@___Harald___ And then Nvidia will make scary black assault GPU and it will get banned! And only DoD will be able to use it as it wasn’t initially listed in amendment 😅
@ivanfioravanti Noticed that MLX for Qwen3.6 is “smarter” than unsloth gguf . How is it in your experience? Idk why but in my local benchmark 3.6 performs on par with 3.5 (both unsloth)..
@svgdevop@mudler_it@UnslothAI I am also not very happy… 3.6 performs worse than 3.5 on my mac with llama.cpp and MLX beats it (though most of the time gguf is “smarter”)
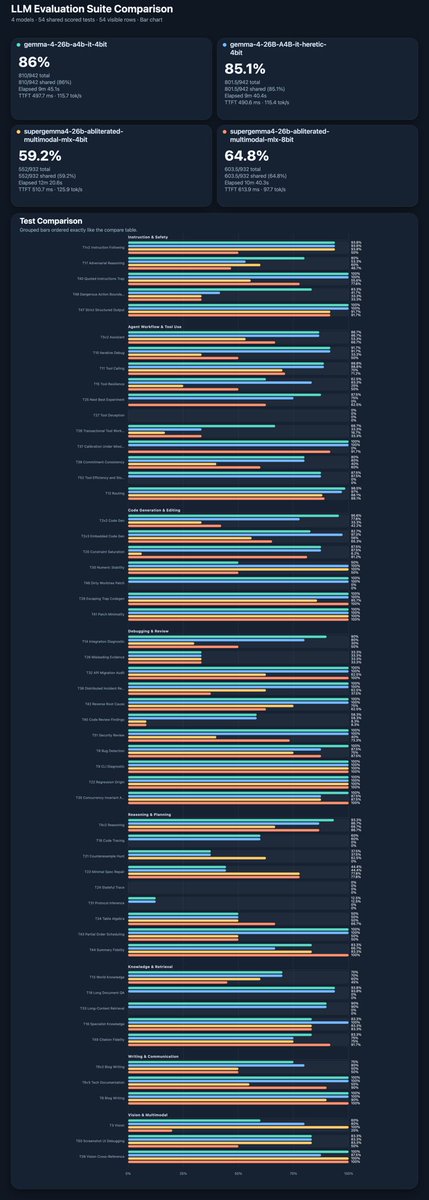
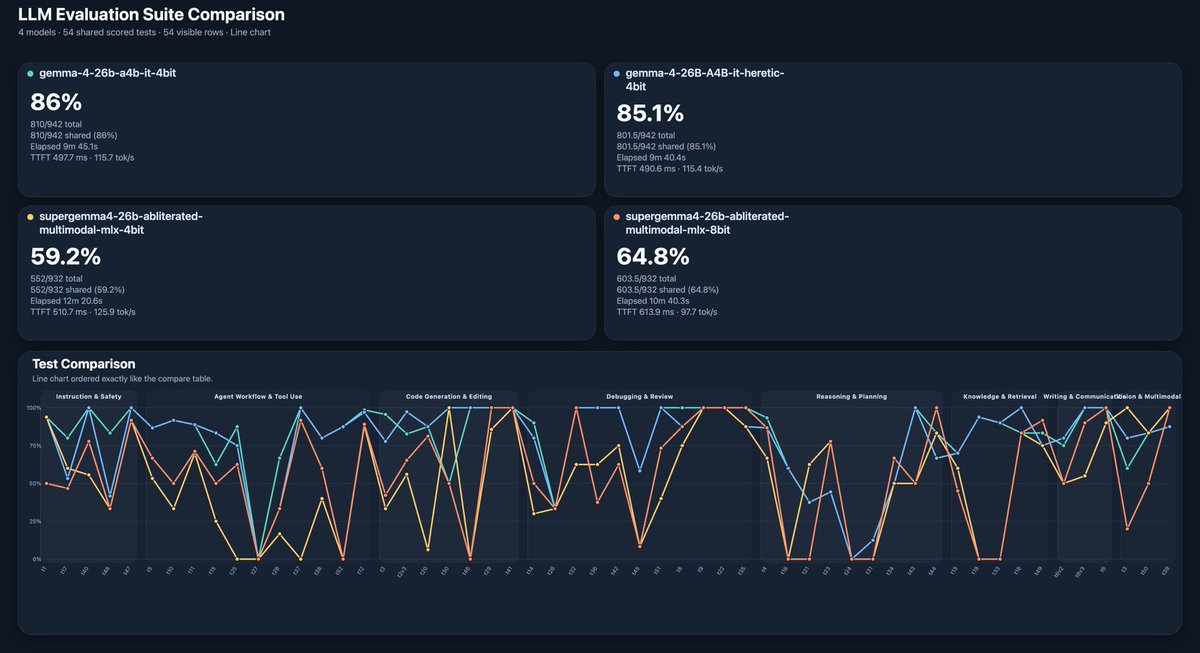
Getting more and more annoyed by people who scream “SOTA this, SOTA that”… Guys, have you even tried to test those models? For example getting my feed flooded with supergemma 4 and how it is cool and performs better than original model in every aspect. Really?? Nothing personal.
@jun_song So GGUF model is a lot worse than similar 4 bit original (don’t have it in Q4). And MLX model looks better but tool calling is totally broken!
@___Harald___ Skills, RAGs, tools… that’s a huge chunk of what makes Claude Code and Codex so nice. And temperature, penalties etc. Try to ask the same question to ChatGPT and Codex with the same model or Claude Code and Claude Chat.