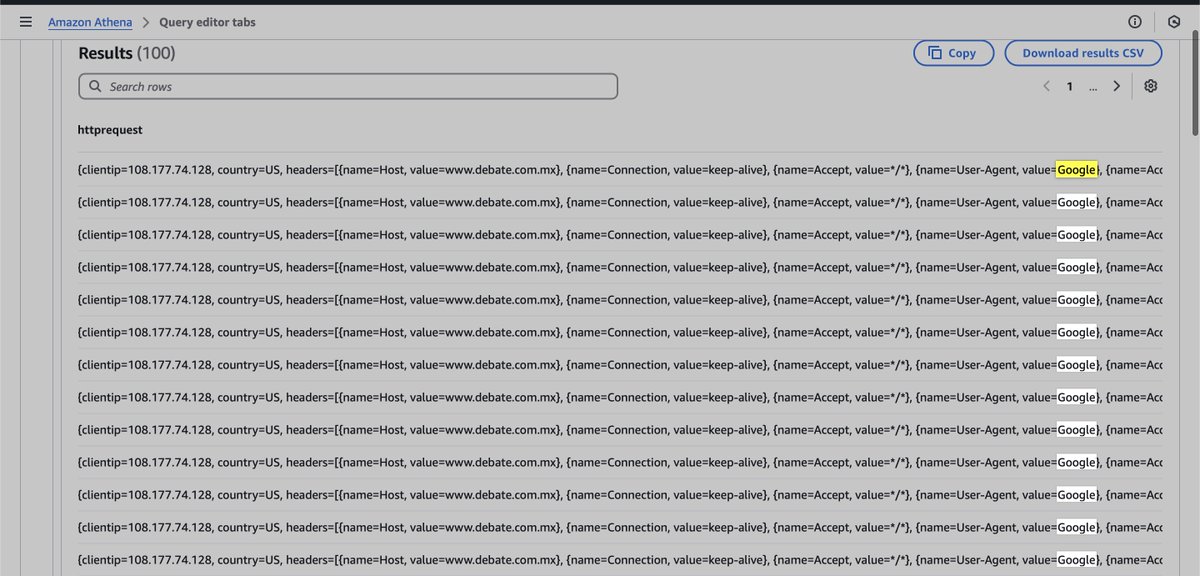
@googlesearchc@searchliaison@JohnMu @rustybrickwe are noticing increasing traffic to our sites from IPs resolving to https://t.co/IaiPg5SYQ0 (seems legit) with an odd UA. Just 'Google' (which does not seems legit). The IPs are not in any of the validation json files. Ideas?
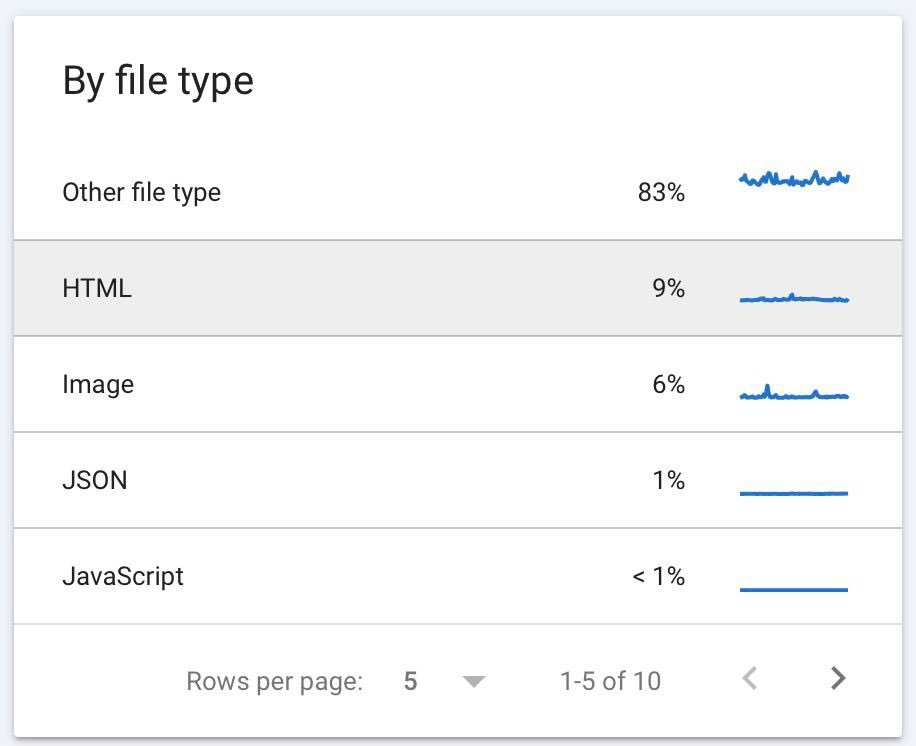
@glenngabe Interestingly the HTTP caching only mentions that Googlebot caches CSS and JavaScript resources but it does not seem to be caching fonts. Inside OTHER: is 99% font requests with 200 OK that could be cached.
Also, on some sites using external fonts we see Google crawling stats at 80% with other and inside, it’s all FONTS. Does googlebot caches Fonts? Or only CSS / JS?
Hi @JohnMu@googlesearchc we are getting advice from some SEOs to serve a 200 OK code to Google instead of 304 NOT MODIFIED for content that has not changed. The idea is to make Googlebot to reprocess. Is there any value behind this? My take is we will be burning crawl budget.
@JohnMu@searchliaison SIGNED EXCHANGES (SXG). Is it dead or is tech worth investing in? We did some testing using SXG to ditch the AMP version. I don’t see much activity on the forums and repositories.
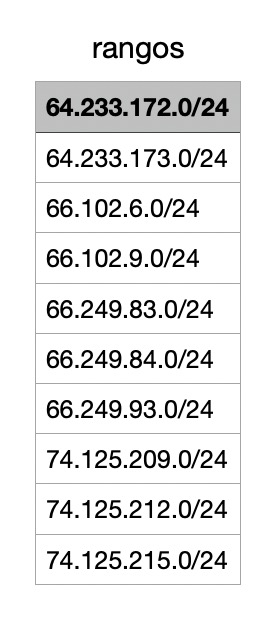
Hi @JohnMu@searchliaison you might want to take a look at the Special Crawlers JSON https://t.co/UqxqKqIQ3f. I think there is an active IP range missing from the file: 142.250.32.0.
142.250.32.37
https://t.co/HLuOB1UEEd.
Is resolving to https://t.co/HaBKABmqH9. Looks legit.
Feliz año a todos.
Así cerramos el 2003 en @ELDEBATE, siendo el 5to medio más leído en México, gracias a la preferencia y confianza de nuestros lectores.
Gracias también al equipo de profesionales de la información que trabaja 24/7 en Sinaloa y en las principales ciudades de Mx.
Hi @JohnMu@googlesearchc we have a site getting MM of indexing requests from GOOGLEBOT for pages that doesn't exists. Site owner is concern about the volume of 404. Apparently, aggregators generated pages linking to random URLs. Is this bad for the site? How we can stop it?
#BluestackCMS#BrixWireNewsHub#latinoamérica
Estamos muy contentos de compartir la integración entre @cmsmedios y @BrixWire
📌Queremos celebrar esta unión con una oferta especial, además de una promoción Early Bird. Todos los detalles en el post:
https://t.co/xJW3Hmaf5e
@JohnMu I can CONFIRM all this ranges (or at least some) which are not on the JSON files (none of the 3) are legit Google services. In this case, GOOGLE SHOWCASE. If this gets blocked, SHOWCASE does not work.
@JohnMu@googlesearchc. On this official doc https://t.co/ltSX44FsKj FeedFetcher should be getting RSS files from rate-limited-proxy-***-***-***-***.google.com. We have hundreds of requests from Google IPs (not on the json) from google-proxy-**-***-***-***.google.com. Fake?
@JohnMu@googlesearchc Hi, I did a little more digging. Could all this traffic from google-proxy***.google.com with UA GoogleProducer and Feed-Fetcher be related to this? https://t.co/O4F0XweWtp . Google trying to generate previews of the content... ???
@JohnMu@googlesearchc actually we are seeing requests from both GoogleProducer and FeedFetcher from google-proxy. GoogleProducer is consuming ARTICLES. Is that ok? I assumed it only consumes feeds from publisher center.