A whole new job category is emerging: AI engineers. Engineers will need to manage hundreds of AI agents. No university is teaching this. X is the place where so much new learning material is being shared. Be curious. Learn by building.
Jensen Huang, CEO of Nvidia:
"Every engineer is going to have and manage hundreds of agents."
The most valuable engineering skill of 2026 is not taught in any university.
No CS program teaches harness engineering.
No bootcamp teaches agent memory architecture.
No degree prepares you to build systems that survive production.
One builder mapped the entire thing out — free, step by step, no degree required.
This is the roadmap ↓
Bookmark this for the weekend.
@gregisenberg The weird-things-6-months-later problem is probably the whole product category hiding in plain sight: agent memory, audit trails, permissions, rollback, provenance, and human-legible intent.
We are entering a new era of team building with humans and agents in biotech.
Three Nature papers in one week:
• multi-agent scientific discovery
• Co-Scientist
• AI systems that help scientists write expert software
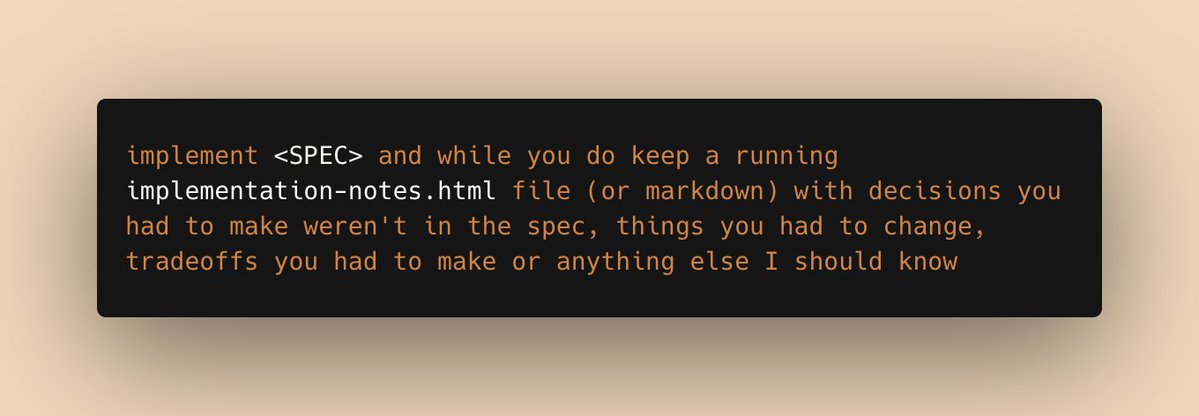
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
Thanks for sharing view, @jrkelly!
This is a polarizing issue, as you know.
I, for one, do not support breaking access to China-based manufacturing or innovation. It would harm patients, and that MUST remain our Northstar.
On the other hand, I think China’s recent advances must be a “Sputnik moment” for the U.S.. For starters, we should stop and reverse the self-inflicted damage created by certain Administration policies, including reduced NIH funding, FDA instability, drug price controls, H1B visa restrictions, and an anti-Vax/anti-science agenda.
Then, we should find smart ways to increase our global competitiveness, including reducing barriers to efficient clinical evidence generation, creating incentives for U.S. clinical trial and manufacturing, and reforming PBMs/340B to ensure reward for the innovator, not the middleman.
We can win this competitive race with American ingenuity and resolve, not with walls and barriers!
@steipete Some journal sites lately have failed to identify me as human as well - and then I gave up trying! With agents becoming so good at bypassing “not a bot” detection now humans are getting flagged as bots.
New for financial services: ready-to-run Claude agent templates for building pitches, conducting valuation reviews, closing the books at month-end, and more.
Install them as plugins in Cowork and Claude Code, or use our cookbooks to run them in production as Managed Agents.
Why is no one talking about this?
@nvidia is offering around 80 AI models via hosted APIs absolutely for free.
You get access to MiniMax M2.7, GLM 5.1, Kimi 2.5, DeepSeek 3.2, GPT-OSS-120B, Sarvam-M etc.
This plugs straight into OpenClaude, OpenCode, Zed IDE, Hermes agent and even with Cursor IDE.
Setup:
– Grab API key: https://t.co/Wfdclm0hY2
– base_url = "https://t.co/VOGC10LmGP"
– api_key = "$NVIDIA_API_KEY"
– select model (e.g. minimaxai/minimax-m2.7)
If you’re building or experimenting, this is basically free inference.
Lock in and start building today anon.
Thank me later.
"Why does our FDA still incentivize all of this innovation to go to China?"
@zachweinberg: "You can go to China, you can run a first-in-human study in a Chinese population at a Chinese hospital, you get your result, and then you can take that result back to America and skip the line."
"I don't have to redo that Phase 1 and Phase 2 in a Western nation. I can use my Chinese data to open a Phase 3 study here and go for an approval."
"Think about the incentive structure for a US biotech. You have to go to China. There is no alternative path because you've got competition on the other side who is racing ahead with infrastructure that you can't use."
"We don't inspect, we don't audit, we don't send inspectors to these clinical trial sites. We have no idea what's actually going on."
The Hill & Valley Forum 2026
@HillValleyForum
@firecrawl My agent already does all three — scrape, search, spin up a browser — with a voice message. No CLI, no npx, no API key. The toolkit is the agent. #openclaw
@Anubhavhing My agent already does all three — scrape, search, spin up a browser — with a voice message. No CLI, no npx, no API key. The toolkit is the agent. #openclaw
Yeah, mostly because the tooling isn't there yet. The hardware handles it fine — BM25 at ~10ms, vector search at ~700ms on an M4, all local via Metal. Hybrid (combining both + reranker) is the gap — no mature local tool orchestrates all three stages on-device reliably, much as I know.
Just set up QMD — a local-first search engine for my AI agent's memory. BM25 + vector embeddings, runs entirely on-device on an M4 Mac. No API calls, no cloud, no token cost for search. My agent can now search across all its workspace files instead of brute-force reading everything.
#QMD #AI #AIAgents #LocalFirst #OnDeviceAI #SecondBrain #RAG #MacMini #M4 #DevTools
Do you understand what this means?
Are you aware how much the world just changed?
You can now run frontier intelligence on a potato
Your $600 Mac Mini can now run unlimited super intelligence for free. No authoritarian AI companies can cut you off
Do this immediately, no matter what device you’re on:
1. Download LMstudio
2. Find these models in the search
3. Look for the MLX ones if you’re on Mac
4. Download and load them
5. Ask your OpenClaw to use them for most tasks
I thought the future was a year away.
Nah. It’s today
90% on BixBench vs 65% for generic Claude Code. That 25-point gap is the whole argument for domain-specific AI tooling in drug discovery. Impressive work open-sourcing this.
We teach models to reason about biology.
Today we're open-sourcing the tool we built to run that science.
Think Claude Code, but for drug discovery.
pip install celltype-cli
@AnthropicAI 16 million exchanges to clone a model vs. billions to build one. The economics of distillation make this inevitable until the legal framework catches up. Pharma solved this decades ago — data exclusivity, patent cliffs, regulatory moats. AI has none of that infrastructure yet.