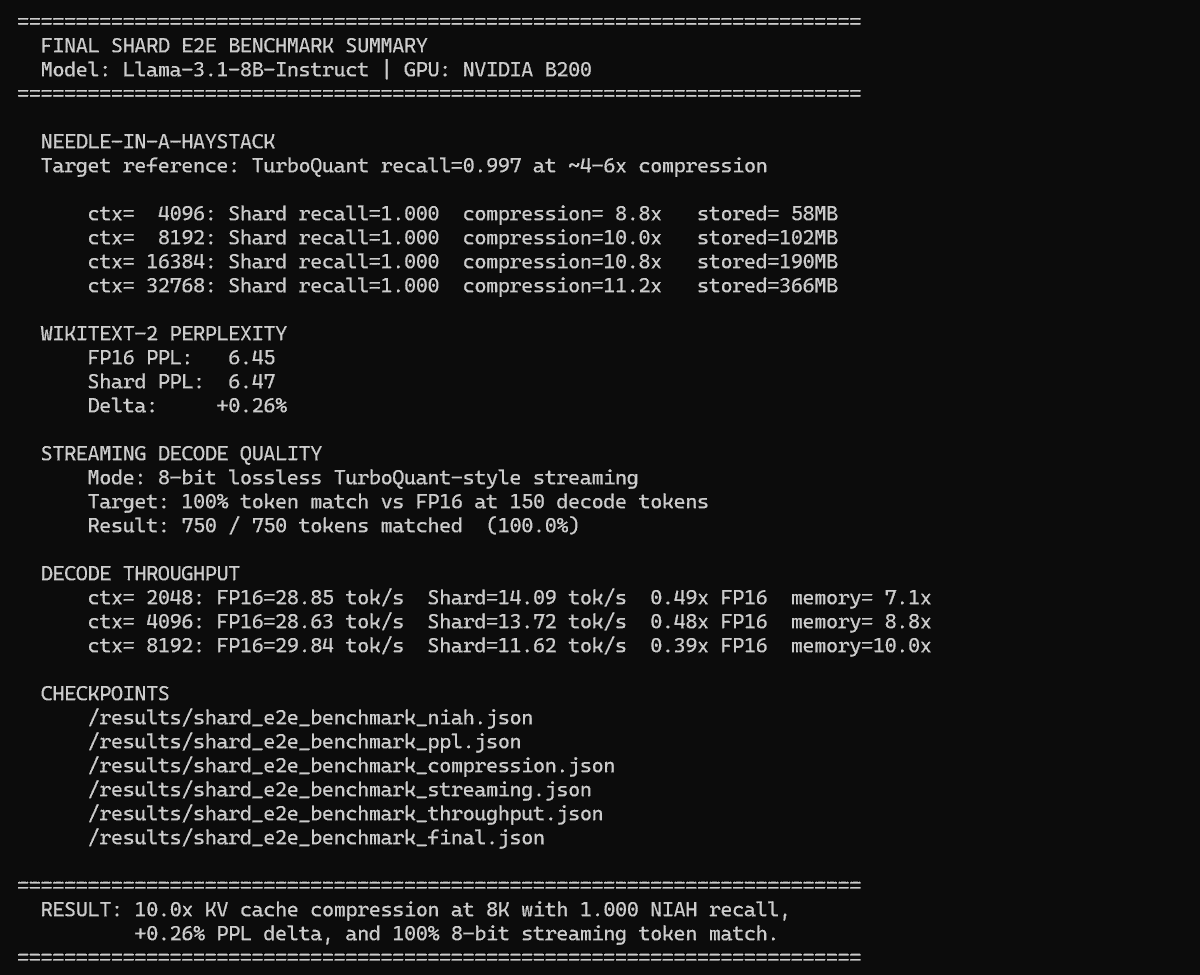
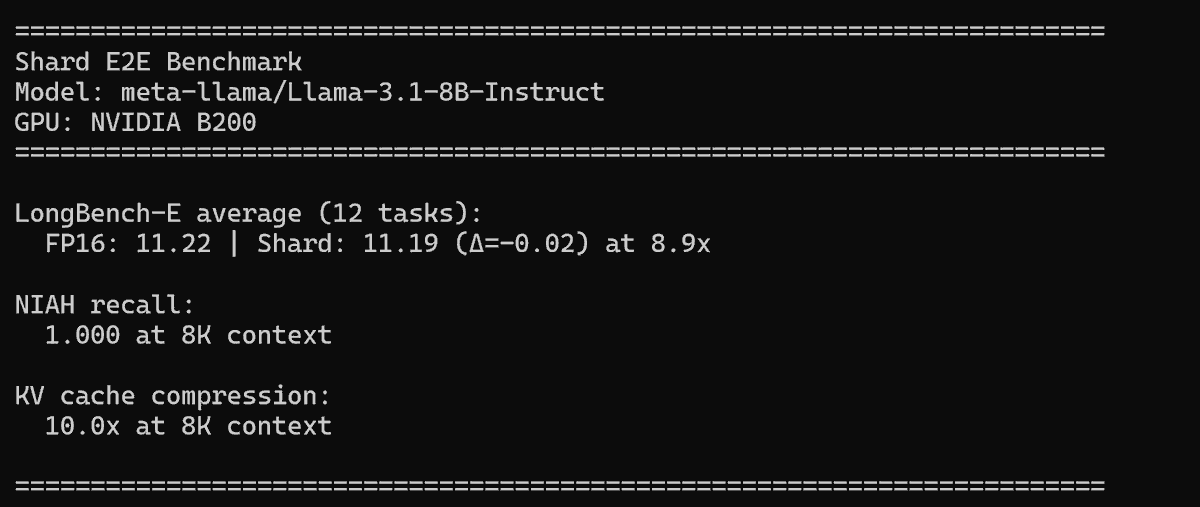
@krishgarg and I built Shard, beating @GoogleDeepMind's TurboQuant on KV cache compression.
10x compression on Llama-3.1-8B-Instruct at 8K.
NIAH recall: 1.000.
Keys: RoPE-aware PCA + int4 fused attention.
Values: Hadamard + VQ.
Same needles. Less cache.
https://t.co/y43CRsRfAj