I was on the board of @ehsanik's company before Anthropic acquired it.
She is a force of nature. Brilliant. Relentless. Deeply caring.
No one should have to miss their wedding because their family is trapped in a war zone. No one should live with constant uncertainty about the safety of the people they love. No one should have to live with immigration uncertainty while giving so much to the country they call home.
Iranians have contributed enormously to America and the world. My heart goes out to them.
We're not over with scaling. The path to million chips run is clear.
You need to be distributed across many datacenters.
You need to be resilient to hardware failures.
We simulate extreme levels of hardware failures as if we were using 2M chips and show Decoupled DiLoCo can achieve the same ML performance while having superior infra robustness!
We’re introducing our eighth generation of TPUs. This time, we’re taking a dual chip approach: TPU 8t, optimized for training, and TPU 8i, optimized for inference.
💪TPU 8t achieves nearly three times the compute performance per pod over our previous generation, Ironwood.
⚡TPU 8i connects 1,152 TPUs in a single pod to deliver the massive throughput and low latency needed to concurrently run millions of agents cost-effectively.
These new TPUs are a crucial part of our fully integrated AI stack — from the chips all the way up to the models, developer tools, agents and applications. By designing the hardware and software in tandem, we’re able to deliver scale and efficiency. #GoogleCloudNext
The growing KV-cache of attention is the key component for the long-context understanding of LLMs, but what holds back long-term memory modules (e.g., Titans)? What if we could have the compression power of Titans but with a growing memory similar to Transformers?
Memory Caching: A class of architectures that compress the context into a slow growing memory (not as fast as Transformers, but not as static as RNNs), resulting in recurrent neural networks with non-fixed-sized memory (hidden states). Building on this formulation, we present Sparse Selective Caching, an architecture with growing effective memory (similar to attention) but with almost constant inference cost per token (similar to RNNs).
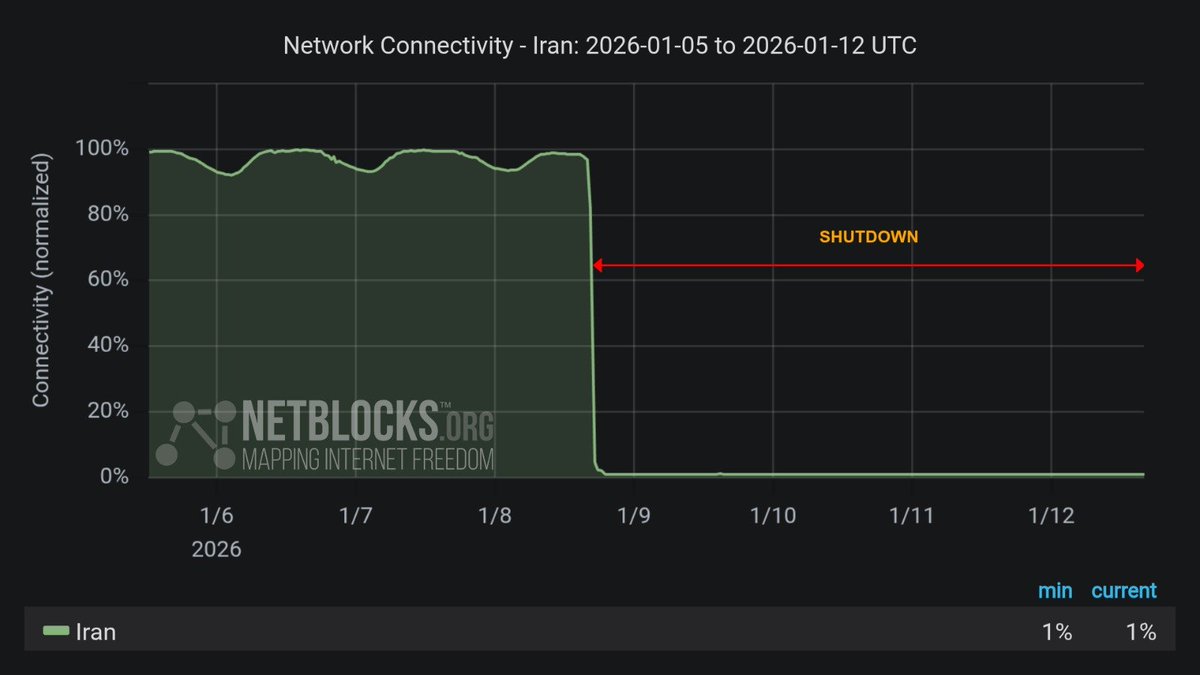
⚠️ Update: #Iran has now been offline for 96 hours, limiting reporting and accountability over civilian deaths as Iranians protest and demand change; fixed-line internet, mobile data and calls are disabled, while other communication means are also increasingly being targeted ⌛️
✅ Papercut fixed: Gemini Live is learning some better conversational manners! 2 things rolling out…
1) We've fixed the bad habit of cutting you off mid-sentence if you pause too long - that should happen less, starting on Android and then iOS in the new year
2) You'll be able to mute your mic while it's talking, so you don't accidentally interrupt it
Basically: less talking over each other, more smooth chatting on @GeminiApp :)
FishMaze writeup has been released: https://t.co/IHlS1aKAA4
It's the first ever Pallas or TPU-themed chal in a ctf AFAIK.
Check out https://t.co/vggQppBRXc to learn more about the chips that power Gemini.
If you have a cool idea & want some free flops: https://t.co/hf01EDOzLE