I'm glad to announce that the simd-minimizers library is out!
@curious_coding and I have been optimizing the computation of minimizers down to the smallest detail.
The result is an order of magnitude faster than existing methods ; processing an entire human genome takes only 4s!
We also paid special attention to the computation of canonical minimizers, to ensure that a sequence and its reverse-complement always select the same minimizer positions. This constraint adds a 50% overhead to the running time, resulting in 6s for a human genome.
I am super excited to share our latest preprint with @yhhshby, @IgorMartayan, and Lucas Robidou on k-mer representations, introducing Hyperkmer and a novel k-mer counter, KFC!
https://t.co/OS8kmnrKJK
🧵 A thread:
The next symposium of experimental algorithms (SEA'25) is going to be in Venice 😎 Amazing invited speakers: Sebastiano Vigna, Daniel Lemire, and Giulia Bernardini! + workshop on compressed self-indexes, featuring Roberto Grossi and Giovanni Manzini!
https://t.co/PkmRuMOgqE
The open-closed mod-minimizer is officially out, with @daniel_c0deb0t and @giulio_pibiri :D
A single simple & practical & efficient scheme that is best in class for k>w (closing ~half the remaining gap to optimal), and close to the best there currently is for k<w.
1/5
This new paper is a follow up of the WABI'24 paper featuring the mod-minimizer: it introduces the "open-closed" mod-minimizer scheme. Fantastic collaboration with @curious_coding and @daniel_c0deb0t! (A bioRxiv preprint is forthcoming.)
https://t.co/pzY67pZ7tB 1/16
Features: '2+o(1)' bits per canon. k-mer for nice k-mer sets (the spectrum like property) and then linear w/the superstr. len (and no assumptions on the k-mer set structure), exact membership queries in O(k) (single) / O(1) streaming, and linear-time construction.
FroM Superstring to Indexing: a space-efficient index for unconstrained k-mer sets using the Masked Burrows-Wheeler Transform (MBWT) https://t.co/YagAm5YBz3 #biorxiv_bioinfo
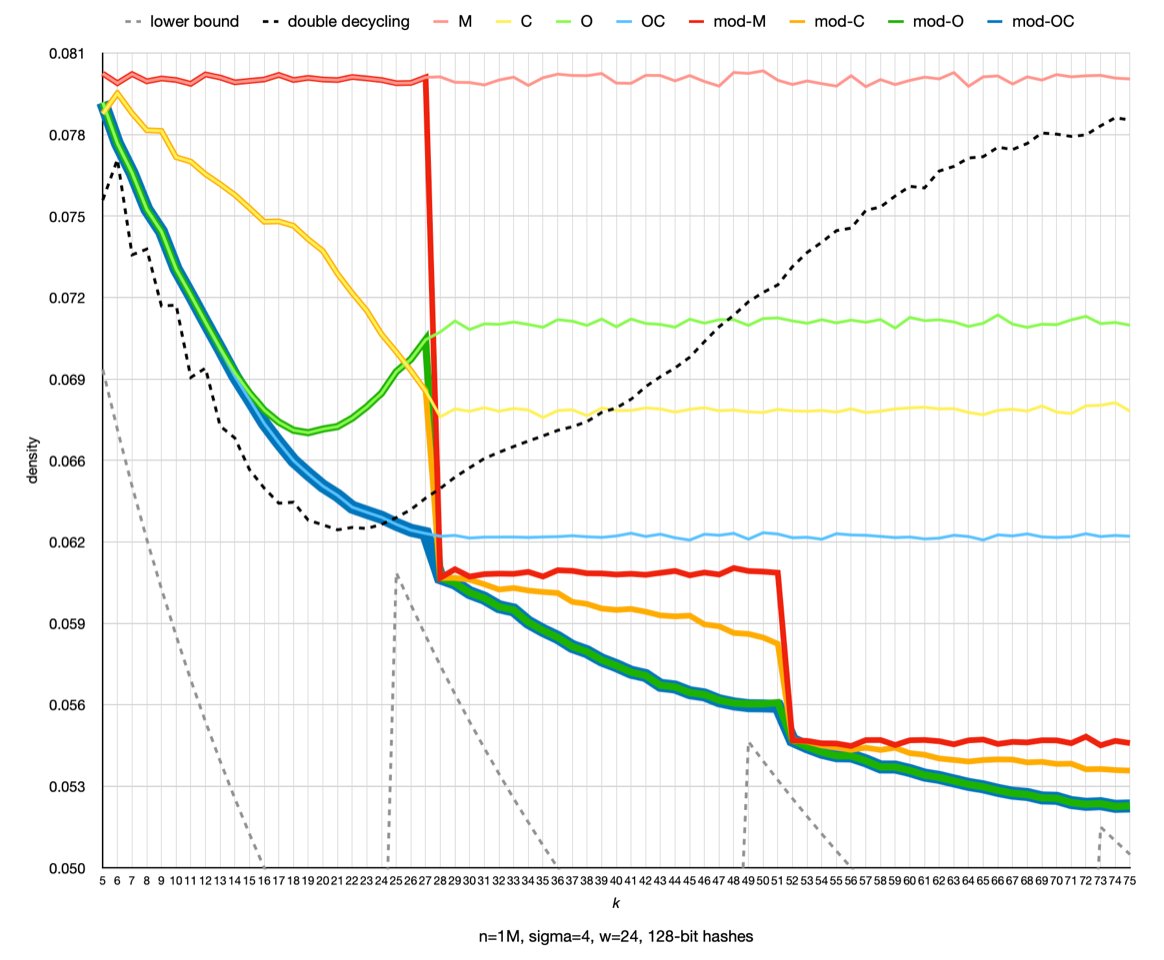
Excited to share our new method GreedyMini+ to generate DNA minimizers with low expected or particular density for practical k & w values: https://t.co/fwskO5ZTJ8. Joint work with my student Ido Tziony and my colleagues @shay_gol, @matanHakrausi, and Arseny Shur #minimizers
Results are pretty amazing! (M is classic mini; C is closed-syncmer, O is open syncmer, and OC is open+closed syncmer; the versions with the mod- are their "lifted" versions given by the mod-sampling framework.) 8/10
We had the mod-minimizer (blue) and very soon the lower bound preprint will be up (lower red function).
Iterating a bit on @daniel_c0deb0t's idea (thanks PyO3 😆), I found this new scheme (dotted red), which halves the gap towards the lower bound, and may well be near-optimal.
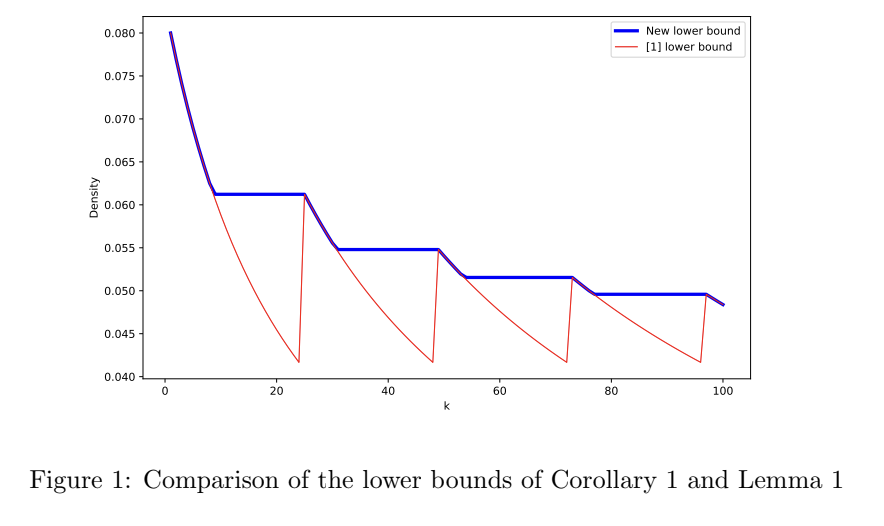
Building upon @curious_coding and @BKille's recent breakthrough in lower bounding the density of local forward selection schemes, my colleagues Golan and Kraus et al. further tightened the lower bound: https://t.co/oFiSrf91vs. What an exciting time to study selection schemes!
Allright, I think my blogpost on computing random minimizers is ready to share.
Runs in just under 0.5s for a full human genome :)
That's 60x-160x faster than some other implementations.
As part of this, there's also a 30x faster ntHash implementation.
https://t.co/9mcbyLT9cP
Check out the incredible lineup of talks at WEMSA 2024: https://t.co/j6fu7Xg14y. There is still time to submit posters by 7/20/2024 via https://t.co/Adj0iPMlAQ.