@mattmireles PowerInfer 1, the open-sourced code, works on Apple Silicon with CPU only. We are progressing on GPU support and adopting the method in this work where applicable. Stay tuned!
🚀 Excited to introduce PowerInfer-2: A game-changing LLM inference engine for mobile devices by the #PowerInfer team. It smoothly runs a 47B model with a staggering 29x speedup on smartphones! Watch our demo to see it in action! 🎥
Technical details at: https://t.co/7bx5EnzWCs
@canav4r@vimpunk We expect this method to work well on other mobile platforms, but the current testing machines best fit our requirements for large RAM, high-speed flash, and NPU. It’s only a demonstrative implementation and we have no preference on the hardware.
@IlyasHairline We’ve included the predictors into transformers model weights and you can train them end-to-end now. We found it more efficient to co-train instead of training the predictors offline.
@IlyasHairline@wey_gu If the foundation models use these activation functions and are pretrained from scratch, it would be ideal. We have demonstrated their negligible loss/perplexity compared to SwiGLU, but the trained model exhibited very sparse FFNs in TurboSparse paper and https://t.co/IJo4jjb7Hm
👐 PowerInfer-2 will be open-sourced based on the PowerInfer repo. We’re refining it to untangle from our testing platform and making it accessible on PCs for the community. Open-sourcing will happen in stages starting soon. Stay tuned for updates at https://t.co/eQYqe8hHGm
🔓 The power of cloud-scale models and local privacy isn't mutually exclusive. We're pioneering to bring LLM's incredible capabilities directly to your device without compromising privacy. Explore how we're making AI accessible to everyone, everywhere: https://t.co/jYXhmuGZmi
@wey_gu The method we proposed in TurboSparse enables us to sparsify a mainstream foundation model within 150B token (5% of pretraining). The continuous training of Mistral and Mixtral costs us less than $0.1M. We hope other researchers found it a nice trade😎
@wey_gu Those ground-breaking speedups are all based on intrinsic sparsity and depends on ReLU more or less. We have confirmed some alternatives, like ReLU^2, and dReLU proposed in TurboSparse. They are very promising but not adopted by mainstream LLMs yet. Retraining is still essential
@lin72h MoE is the highlight, but it also applies to other LLMs. For a Mistral-7B level model, it can save nearly 40% of memory while achieving the faster inference speed than SOTA
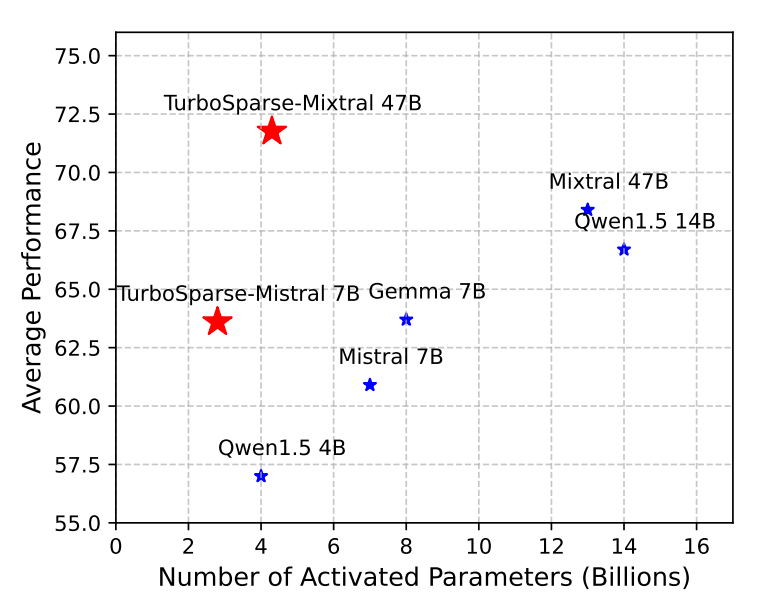
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
- Proposes a novel dReLU function, which is designed to improve LLM activation sparsity
- 2-5× decoding speedup
model: https://t.co/UEoBgMxceD
abs: https://t.co/yc9ZAhPokt
Thrilled to unveil Bamboo-v0.1: A groundbreaking 7B LLM by the #PowerInfer team, matching Mistral's performance with 85% activation sparsity. Built on Mistral's weights, supercharged with dReLU for up to 4.38x hybrid computing speedups. Discover https://t.co/jhFnVL50BH.
🌟PowerInfer boosts LLM serving speeds by up to 11x on consumer-grade GPUs! Inspired by our Deja Vu paper (ICML'23 https://t.co/FideE69lEl), it serves ReLUified LLMs, keeping heavy hitter (hot) neurons in GPU and offloading sparsely fired ones on CPUs.
Proud of my undergraduate/master alma mater SJTU (Shanghai Jiao Tong University) for this work!
https://t.co/crCxjKrk0Z