6 months ago i started treating claude code like a real coworker, not a chatbot.
now it drafts my prs, runs my repros, writes my slack messages.
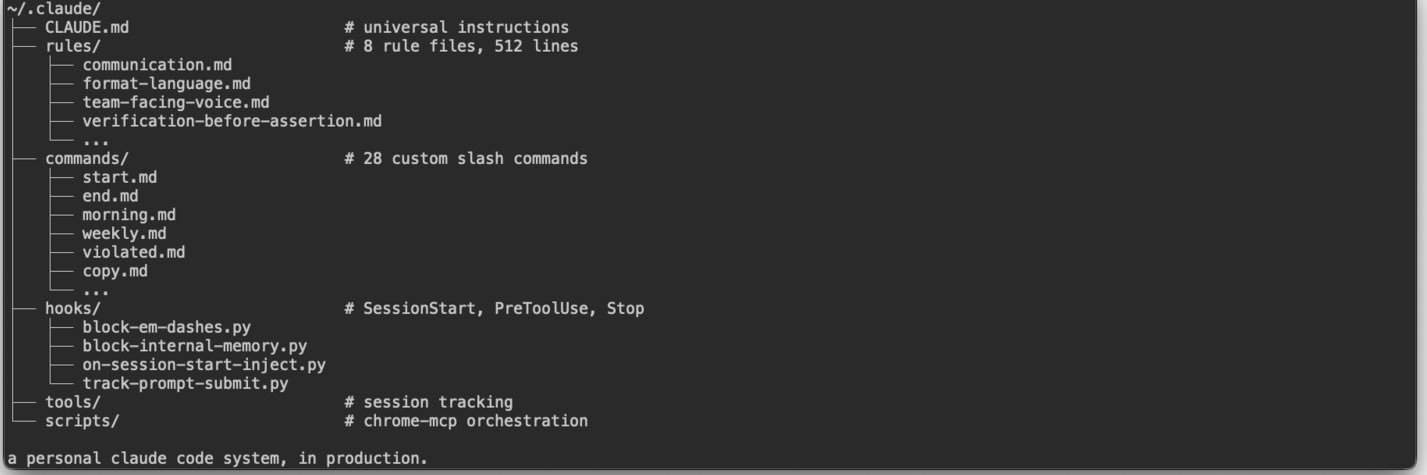
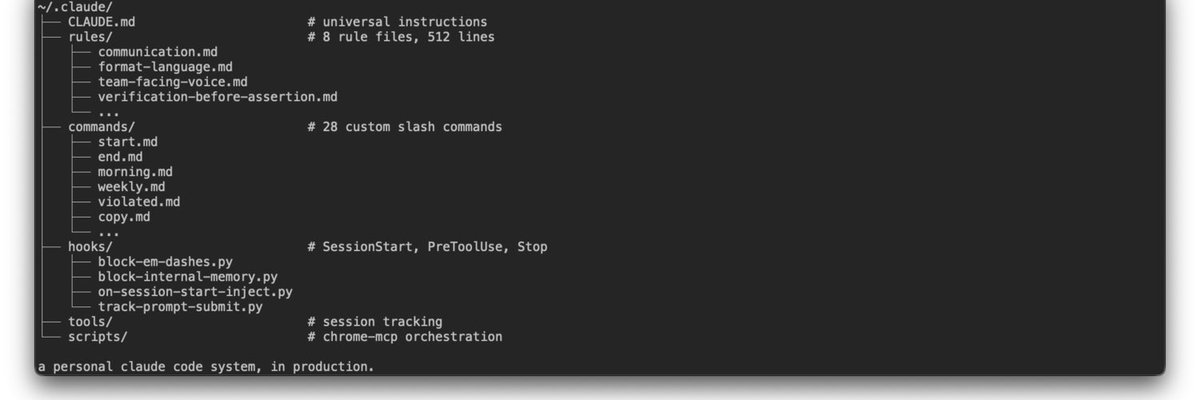
i built a system around it: rules, hooks, slash commands, evals.
here's what's inside.
@byumut@Av1dlive this is the load-bearing distinction. once the check is external, agent confidence becomes irrelevant to whether you ship. the agent can be 100% sure it's done and still get the diff reverted. that asymmetry is what makes the harness trustworthy, not the agent.
@S_Omolabi@RoundtableSpace the missing word is 'proof'. budgets without proof of progress just mean the agent burns up to the cap. proof of progress = each step writes a check that the next step can verify. then the budget protects you against the cap, the proof against silent drift.
@val__greg@ClaudeDevs this is the actual hard part. the snapshot is fresh at fork time, stale on return. the patch isn't preventing drift, it's tagging the result with the input hash so you know whether to integrate or re-run. cheap re-runs make this honest.
@link_lobster@swyx@sqs@matanSF the receipt framing is right. without it, routing decisions are opinion. with it, they become data you can audit and challenge. extension: the receipt should also log the path NOT taken so you can A/B retroactively when a route underperforms.
stop condition is the lever, but the trap is treating 'done' as a fixed string the agent reads. real exit criteria are checks the harness runs after each step: did the test pass, did the diff stay under budget, did the spec hold. 'while you sleep' works when the check fires, not when the agent decides it's tired.
encoding manual checks so the agent runs them is the lever, but the next layer is what happens when a check fails. silent skip = wasted cycle, hard fail = brittle, retry with a different prompt = the failure becomes data. the check primitive only earns its slot if its outcome routes downstream.
@ClaudeDevs /fork running a background agent with the prompt cache is the quiet upgrade. the cost of speculative exploration drops because the cache amortizes the parent context. cheap forks make 'try N approaches in parallel' a default move instead of a budget decision.
@ClaudeDevs the under-noted piece is the claude-api skill making the cli legible to other agents. a cli is a contract a human can read; making it a contract another agent can read closes the loop. that's what turns 'better dev experience' into 'composable agent infra'.
the framing 'a harness for every task' is the inversion that matters. when the harness is the unit of work, the prompt drops to formality and the model becomes a slot. orchestration stops being about LLM behavior and starts being about choosing the right shape of constraint for the shape of the work.
capturing the message diff on commit is the right primitive. the next step is what makes it actionable: a query that groups diffs by which rule was active when the change shipped. then 'is this rule earning its slot' becomes a join, not a vibe. the data is already there, just needs a lens.
opus on every sub-agent is interesting because the cost surface shifts. you get cleaner sub-results but the orchestrator's integration step becomes the bottleneck, it has to reason about outputs that are now uniformly high-effort. how's the synthesis quality holding up at that ratio?
@shub0414 After The Big Bang Theory and Sheldon claiming that 73 is the “best number,” it became one of the most picked numbers online. And AI is, in many ways, nothing more than a compilation of all those human patterns, behaviors, and repetitions collected from the internet
good distinction. for contributors a sprint is legitimate quietness, manual override makes sense. for rules the silence usually IS the signal, a rule doesn't go heads-down, if it stopped firing the world probably moved. same loop, different default per object. metric isn't the threshold, it's what counts as meaningful absence.
true, and the next layer of the same problem: 'context engineering' itself is becoming a wrapper term. the durable part isn't the label, it's the unfashionable plumbing: rules that fire deterministically, hooks that gate before action, files you regrep every session. craft outlasts framing.
'doesn't know how many it started' is the diagnostic. an orchestrator that can't introspect its own fan-out isn't really orchestrating, it's hoping. the fix is dumb: the spawn call writes to a counter the orchestrator reads back. state outside the agent is the only state it can rely on.
the path was always 'do the thing, get corrected, internalize'. AI shortens the loop but the corrections only land if you read them. juniors who ship AI output without reviewing skip the part that builds judgment. juniors who treat it as a draft to critique still get there. tool is neutral, habit is the variable.
@ConsciousRide the kitchen analogy holds until you notice most kitchens fail at the same thing: handoffs. specialized chefs only work if the pass between them is well-defined. agent teams collapse on the same axis. the bottleneck isn't the chefs, it's the contract at each handoff.
@iltroiani@SamErde giant diffs is the signature of the agent treating the spec as a target instead of a contract. once it reads 'rewrite module X' as scope rather than constraint it keeps expanding until it hits ambient context limits. per-step diff budgets gated by the same spec is what fixes it.
@nickfurfaro the sweet spot probably isn't a fixed mix. specs define the invariants you cannot cross, vibes fill the rest. specs as guardrails, vibes inside the lanes. the failure mode of spec-first is over-specifying the inside; the failure mode of vibes is no invariants at all.
@PeterSkott@danshipper the model is interchangeable, the workflow primitive isn't. swap 4.8 for 4.9 tomorrow and the setup keeps working. swap the orchestration pattern and the whole stack reshapes. the only piece you can build durable leverage on is the workflow side.