Excited to show our latest attempt at a clinically meaningful clinical cancer genome with rapid turn around (24 hours!) times using Oxford Nanopore sequencing technology for patients who need a rapid, whole genome assessment of their tumour and germline, offering them (1/n):
This month's Research Seminar will take place on Tuesday, 25 June from 2 to 3pm. We'll be hearing from Research Network member Professor Rajesh Thakker, and Genomics England Genomic Data Scientist Rowan Howell 🔬
Register for free via this link: https://t.co/JjPH9FYPXe
Long-read sequencing of an advanced cancer cohort resolves rearrangements, unravels haplotypes, and reveals methylation landscapes https://t.co/fT0UlknAOv #medRxiv
Interestingly, assembly-based methods are superior for SV calls but are inferior to read-based methods for SNV and indel calls. Clear improvements in indel recall also seen for ONT R10 chemistry versus R9! #longreads#genomics
To gain acceptance in clinical practice, long read sequencing technologies must demonstrate both their unique advantages and their ability to call variants with the same accuracy as the currently employed short read technology.
In this paper, the authors test the accuracy of variant calling with ONT and PacBio reads across a range of sequencing depths and using a variety of tools.
In this paper, the authors show that long read sequencing can be used to study a wide variety of structural alterations involving telomeres in cancer cells, which could not be resolved using short read sequencing. #longreads#genomics#cancergenomics
Telomeres are repetitive sequences that cap the end of our chromosomes and are frequently altered in cancer cells. The repetitive nature of telomeres makes them difficult to analyse with short read sequencing.
In this paper, the approach used to build the human T2T reference (a combination of PacBio and ultra-long Oxford Nanopore reads) was used to characterise the X and Y chromosomes of great apes. These new assemblies were used to study evolution of these ape chromosomes. #longreads
A major achievement of long read sequencing has been the telomere-to-telomere (T2T) reference genome. Long read sequencing is capable of characterising highly repetitive regions of the genome such as telomeres and centromeres which were missed from earlier reference genomes.
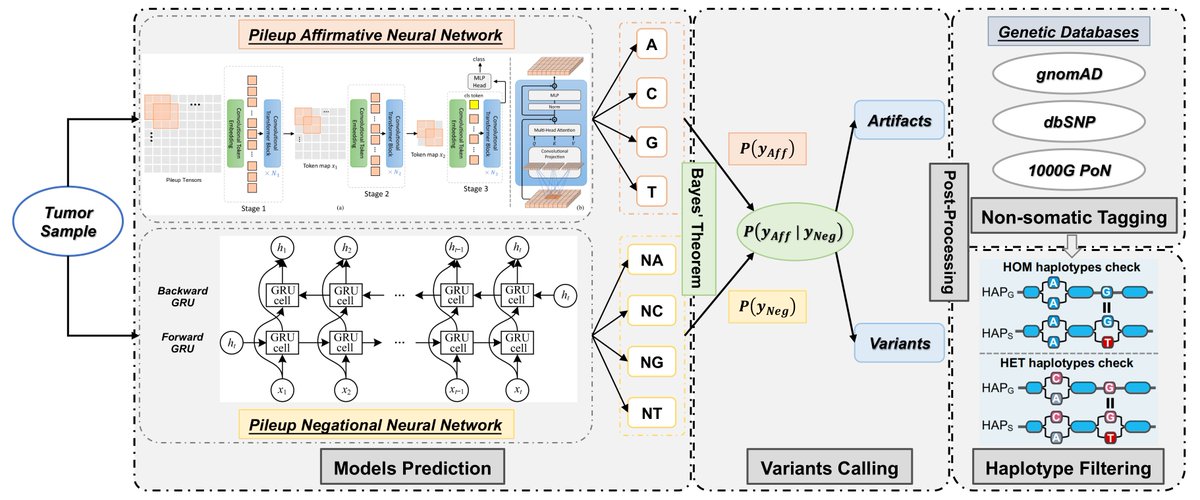
Releasing the first version of ClairS-TO, a long-read tumor-only somatic SNV caller ⚙️https://t.co/13G8KXYr4U. Please give it a try and send me comments and critiques. Using it, ONT long-read can do tumor-only somatic SNV calling with performance similar to Ilmn short-read. 1/
In this paper the authors describe a tool to accelerate the process of mapping long reads, achieving >50% reduction in time for ONT data. #longreads
Alignment of reads from sequencing data to a reference genome is currently a near-ubiquitous stage in analysis and for long read data this is usually performed with minimap2.
It's an exciting time for long read sequencing with awesome new methods and applications coming out all the time! I will be posting my pick for the paper of the week to highlight the exciting research happening in this field.
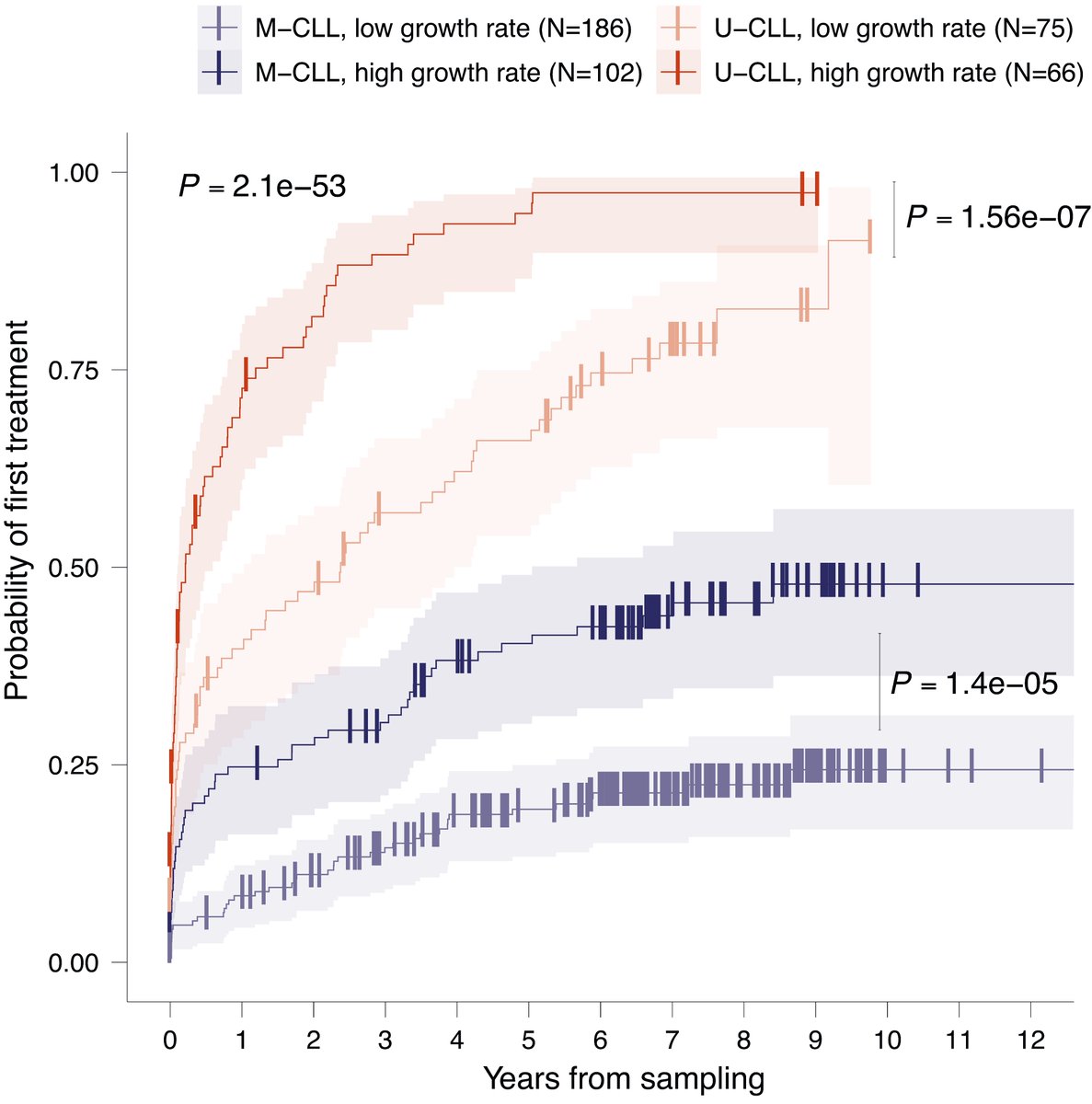
Does the evolutionary history of a cancer predict outcome? In our pre-print, we introduce a new method to measure a cancer’s past using bulk methylation data. In chronic lymphocytic leukaemia (CLL), these inferred histories are highly prognostic! (1/9)
https://t.co/PKj6ycRpIL