Next-Edit is live in Kilo, powered by Mercury Edit 2 from @_inception_ai.
Autocomplete predicts the next few tokens ahead of your cursor. Next-Edit predicts your next actual edit anywhere in the file. Hit Tab to accept.
And it's free for everyone for 30 days!
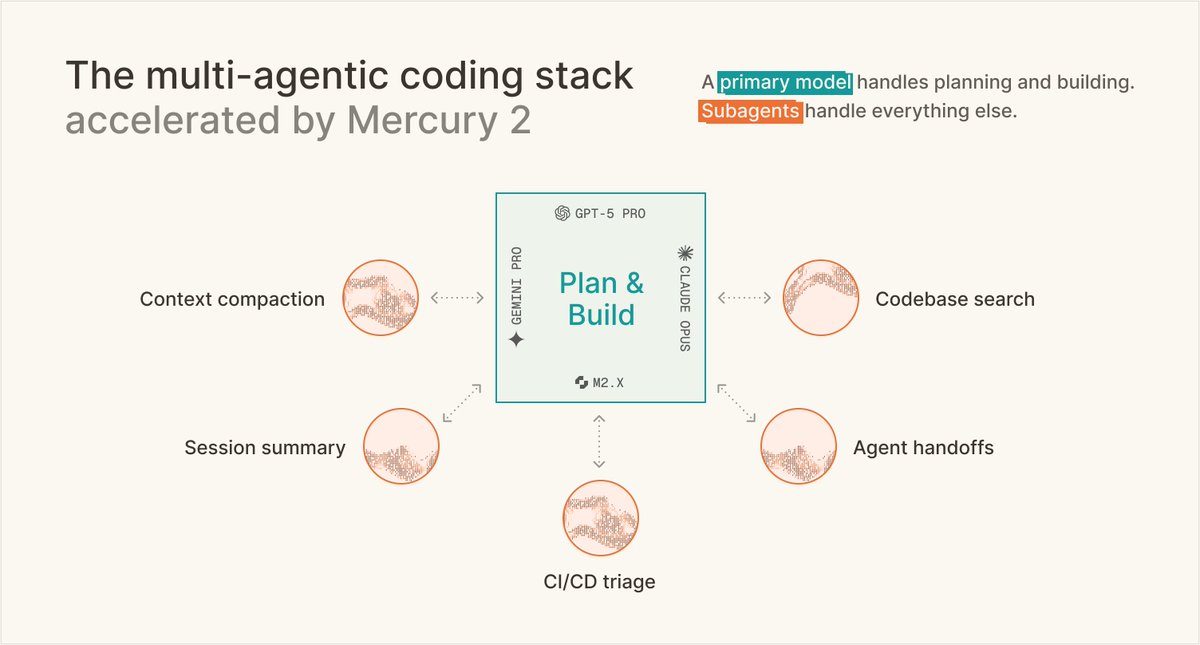
@augmentcode rebuilt their context compaction layer around Mercury 2. 82% latency cut. 90% cost cut. Comparable quality to Opus 4.7. Running in production today.
"We took a counter-intuitive bet. We decoupled summarization entirely, offloading it to Mercury 2 as a dedicated subagent. Mercury 2 is the highly efficient engine powering our most critical workflows."
-@RustagiAnkur & @jm1234567890, Members of Technical Staff at Augment Code
The subagent layer needs the most efficient model. Full methodology and eval setup in the writeup.
https://t.co/LPVTdaMjli
JAX is what a well-designed low-level machine learning framework looks like. Good design lets you deliver much greater performance with much lower effort. Bad design is the exact opposite.
Proud to be featured by Jensen Huang at GTC among the model builders pushing AI forward.
From research to production, diffusion is unlocking a new frontier of speed and efficiency in AI.
What if language models didn't have to generate one token at a time?
Our CEO @StefanoErmon joined @TBPN to break down how Mercury 2's diffusion LLM hits 1,000+ tok/s on standard NVIDIA GPUs — and why speed changes the product for coding, voice agents, and search.
JAX just feels better for multi-accelerator programming - there is a human touch.
I see a big difference is the mental model in JAX, you talk about parallelism in a model-agnostic way, while in torch I still often end up thinking through a mix of framework features, wrappers, and distributed strategies.
Is there something I am missing here?
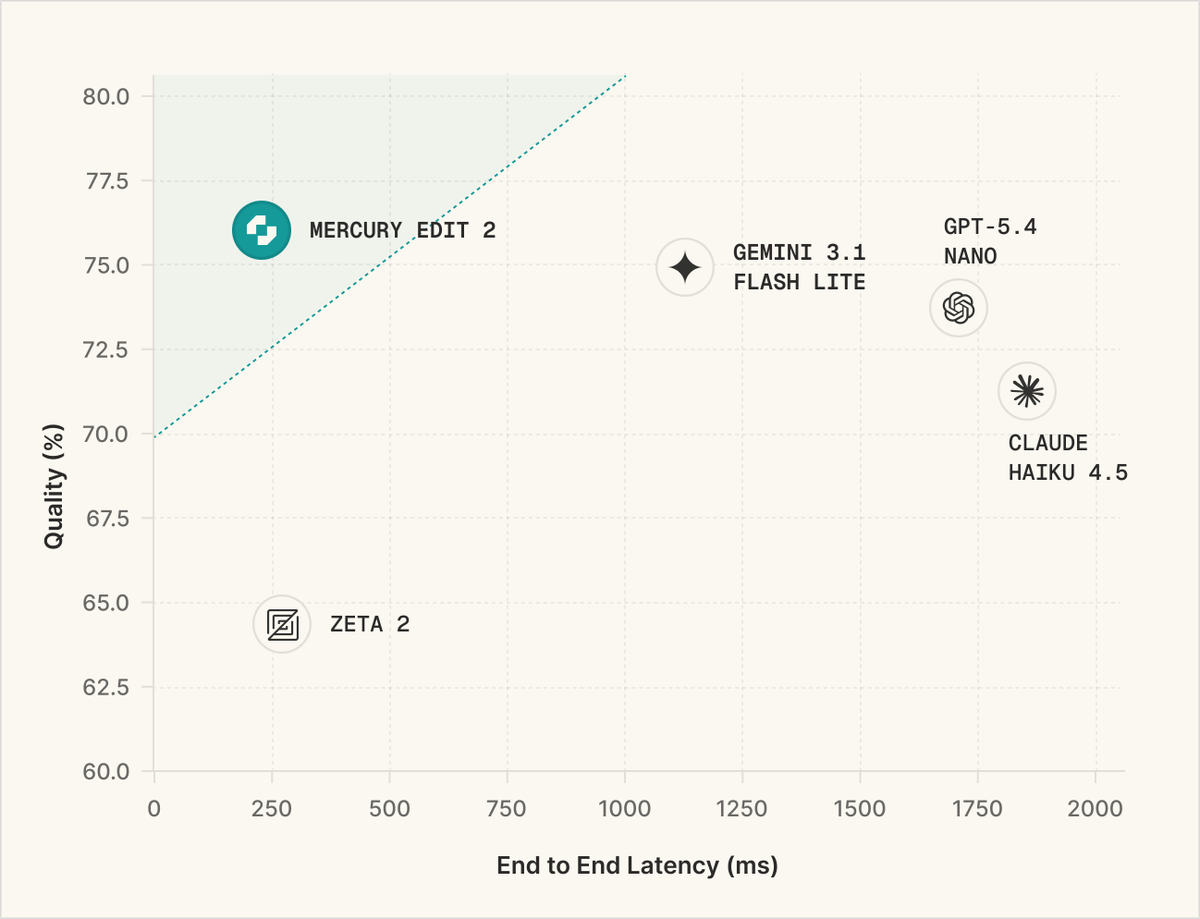
Inception Labs has launched Mercury 2, their next generation production-ready Diffusion LLM. Mercury 2 achieves >1,000 output tokens/s with significant gains in intelligence
@_inception_ai's Diffusion LLMs (“dLLMs”) use a different architecture compared to autoregressive based LLMs. The Diffusion LLM generation process starts with noise and iteratively refines the output using a transformer model that can modify multiple tokens in parallel. This allows parallelization of output token generation, allowing faster output speeds because many output tokens are generated at the same time.
Key takeaways:
➤ Amongst comparable size/price-class models, Mercury 2 performs competitively in intelligence vs. output speed. While it does not have leading intelligence, it’s output speed is more than 3X the next fastest model in this class (benchmarks based on first party endpoints or the median of providers serving the model where a first party endpoint is not available)
➤ Key strengths include agentic coding & terminal use and instruction following. Mercury 2 performs at similar level to Claude 4.5 Haiku on Terminal-Bench Hard and scores 70% on IFBench (Instruction Following), outperforming gpt-oss-120B, GPT-5.1 Codex mini, and GPT-5 nano
Inception Labs background:
This is the second release from Inception Labs. The founders were previously professors from Stanford, UCLA, and Cornell and have contributed to AI research & technologies including Flash Attention, Decision Transformers, and Direct Preference Optimization (DPO).
See below for further analysis.
Mercury 2 is live 🚀🚀
The world’s first reasoning diffusion LLM, delivering 5x faster performance than leading speed-optimized LLMs.
Watching the team turn years of research into a real product never gets old, and I’m incredibly proud of what we’ve built.
We’re just getting started on what diffusion can do for language.
Mercury 2 is live.
The world's first reasoning diffusion LLM – 5x faster than leading speed-optimized autoregressive models.
Built for production: multi-step agents without delays, voice AI with tight latency budgets, instant coding feedback.
Diffusion-based generation enables parallel refinement, not sequential tokens. Faster. More controllable. Dramatically lower inference cost.
Available today on the Inception API.
@dinabass has the story in @business.