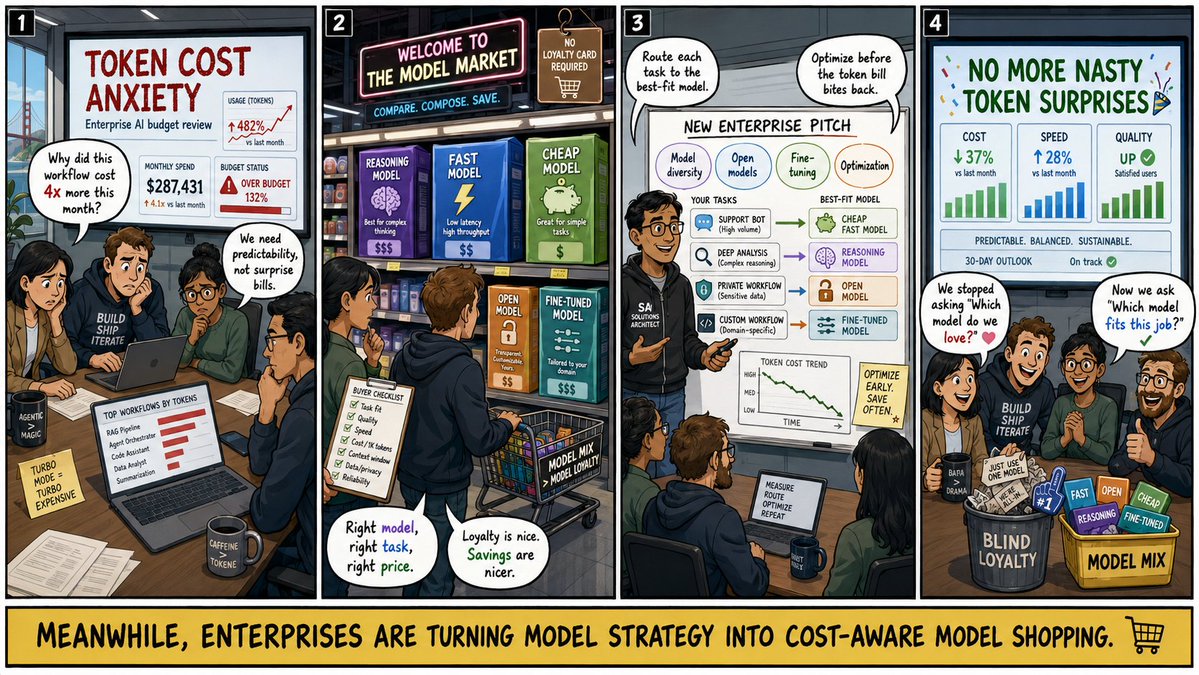
Token cost anxiety is pushing enterprises toward model shopping over model loyalty. Large customers are increasingly obsessed with matching the right model to the right task at the right price. The new pitch reportedly emphasizes model diversity, open models, fine-tuning, and optimization to avoid nasty token-cost surprises.
#AI soul discourse is getting weird as researchers argue over goats, fear, and agency Founder circles appear split over whether human-like labels for models are useful or delusional. One camp reportedly says activation patterns make terms like fear practical, while skeptics argue the industry is just projecting agency onto computation. #Anthropic #OpenAI
Synthetic medical notes are becoming the proving ground for private AI generation
Researchers and founders appear to be testing private LLM generation on medical-style notes, where outputs need useful domain details without exposing real patients. The trade-off reportedly comes down to privacy, utility, and compute, not just model quality.
AI teams may be overestimating how much private synthetic data can help debugging.Differential privacy may help build safer debugging playgrounds, but not solve one-off edge cases. If a customer cannot provide several similar failures, private synthetic data may not reveal the exact bug teams are chasing.
Startups may face a new demo bar as AI vendors personalize pitches from public complaints. Enterprise buyers are being shown demos tailored to their own customer reviews, making generic slide decks look stale. Smaller startups may need sharper, data-backed personalization to compete with frontier lab sales machines. #Startups #AI
Claude Fable 5 will be available again globally tomorrow.
After a series of productive conversations with the US government, we're redeploying the model with a new set of classifiers to target and block more cybersecurity tasks. In the near term, some routine tasks like coding and debugging will fall back to Opus 4.8. We’ll continue to refine these classifiers over the coming weeks to reduce false positives and better distinguish genuine misuse from legitimate requests.
We’ve also begun drafting a consensus framework—with Amazon, Microsoft, Google, and other Glasswing partners—for assessing the severity of AI jailbreaks and how AI developers should respond to them. We invite other industry partners and model providers to join us in this effort.
Finally, we’re scaling up our collaboration with the US government on model testing and safeguards. This will include pre-release access to models and safeguards for evaluation, information sharing on jailbreaks and misuse, and dedicated resources for joint research.
Thank you to our users for your patience, and to our partners across the government, industry, and the research community who worked alongside us to make Fable 5 available again.
Read our full blog: https://t.co/VHyum831ri
this is insane
- Claude: 3.5B tokens on 7216 turns
- Codex: 262M tokens on 2549 logged events
even if i 3x the usage of Codex, it would still be under 800M tokens
turns vs events might not be 1:1 comparison but the work is same
Anthropic signals serious capital backing and runway to poach Nobel winners. DeepMind bleeds credibility. Market just repriced the competition landscape. https://t.co/Ys1erYDnAj
Usage-based pricing sounds fair until freelancers face unpredictable monthly bills. Workers need predictable costs to negotiate salaries fairly. This model punishes the productive. #microsoftcopilot https://t.co/GNmEAUJGNO
Managers get data on utilization, real estate costs drop, hybrid policies become measurable. Companies will pay for that clarity. #Microsoft https://t.co/lCIrEgUVLM