index365 audits your site the way an AI agent reads it, not the way a browser renders it.
Our system communicates directly with your agentic coding tool, delivering the fixes through MCP or the CLI.
Find and Fix in one loop. index365
Trump administration officials tell WIRED that if Anthropic wants to rerelease Fable 5, it will need to ensure the model's guardrails can't be circumvented. Security experts say that can't be done. https://t.co/itfeqzRgSS
What will we be getting first, GPT 5.6 or Fable 5 coming back?
Let me know if you have any good info, we are eager to see ChatGPTs newest model bc Fable 5 was amazing and what AI should be.
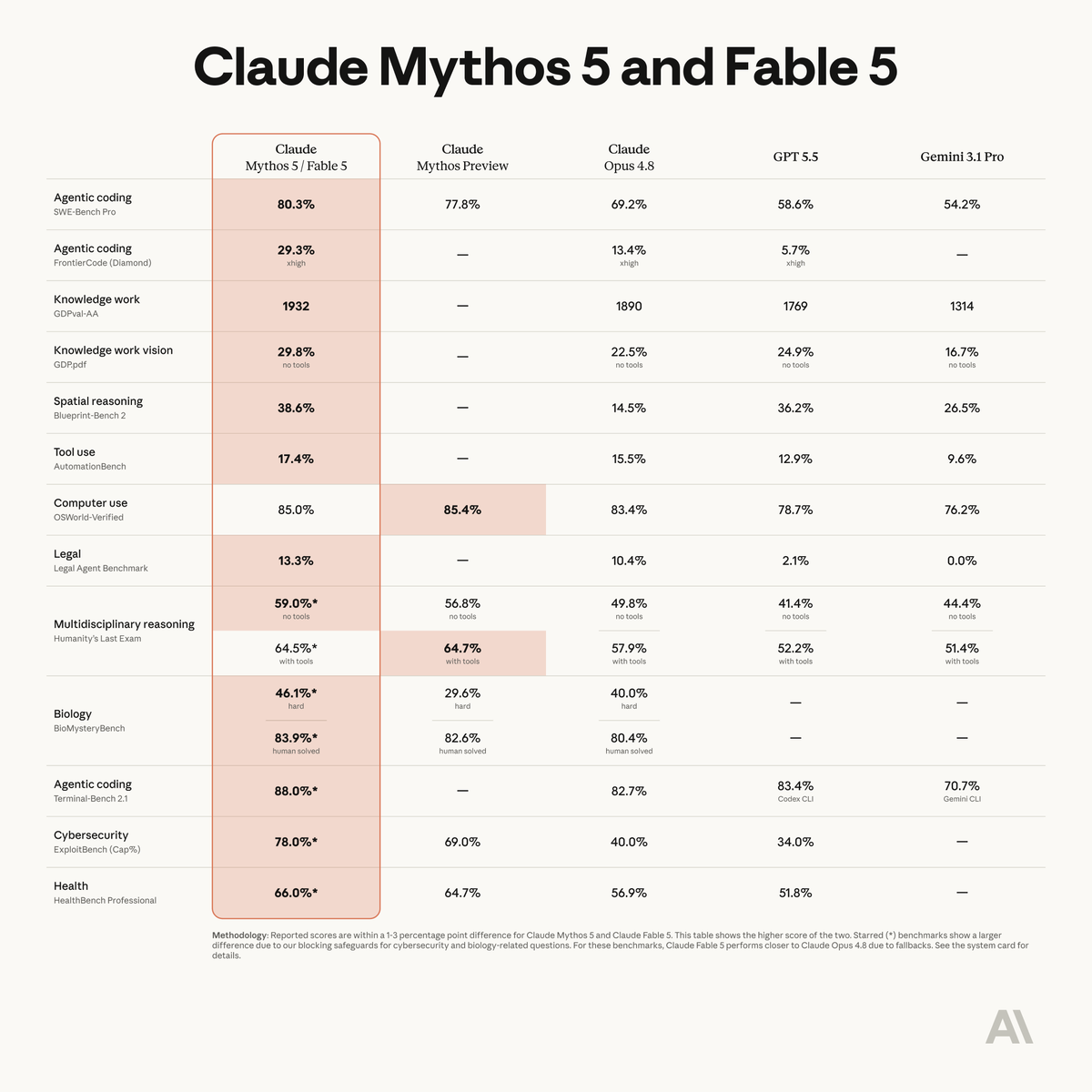
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
@charrlidon Not a bad workflow. I’ve been trying to cleanup everything in my repo prior to 2pm and than I usually run a large plan, with code update overnight. Tried Opus 4.8 last night and it surprisingly went well. 4.7 stopped way too much but 4.8 handled the task much better
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
Codex is generally a great tool for development and productivity of any kind. Also, thoroughly enjoy that its a standalone app from ChatGPT. Usage limits are also much better with Codex and the ChatGPT subscription than with Claude subscription and Claude Code.
I wonder if Anthropic will do the same with their Claude app and separate out Claude code from their Claude AI desktop app. Right now it just seems like the Claude desktop app is too cluttered and they’re trying to squeeze way too much into one platform
Based on past releases between Opus and Sonnet, Anthropic should release Claude Sonnet 4.8 soon. When do you think it’ll be released? What improvements are you looking forward to the most? Does Haiku get an update first?
Also, leave a comment with your best use cases for Haiku. I haven’t found a use case for the model yet and would like to find some valuable ways to introduce it in.
How is everyone managing memory (lessons, rules, claude/agents md files etc..) with their agent repos? Asking because I have tried several methods but have seen inconsistent results the larger the project gets.
Some ways I have improved memory so far is with obsidian, creating a script that doesn’t load every lesson and knows when to call the correct one, switching to CLIs to lessen the MCP json impact…
Im not looking to use some plugin or adding another github with skills just bloating even further.
Im looking for a way to improve the structure of the project and tool calling so that as my projects continue to grow it will easily remember all of the intricacies and provide the correct output at a higher rate.
Right now context drift is real and I have to read claude codes extraordinarily long response after every message and follow the path they take.
I haven’t seemed to nail down a system that im comfortable with for claude code, codex, or openclaw just yet! Any input would be great appreciated.
@hiarun02 Our team tested out antigravity instead of cursor and it wasn’t as feature rich and also very buggy. Cursor updates multiple times a week, I think antigravity only updated once in 2 weeks.
OpenAI went from seemingly being left in the dust by Anthropic to back in the horse race, possibly even leading atm! I have been thoroughly impressed with the Codex app, images 2.0, and GPT 5.5.
Codex and 5.5 are now a part of the daily rotation in conjunction with Claude Code. Results have been top notch!
With the new security tools releasing, we have to wonder which companies model will work the best. The security aspect brings a whole new toolset that isn’t being discussed enough. The models will have to be tuned for more technical tasks, it won’t be trained on general tasks, and since it will be trusted with security output has to be top quality.
The context window will have to be large enough so that it can ingest a large project with hopefully no quality loss as it progresses through the repo.
Does this mean that in the future we’ll see models tuned by task? Think GPT 5.5- general, GPT 5.5 - developer, etc etc and they all talk to each other.. I know we have sub-agents but when you limit the scope of a large model and train it for a specific knowledge the output is generally greater.
Either way it’ll be interesting to see where the security releases take the rest of our models or if we’ll always be in the phase of one model knows/does everything and you split tasks by sub-agent…